EasyOCR微调简明教程
你使用的 OCR 可能无法满足你的特定需求。在这种情况下,微调 OCR 引擎是可行的方法。在本教程中,我将向你展示如何微调 EasyOCR。

OCR 是一种很有用的工具,可用于从图像中提取文本。但是,你使用的 OCR 可能无法满足你的特定需求。在这种情况下,微调 OCR 引擎是可行的方法。
在本教程中,我将向你展示如何微调 EasyOCR,这是一个免费的开源 OCR 引擎,可与 Python 一起使用。
1、安装所需的依赖包
首先,让我们安装所需的 pip 软件包。我建议为此创建一个虚拟环境,但这不是必需的。
逐行运行以下命令:
pip install fire
pip install lmdb
pip install opencv-python
pip install natsort
pip install nltk你还需要从此网站安装 PyTorch(选择你的规格并复制 pip install 命令。以下命令适用于我的规格)。你可以选择 GPU 版本或 CPU 版本。区别在于,在 CPU 上运行微调过程会更慢。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
2、克隆 Git 存储库
我们需要一个 Git 存储库来运行微调。使用以下命令克隆存储库:
git clone https://github.com/clovaai/deep-text-recognition-benchmarkdeep-text-recognition-benchmark 存储库将为我们提供一些有用的文件,用于微调 EasyOCR 模型。请注意,本文中使用的一些终端命令是从存储库中获取的,然后根据我的需求进行了调整,因此该存储库值得一读。
我想在这里补充一点,Git 上的 Clova AI 有很多很好的存储库,对我有很大帮助,所以请随时查看他们拥有的其他有趣的存储库。
3、获取数据集
在微调 OCR 之前,我们需要一个数据集。你可以下载数据集或自己制作一个。
因为我希望我的 OCR 特别擅长扫描超市收据,所以我将创建一个可以在超市找到的物品的数据集,但是你可以随意使用你需要 OCR 擅长的任何数据来创建一个数据集。对于本节,我使用了此 GitHub 页面。
如果想了解如何生成自己的数据集,你可以立即转到下一部分,但如果想要更简单的解决方案,那么可以使用以下选项之一:
- 选项1- 使用我的虚拟数据集
如果你希望尽可能简化此步骤(如果只是测试,建议这样做),可以下载一个虚拟数据集。我已经制作并上传了一个到这个 Google Drive(下载整个文件夹)。
- 选项 2 – 下载数据集
如果想要更大的数据集,可以通过从这个 Dropbox 页面下载数据集下载 data_lmdb_release.zip 文件(请注意,它的大小略大于 18GB)。
4、如何生成合成数据集
如果想要一种更酷的方法来创建自己的数据集,你可以按照本节进行操作。
对于本节,你应该使用单独的 Python 文件。
合成数据集的优点在于你不需要任何劳动密集型的标记,因为你是根据提供的文本描述创建图像的。这意味着你既有模型的输入(图像),也有标签(图像的文本),这两个组件是微调 AI 模型所需的。

4.1 克隆合成生成存储库
首先,你必须克隆此合成数据生成存储库才能创建合成数据。要克隆它,请打开一个新文件夹,然后运行以下命令:
git clone https://github.com/Belval/TextRecognitionDataGenerator.git此存储库允许你根据给定的文本描述创建图像。然后,你将获得所需的数据集:图像和一个 txt 文件,其中说明图像上的文本(标签)。
4.2 创建文件以生成合成数据
现在创建一个名为 generate_synth_data.py 的新文件,并添加以下代码以导入有用的包:
from trdg.generators import (
GeneratorFromStrings,
)
from tqdm.auto import tqdm
import os
import pandas as pd
import numpy as np
import random要运行它们,你需要这些 pip 安装(在终端中一次运行一行)。请注意,需要特定的 Pillow 版本(如果你使用最新版本的 Pillow,将收到错误):
pip install trdg
pip install pandas
pip install Pillow==9.5.0接下来,定义一些超参数(将它们设置为你喜欢的任何值):
NUM_IMAGES_TO_SAVE = 10
NUM_PRICES_TO_GENERATE = 10000现在你需要一个大型数据集,其中包含你想要在创建的图像上显示的单词。由于我希望我的 OCR 能够很好地读取超市收据,因此我使用了 Openfoodfacts,这是一个包含大量超市商品的网站。
为了尽可能简单,可以使用此 Google Drive 页面上的 CSV 文件(只需下载并将其放在你的文件夹中)。
请注意,你可以使用任何其他数据,而不必使用我的数据。如果想使用自己的数据,你只需要一个字符串列表,你可以将其输入到生成器中以创建图像。
以下是如何读取包含超市商品的 CSV 文件:
# helper funcs and data to generate images
df = pd.read_csv("openfoodfacts_export_csv.csv", on_bad_lines='skip', sep='\t', low_memory=True)
df[["product_name_nb", "generic_name_nb", "brands"]]
all_words = df[["product_name_nb", "generic_name_nb", "brands"]].to_numpy().flatten()这里我加载的是我自己的数据,但如果你使用自己的数据,代码看起来会有所不同。
以下是过滤数据的方法:
