DDP:分布式数据并行
在本文中,我将解释我对 DDP 的理解、它相对于数据并行 (DP) 的优势、它的内部工作原理以及使用 ToyModel 的实际实现示例。
最近,在使用 OpenAI 的论文“语言模型是无监督的多任务学习者”和 Andrej Karpathy 的 YouTube 视频“让我们重现 GPT-2 (124M)”从头重现 GPT-2 LLM 时,我强烈地想要了解分布式数据并行 (DDP) 的工作原理。训练如此大的模型需要多 GPU 设置,而且由于这是我第一次尝试从头开始训练这种规模的模型,所以这个主题对我来说是全新的。
为了弥补这一知识差距,我立即阅读了 PyTorch 的 DDP 文档并系统地理解它。本文就是这段学习之旅的成果。
随着数据集和模型变得越来越大,在多个 GPU 上分配工作负载不仅有用,而且必不可少。它显著减少了训练时间,增强了可扩展性,并使训练大规模模型成为可能。PyTorch 的分布式数据并行 (DDP) 是满足这些需求的强大解决方案之一。
在本文中,我将解释我对 DDP 的理解、它相对于数据并行 (DP) 的优势、它的内部工作原理以及使用 ToyModel 的实际实现示例。
使用 Dall-E 创建的模型并行性图像
Distributed Data Parallel (DDP) 是 PyTorch 中的一个强大模块,它允许我们在多台机器上并行化我们的模型,通过在多个 GPU 上复制模型来实现分布式训练。每个进程在数据子集上训练模型的副本,并且梯度在进程之间同步以确保模型参数的一致更新。
在训练大型模型时,单个 GPU 通常缺乏有效处理任务所需的内存或计算能力。即使可以在单个 GPU 上进行训练,所需的时间也可能非常长。使用多个 GPU 可以帮助我们:
- 处理更大的模型:在 GPU 之间聚合内存以训练无法容纳在单个 GPU 内存中的模型。
- 减少训练时间:在设备之间分配计算,实现更快的迭代。
- 实现可扩展性:随着数据集大小的增加,可轻松将训练扩展到更多 GPU。
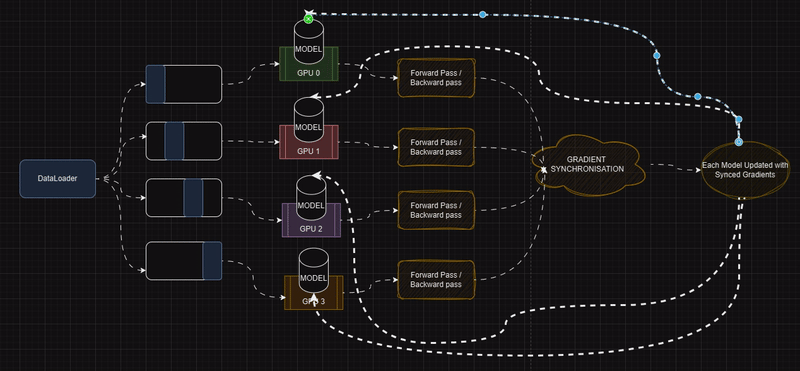
1、分布式数据并行 (DDP) vs. 数据并行 (DP)
分布式数据并行 (DDP) 在性能和灵活性方面均优于数据并行 (DP),有效解决了 DP 的局限性:
多进程架构:
- DP 是单进程和多线程的,仅在一台机器上运行。这种设计通常会导致线程之间的全局解释器锁 (GIL) 争用,从而减慢计算速度。
- DDP 使用多进程方法,其中每个 GPU 由其自己的进程管理。这消除了 GIL 争用并显著提高了训练效率,即使在单台机器上也是如此。
全局解释器锁 (GIL) 是 Python 中的一种机制,即使在多线程程序中也只允许一个线程一次执行 Python 字节码。当许多线程试图同时运行 Python 代码时,这可能会成为瓶颈。
GIL 争用发生在多个线程竞争 GIL 时,由于一次只能执行一个线程而其他线程必须等待,因此会导致延迟。
跨机器可扩展性:
- 由于 DP 仅限于单台机器,因此不适合大规模分布式训练。
- DDP 支持单机和多机设置,可在集群中的多个节点上无缝扩展大型数据集和模型。
上面的数据并行 (DP) 中的单机是指仅限于一台机器,即 DP 只能使用一台计算机上可用的 GPU。如果你的训练设置需要的 GPU 超过单台计算机可以提供的 GPU,则 DP 无法使用网络中其他机器的 GPU。
例如:
- 假设你有一个包含 4 台机器的集群,每台机器有 4 个 GPU。 DP 只能使用一台机器上的 4 个 GPU,而其他机器上的 GPU 则闲置不用。
- 另一方面,分布式数据并行 (DDP) 可以使用集群中所有机器的 GPU,使其在大规模训练中更具可扩展性。
与模型并行的兼容性:
- 当模型太大而无法放在单个 GPU 上时,模型并行用于将模型拆分到多个 GPU 上。DP 目前不支持将模型并行与数据并行相结合。
- DDP 与模型并行无缝协作。每个 DDP 进程都可以在其分配的 GPU 中利用模型并行,并且所有进程共同使用数据并行,从而实现对极大模型的高效训练。
2、分布式数据并行 (DDP) 的内部机制
分布式数据并行 (DDP) 是 PyTorch 中的一个强大框架,旨在有效地将深度学习模型的训练分布在多个 GPU 或机器上。以下是 DDP 内部运作方式的详细分步说明:
模型初始化和复制
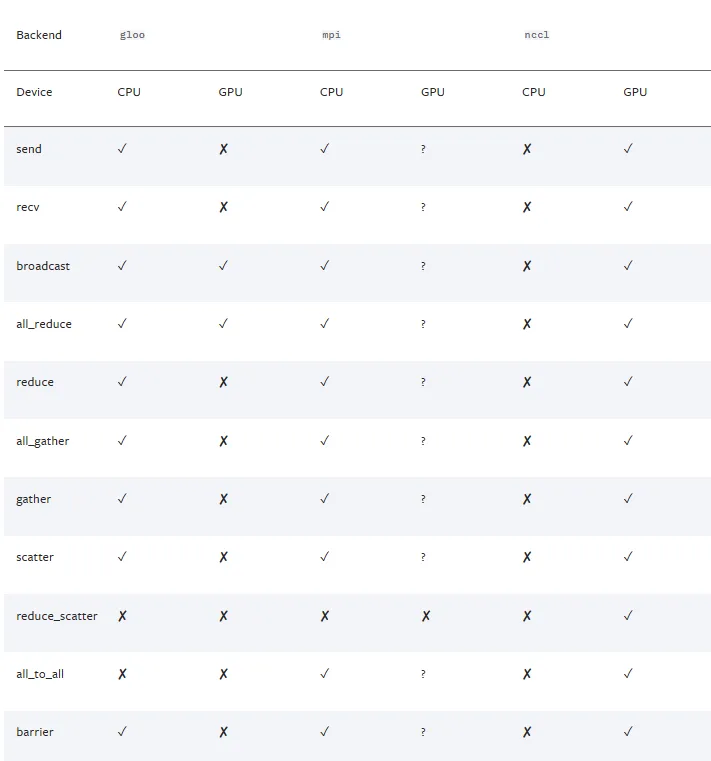
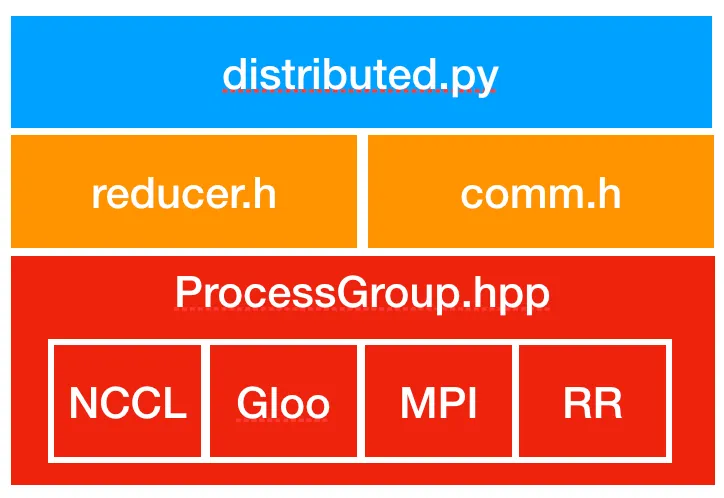
