DONUT:无需OCR的文档理解
从非结构化文档中提取数据始终是一项挑战。以前,我们曾经使用基于规则的方法来解决此类问题,现在DONUT是最先进的解决方案之一。

我们生活在大数据的世界里。人们的日常活动(例如银行业务、社交媒体、保险等)会产生大量数据。大多数情况下,这些数据以非结构化的方式存储。对此类数据进行数据分析是一项相当具有挑战性的任务。我们将讨论一种解决此类挑战性问题的最先进的技术。
从非结构化文档中提取数据始终是一项挑战。以前,我们曾经使用基于规则的方法来解决此类问题。但是,由于基于规则的机制的性质,需要外部知识来源和人力。为了解决此类问题,NLP 始终是每个人的首选解决方案。
深度学习彻底改变了 NLP 领域,此外,hugging face 始终为 NLP 中的多个问题提供最先进的解决方案。我们将讨论 SOTA 之一,称为 DONUT。
DONUT 模型是由 Geewook Kim、Teakgyu Hong、Moonbin Yim、Jeongyeon Nam、Jinyoung Park、Jinyeong Yim、Wonseok Hwang、Sangdoo Yun、Dongyoon Han 和 Seunghyun Park 在无 OCR 文档理解 Transformer (DONUT) 类别中提出的。Donut 包括一个图像 Transformer 编码器和一个自回归文本 Transformer 解码器来理解文档。它广泛用于图像分类、形式理解和视觉问答。
DONUT 提出解决以下问题。
- CORD(形式理解)
- DocVQA(文档上的视觉问答)
- RVL-DIP(文档图像分类)
在本博客中,我们将讨论文档上的视觉问答。
1、DONUT模型简介
DONUT 由基于 Transformer 的视觉编码器和文本解码器模块组成。其中,视觉编码从文档中提取相关特征,文本解码器将派生的特征转换为子词序列以生成所需的输出。DONUT 不依赖于任何 OCR 模块。
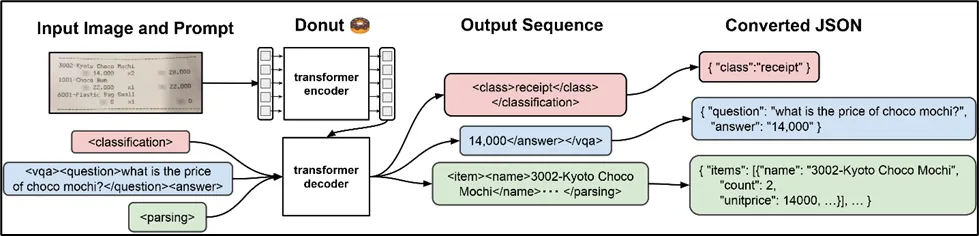
2、DONUT实践
让我们考虑一个例子来更好地理解它。

这是样本工资单文档(来源互联网)。任务是提取以下信息:
- “员工姓名”
- “总工作日”
- “最终净工资”
- “总扣除额”
一种可能的解决方案是创建一个模板并存储每个实体的边界框信息。当不存在不同的变化时,这种方法效果很好。另一种可能的方法是使用 Layoutlm 对特定任务进行微调。
DONUT 提供了一个已经预先训练好的模型,它几乎不需要微调。
a) 让我们来看看代码。我们使用了“Google colab”来方便探索。
为了加快处理速度,需要 GPU。请选择处理单元作为 GPU:
!nvidia-smib) 安装软件包:
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q datasets sentencepiecec) 加载工资单图像。也可以使用任何特定图像。
# Imports PIL module
import urllib.request
from PIL import Image
urllib.request.urlretrieve(
'https://paysliper.com/assets/templates/image/list1.jpg',
"sample.png")
image = Image.open("sample.png")d) 加载流程和模型
from transformers import DonutProcessor, VisionEncoderDecoderModel
processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")e) 使用处理器对图像进行编码
使用 DonutProcessor 为模型准备图像。
pixel_values = processor(image, return_tensors="pt").pixel_values
print(pixel_values.shape)f) 预测问题
import torch
import re
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
questions = ["what is the employee name?",
"How many working days?",
"What is the final net amount?",
"How many total deduction?",
]
task_prompt = "<s_docvqa><s_question>{user_input}</s_question><s_answer>"
for each in questions:
question = each
prompt = task_prompt.replace("{user_input}", question)
decoder_input_ids = processor.tokenizer(prompt, add_special_tokens=False, return_tensors="pt")["input_ids"]
outputs = model.generate(pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_position_embeddings,
early_stopping=True,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
num_beams=1,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
output_scores=True)
seq = processor.batch_decode(outputs.sequences)[0]
print(processor.token2json(seq))g) 输出

3、观察结果
如果我们分析结果,它看起来很酷。请记住以下几点。
- 文档图像质量应高,否则 OCR(光学字符识别)对于低分辨率图像可能不正确。
- 起草问题时请具体说明。你的问题应该包含围绕答案的关键字/短语。它将产生良好的结果。
- 它也可以从段落中提取值。如果段落中存在必填字段/数据,则围绕上下文询问特定问题会产生结果。
- 考虑这句话,“。ACP 的下一次会议定于 2022 年 11 月 28 日至 30 日举行。”
要提取答案,可以问“ACP 会议安排在什么时候?”
4、结束语
我专门用不同的图像进行了测试,结果非常惊人。请确保使用高分辨率图像。它将产生更好的结果。
请在此处查看完整代码。在后续博客中,我将分享有关自定义数据集微调的详细信息。
原文链接:Information Extraction with DONUT
汇智网翻译整理,转载请标明出处