# ignore np nan
num_before = len(all_words)
all_words = [x for x in all_words if str(x) != 'nan']
after_nan_filter = len(all_words)
print("removed: ", num_before - after_nan_filter, "words because of nan values")
all_words = list(set(all_words))
print("Removed", len(all_words), "duplicates")
print("Current number of words: ", len(all_words))请注意,我总是打印过滤过程中删除的单词数量。这是很好的做法,因为它可以让你更好地了解数据集的大小和质量。
我还想在图片上标明价格,因此我使用以下代码随机生成一些价格:
#randomly generate 2 digits between 0-99
number_strings = []
for i in range(len(all_words)*9//10): #90 percent of all words
digits = np.random.randint(1, 100, 4)
before_comma = f"{str(digits[0])}" #before comma is just given as 1 digit if 0-9
after_comma = f"{str(digits[1])}" if len(str(digits[1])) == 2 else f"0{str(digits[1])}"
number_string = f"{before_comma},{after_comma}"
number_strings.append(number_string)
#then create 10 percent of the words with price between 100-999
for i in range(len(all_words)*1//10): #90 percent of all words
before_comma = np.random.randint(100, 999, 1)
after_comma = np.random.randint(1, 99, 1)
after_comma = f"{str(after_comma[0])}" if len(str(after_comma[0])) == 2 else f"0{str(after_comma[0])}"
number_string = f"{str(before_comma[0])},{str(after_comma)}"
number_strings.append(number_string)以下代码将超市商品与价格随机组合:
#now given word list and number list, get all combinations
all_combinations = []
for word in tqdm(all_words):
for number in random.sample(number_strings, 20): #only need 20 prices per product for example
for num_tabs in [1]:
combined_string = word + " "*num_tabs + number
all_combinations.append(combined_string)使用之前克隆的存储库从我们创建的字符串列表中创建图像:
#generate the images
generator = GeneratorFromStrings(
random.sample(all_combinations, 10000),
# uncomment the lines below for some image augmentation options
# blur=6,
# random_blur=True,
# random_skew=True,
# skewing_angle=20,
# background_type=1,
# text_color="red",
)有很多用于生成数据的选项,你可以在此处阅读更多信息。一些示例包括:更改背景、添加模糊和添加倾斜。可以通过取消上面代码片段中的某些注释行来尝试这一点。
然后将生成器中的图像保存为特定格式:
# save images from generator
# if output folder doesnt exist, create it
if not os.path.exists('output'):
os.makedirs('output')
#if labels.txt doesnt exist, create it
if not os.path.exists('output/labels.txt'):
f = open("output/labels.txt", "w")
f.close()
#open txt file
current_index = len(os.listdir('output')) - 1 #all images minus the labels file
f = open("output/labels.txt", "a")
for counter, (img, lbl) in tqdm(enumerate(generator), total = NUM_IMAGES_TO_SAVE):
if (counter >= NUM_IMAGES_TO_SAVE):
break
# img.show()
#save pillow image
img.save(f'output/image{current_index}.png')
f.write(f'image{current_index}.png {lbl}\n')