进程组设置:DDP 依赖于 c10d ProcessGroup 进行进程间通信。在构造 DDP 实例之前,必须初始化 ProcessGroup 以建立进程之间的通信。(‘gloo’、‘nccl’、‘mpi’)
- 模型广播:在初始化期间,模型的 state_dict 从等级为 0 的进程广播到所有其他进程。这可确保模型的所有副本都以相同的参数开始。
- Reducer 创建:每个 DDP 进程都会初始化一个 Reducer,负责管理梯度同步。Reducer 将梯度组织到存储桶中以优化通信。可以使用 DDP 构造函数中的 bucket_cap_mb 参数配置存储桶大小。

前向传递
- 每个 GPU 使用其模型的本地副本独立处理其小批量。
- 如果设置了 find_unused_parameters=True,DDP 会遍历自动求导图以识别不需要梯度计算的参数。这可确保 DDP 仅在反向传递期间同步活动参数的梯度。
- 注意:遍历图会带来开销,因此建议仅在必要时启用 find_unused_parameters。
反向传递和梯度同步
- 自动求导钩子:DDP 在初始化期间注册钩子以同步在反向传递期间可用的梯度。
- 桶式梯度减少:
- 梯度被分组到桶中(基于模型参数顺序)以优化通信。
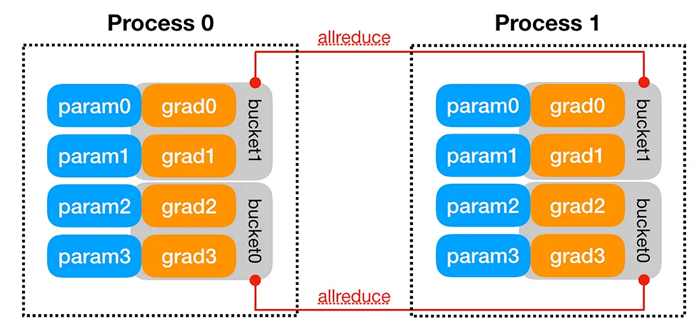
- 当桶中的所有梯度都准备就绪时,DDP 执行异步 allreduce 操作以计算所有进程的平均梯度。
- 一旦所有 allreduce 操作完成,平均梯度就会写回到相应的参数。
优化器步骤
- 同步后,优化器使用平均梯度更新每个本地模型副本的参数。
- 由于所有副本都以相同的参数开始并接收相同的梯度更新,因此它们的状态在各个进程之间保持同步。
3、使用 DDP 的玩具端到端示例
让我们来看看在 PyTorch 中使用 DDP 的一个实际示例,我显然是从 PyTorch 官方文档中获取的,就像上面的博客内容一样😅。这个玩具示例在多个 GPU 上对随机数据训练一个简单的神经网络。
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# Initializes a distributed environment for training.
# # On Windows platform, the torch.distributed package only
# supports Gloo backend, FileStore and TcpStore.
# For FileStore, set init_method parameter in init_process_group
# to a local file. Example as follow:
# init_method="file:///f:/libtmp/some_file"
# dist.init_process_group(
# "gloo",
# rank=rank,
# init_method=init_method,
# world_size=world_size)
def setup(rank, world_size):
torch.distributed.init_process_group(
backend='nccl',
rank=rank,
world_size=world_size
)
# Here we have Created a very simple Neural Network
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 1)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
# creatging the sample datset for testing
class RandomDataset(Dataset):
def __init__(self, size, length):
self.data = torch.randn(length, size)
self.labels = torch.randn(length, 1)
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index], self.labels[index]
# train loop in which setup is done
# where world_size is the number of GPUs we want to access
# and rank is the current GPU of interest
def train(rank, world_size):
setup(rank, world_size)
torch.backends.cudnn.benchmark = True # Optional performance optimization
model = SimpleModel().to(rank)
# Converting each model TO DDP object
model = DDP(model, device_ids=[rank])
dataset = RandomDataset(10, 1000)
sampler = torch.utils.data.distributed.DistributedSampler(
dataset, num_replicas=world_size, rank=rank
)
dataloader = DataLoader(dataset, batch_size=32, sampler=sampler)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(5):
sampler.set_epoch(epoch) # Ensure proper shuffling
for batch, (data, labels) in enumerate(dataloader):
data, labels = data.to(rank), labels.to(rank)
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if batch % 10 == 0 and rank == 0:
print(f"Rank {rank}, Epoch {epoch}, Batch {batch}, Loss {loss.item()}")
torch.distributed.destroy_process_group() # Graceful shutdown
if __name__ == '__main__':
world_size = torch.cuda.device_count()
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
torch.multiprocessing.spawn(train, args=(world_size,), nprocs=world_size, join=True)在上面的代码中:
设置:
- torch.distributed.init_process_group:初始化 GPU 之间的通信。
模型包装:
- DistributedDataParallel:包装模型以实现跨 GPU 的同步训练。
DataLoader:
- DistributedSampler:确保每个 GPU 获得不同的数据子集。
进程生成:
- torch.multiprocessing.spawn:启动多个进程,每个进程都与一个 GPU 绑定。
5、在模型训练中实施 DDP 的一些实际观察
如果执行 DDP 并具有自定义优化器,或者 DDP 显示与优化器相关的错误,最好将原始 nn.module 模型放在一边,以便优化器执行优化,如下面的代码片段所示。其余优化器相关代码不需要更改。
# Now after setting up DDP it is required and mandatory to wrap the model in DDP
if ddp:
model = DDP(model, device_ids = [ddp_local_rank])
raw_model = model.module if ddp else model # always contains the "raw" unwrapped model
# ========================
optimizer = raw_model.configure_optimizers(weight_decay = 0.1,
learning_rate = 6e-4,
device_type = device)确保每个 DDP 进程根据其进程排名接收唯一的训练数据子集。你可以使用以下代码作为参考,为每个 DDP 进程适当分配数据:
class DataLoaderLite:
def __init__(self, B, T, process_rank, num_process):
self.B = B