current_index += 1
# Do something with the pillow images here.
f.close()4.3 生成合成数据
可以在终端中运行generate_synth_data.py 文件:
python generate_synth_data.py你应该会看到类似于下图的图像(输出文件夹中的文本可能有所不同):
你的图像将按照下图中的顺序排列,其中 .png 文件是你的图像,labels.txt 文件包含每幅图像中的文本。这允许你使用数据集进行微调。
恭喜,现在可以制作自己的合成数据集。由于你现在在 labels.txt 文件中同时拥有图像和该图像的文本,因此可以使用它来微调 OCR 引擎,我将在下面详细介绍。
5、将数据集转换为 LMDB 格式
LMDB 代表 Lightning 内存映射数据库管理器,本质上是一种可用于数据集训练 AI 模型的编码。
可以在 LMDB 文档中阅读更多相关信息。创建数据集后,你应该有一个包含图像的文件夹,以及 labels.txt 文件中所有图像的标签(图像中的文本)。
你的文件夹应与下图类似,并且应位于 deep-text-recognition 文件夹中:
注意:确保你的文件夹中至少有 10 张图像。如果图像较少,则在本教程后面运行训练脚本时可能会出现错误。
你必须在 deep-text-recognition-benchmark 文件夹中的 create_lmdb_dataset.py 文件中进行一些更改:
将 map_size 变量设置为较低的值 — 使用以前的值时,我遇到了磁盘内存错误。我将 map_size 的新值设置为 1073741824,如下所示:
# OLD LINE
# ...
env = lmdb.open(outputPath, map_size=1099511627776)
# ...
# NEW LINE
# ...
env = lmdb.open(outputPath, map_size=1073741824)
# ...我还遇到了 utf 编码错误,因此在打开 gtFile 时删除了 utf-8 编码。新行看起来如下:
# OLD LINE
# ...
with open(gtFile, 'r', encoding='utf-8') as data:
# ...
# NEW LINE
# ...
with open(gtFile, 'r') as data:
# ...最后,我改变了 imagePath 的读取方式:
# OLD LINE
# ...
imagePath, label = datalist[i].strip('\n').split('\t')
# ...
# NEW LINES
# ...
imagePath, label = datalist[i].strip('\n').split('.png')
imagePath += '.png'
# ...create_lmdb_dataset.py 文件看起来如下(代码来自此 Git repo,应用了上述更改):
import fire
import os
import lmdb
import cv2
import numpy as np
def checkImageIsValid(imageBin):
if imageBin is None:
return False
imageBuf = np.frombuffer(imageBin, dtype=np.uint8)
img = cv2.imdecode(imageBuf, cv2.IMREAD_GRAYSCALE)
imgH, imgW = img.shape[0], img.shape[1]
if imgH * imgW == 0:
return False
return True
def writeCache(env, cache):
with env.begin(write=True) as txn:
for k, v in cache.items():
txn.put(k, v)
def createDataset(inputPath, gtFile, outputPath, checkValid=True):
"""
Create LMDB dataset for training and evaluation.
ARGS:
inputPath : input folder path where starts imagePath
outputPath : LMDB output path
gtFile : list of image path and label
checkValid : if true, check the validity of every image
"""
os.makedirs(outputPath, exist_ok=True)
env = lmdb.open(outputPath, map_size=1073741824) #TODO Changed map size
cache = {}
cnt = 1
with open(gtFile, 'r') as data: #TODO removed utf-8 encoding here since I have norwegian letters
datalist = data.readlines()
nSamples = len(datalist)
print(nSamples)
for i in range(nSamples):
#TODO changed the way imagePath is found as well to match my usecase
imagePath, label = datalist[i].strip('\n').split('.png')
imagePath += '.png'
# imagePath, label = datalist[i].strip('\n').split('\t')
imagePath = os.path.join(inputPath, imagePath)
# # only use alphanumeric data
# if re.search('[^a-zA-Z0-9]', label):
# continue
if not os.path.exists(imagePath):
print('%s does not exist' % imagePath)
continue
with open(imagePath, 'rb') as f:
imageBin = f.read()
if checkValid:
try:
if not checkImageIsValid(imageBin):
print('%s is not a valid image' % imagePath)
continue
except:
print('error occured', i)
with open(outputPath + '/error_image_log.txt', 'a') as log:
log.write('%s-th image data occured error\n' % str(i))
continue
imageKey = 'image-%09d'.encode() % cnt
labelKey = 'label-%09d'.encode() % cnt
cache[imageKey] = imageBin
cache[labelKey] = label.encode()
if cnt % 1000 == 0:
writeCache(env, cache)
cache = {}
print('Written %d / %d' % (cnt, nSamples))
cnt += 1
nSamples = cnt-1
cache['num-samples'.encode()] = str(nSamples).encode()
writeCache(env, cache)
print('Created dataset with %d samples' % nSamples)
if __name__ == '__main__':
fire.Fire(createDataset)接下来,将文件夹移至deep-text-recognition-benchmark 文件夹(你克隆的 Git 存储库)。然后在终端中运行以下命令:
python .\create_lmdb_dataset.py <data folder name> <path to labels.txt in data folder> <output folder for your lmdb dataset>
其中:
<data folder name>是包含图像和 labels.txt 的文件夹的名称(在我的情况下为输出)<path to labels.txt>是<data folder name> + labels.txt(所以在我的情况下为 .\output\labels.tx_t_)<output folder for your lmdb dataset>是将为转换为 LMDB 格式的数据集创建的文件夹的名称(我将其命名为 .\lmbd_output)
确保在 deep-text-recognition-benchmark 文件夹中运行如下命令:
python .\create_lmdb_dataset.py .\output .\output\labels.txt .\lmbd_output
现在,应该在文件夹中有一个新文件夹,如下图所示deep-text-recognition-benchmark 文件夹。
注意:在现有文件夹上运行命令不会覆盖现有文件夹。请确保删除文件夹或为 lmdb_output 指定一个新名称(这是我挣扎了一段时间的事情,所以希望这能帮助你避免这个错误)。
6、如何检索预训练的 OCR 模型
接下来,我们需要一个预训练的 OCR 模型,以便用自己的数据集对其进行微调。为此,可以访问此 Dropbox 网站并下载 TPS-ResNet-BiLSTM-Attn.pth 模型。
将模型放在 deep-text-recognition-benchmark 文件夹中 — 我知道这看起来有点可疑,但这是 deep-text-recognition-benchmark 存储库中说明的一部分。Dropbox 不是我的,我在这里链接它是因为它在 Git repo text-recognition-benchmark 中链接。
7、运行微调
如果你在 CPU 上运行(如果您使用 GPU,则可以忽略这一点),你可能会收到一条错误消息:“RuntimeError:尝试在 CUDA 设备上反序列化对象,但 torch.cuda.is_available() 为 False”。
可以通过更改 train.py 文件中的第 85 行和第 87 行来修复此问题:
# OLD LINES
# ...
if opt.FT:
model.load_state_dict(torch.load(opt.saved_model), strict=False)
else:
model.load_state_dict(torch.load(opt.saved_model))
# ...
# NEW LINES (change to this if you are using CPU)
#
if opt.FT:
model.load_state_dict(torch.load(opt.saved_model,map_location='cpu'), strict=False)
else:
model.load_state_dict(torch.load(opt.saved_model,map_location='cpu'))
# ...在终端中使用以下命令:
python train.py --train_data lmdb_output --valid_data lmdb_output --select_data "/" --batch_ratio 1.0 --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --batch_size 2 --data_filtering_off --workers 0 --batch_max_length 80 --num_iter 10 --valInterval 5 --saved_model TPS-ResNet-BiLSTM-Attn.pth
有关该命令的一些说明:
- data_filtering_off 设置为 True(只需使用该标志,而不必为其提供变量)。我没有使用 data_filtering,因为如果启用了过滤,我将没有样本可供训练。