self.T = T
self.process_rank = process_rank
self.num_processes = num_process
# at init load tokens from disk and store them in memory
# with open('input.txt','r') as f:
with open(runpod_absolute_path,'r') as f:
text = f.read()
enc = tiktoken.get_encoding('gpt2')
tokens = enc.encode(text)
self.tokens = torch.tensor(tokens)
print(f"Loaded {len(self.tokens)} tokens")
print(f"1 epoch = {len(self.tokens) // (B * T)} batches")
# making changes in below code to accomodate the DDP and MultiGPU training
# data splitting
self.current_position = self.B * self.T * self.process_rank # for each process it's batch will start at rank times B times T
def next_batch(self):
# as well as makinng the changes in below code to always load the data on corresponding GPU accordingly
# and current position is advanced in such a way that it get's diffent data from every other GPU always
B, T = self.B, self.T
buf = self.tokens[self.current_position : self.current_position + B * T + 1]
# buf.to(dtype = torch.float16)
x = (buf[:-1]).view(B,T) # inputs
y = (buf[1:]).view(B,T) # targets
# advance the position in the tensor
self.current_position += B * T * self.num_processes
# if loading the next batch would be out of bounds, reset
if self.current_position + (B * T * self.num_processes + 1) > len(self.tokens):
self.current_position = self.B * self.T * self.process_rank
return x,y
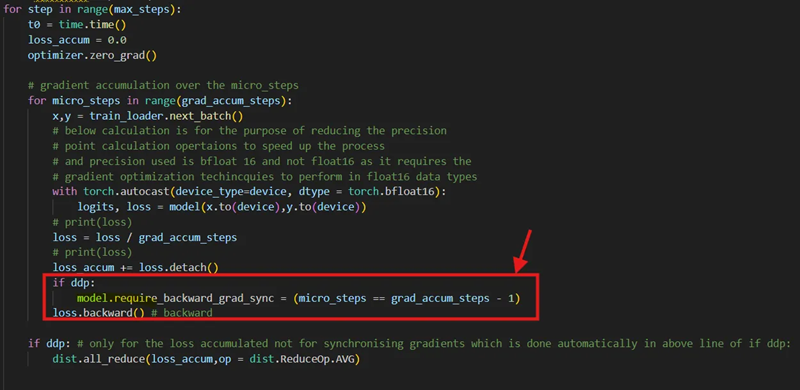
当使用梯度累积和微步来加速每个时期的训练时,你可能不希望在每个微步之后同步梯度。相反,你更愿意在完成整个累积步骤后才在所有进程中同步它们。但是,默认情况下,PyTorch DDP 会在每次 loss.backward() 调用期间同步梯度。为了解决这个问题,PyTorch DDP 提供了 no_sync() 上下文管理器。或者,你可以通过直接修改 require_backward_grad_sync 变量来实现相同的行为,如下所示:
6、结束语
分布式数据并行 (DDP) 是训练庞大模型的强大工具,尤其是当你可以访问多个 GPU 时。它简化了流程并有效地在设备之间分配工作负载。
除了 DDP,还有其他可用于训练大型模型的高级技术,包括:
- 完全分片数据并行训练 (FSDP):一种在设备之间分片模型权重和优化器状态的技术,可实现高效的内存使用。
- 张量并行 (TP):将模型的各个层拆分到多个设备,允许在层内进行并行计算。
- 管道并行 (PP):将模型划分为连续阶段,每个阶段分配给不同的设备,从而促进模型并行。
原文链接:Multi-GPU Model Training Made Easy with Distributed Data Parallel (DDP)
汇智网翻译整理,转载请标明出处