- Workers 设置为 0 以避免错误。我认为这与多 GPU 设置有关,deep-text-recognition-benchmark 文件夹中的 train.py 文件中也提到了这一点。
- batch_max_length 是训练数据集中任何文本的最大长度。如果你使用的是其他数据集,请随意更改此变量。确保此变量与你在数据集中使用的最长字符串一样大,否则你将收到错误。
- 对于本教程,我使用 train_data 和 valid_data 来引用同一个文件夹。实际上,我会创建一个包含训练数据集的文件夹,以及一个包含验证数据集的文件夹,然后引用它们。
- 我将 num_iter 设置为 10,以确保它有效。当然,在运行模型的实际微调时,必须将此变量设置得更高。
- saved_model 是一个可选参数。如果不设置它,将从头开始训练模型。你可能不希望这样(因为这需要大量训练),因此请将 saved_model 标志设置为从 Dropbox 下载的现有模型。
8、使用微调模型运行推理
微调模型后,需要使用它运行推理。为此,可以使用以下命令:
python demo.py --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --image_folder <path to images to test on> --saved_model <path to model to use>其中:
<path to images to test on>是一个包含您要测试的 PNG 图像的文件夹。对我来说,这是输出<path to model to use>是从微调中保存的模型的路径。对我来说,这是.\saved_models\TPS-ResNet-BiLSTM-Attn-Seed1111\best_accuracy.pth(微调将微调后的模型保存在 saved_models 文件夹中)
这是我使用的命令:
python demo.py --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --image_folder output --saved_model .\saved_models\TPS-ResNet-BiLSTM-Attn-Seed1111\best_accuracy.pth
该命令只是输出模型对 <path to images to test on>文件夹中每张图片的预测和置信度分数,因此你可以通过自己查看图片来检查模型的性能,看看模型是否做出了正确的预测。这是对模型性能的定性测试。
9、微调模型的定性测试
为了查看微调是否有效,我将通过对 10 个特定单词和数字测试原始模型与微调模型来进行性能的定性测试。
我测试的单词如下所示(垂直合并为一张图像)。我不得不通过添加倾斜和模糊的文本来使模型变得有点困难。

考虑到我希望我的 OCR 能够读取挪威超市收据,所以我添加了一些挪威语单词。
希望我的微调模型在这些单词上表现得更好,因为原始 OCR 模型不习惯看到挪威语单词。我的微调模型已经针对一些挪威语单词进行了训练。
每幅图像中的文本为:
- 图像 0 -> vanskeligheter
- 图像 1 -> uvanligheter
- 图像 2 -> skrekkeksempel
- 图像 3 -> rosenborg
原始模型(未微调)的结果:
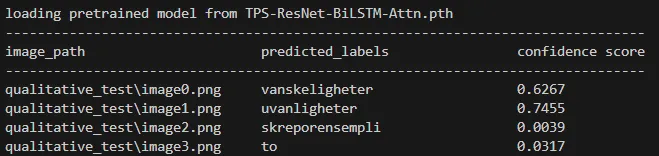
原始模型(未微调)在定性测试中的图像结果。可以看到模型相当挣扎
微调模型的结果:

可以看到模型由于微调而实现了完美的准确度。
如你所见,微调已经奏效,微调模型在此定性示例中实现了完美的结果。
10、微调模型的定量测试
如果想要进行更定量的测试,可以查看微调期间显示的验证结果,也可以使用以下命令:
python test.py --eval_data <path to test data set in lmdb format> --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --saved_model <path to model to test> --batch_max_length 70 --workers 0 --batch_size 2 --data_filtering_off
其中:
<path to test dataset in lmdb format>是包含 LMDB 格式测试数据的文件夹的路径。对我来说,这是:lmdb_norwegian_data_test<path to model to test>是要测试其性能的模型的路径。对我来说,这是:saved_models/TPS-ResNet-BiLSTM-Attn-Seed1111/best_accuracy.pth。
因此,我使用的命令是:
python test.py --eval_data lmdb_norwegian_data_test --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction Attn --saved_model saved_models/TPS-ResNet-BiLSTM-Attn-Seed1111/best_accuracy.pth --batch_max_length 70 --workers 0 --batch_size 2 --data_filtering_off
这将以百分比形式输出准确度,因此是一个介于 0 和 100 之间的数字,这是 OCR 模型在测试数据集上实现的准确度。
根据我的经验,你从 Dropbox 下载的模型需要一些训练。起初,该模型会做出不准确的预测,但如果你让它训练 30 分钟左右,你应该会开始看到一些改进。
然后,我对上面展示的 4 幅图像运行 test.py,并得到下图中的结果:旧(未微调)模型在上,新微调模型在下。
旧模型的结果:

微调模型的结果:

你可以看到,新的微调模型表现更好,准确率为 100%。
11、结束语
恭喜,你现在可以微调 OCR 模型了。要对更大的模型产生重大影响并使其泛化,你可能必须制作更大的数据集。你可以在本教程中了解这一点,然后让模型训练一段时间。
最后,希望 OCR 模型能够在你的特定用例中表现得更好。
原文链接:How to Fine-Tune EasyOCR with a Synthetic Dataset
汇智网翻译整理,转载请标明出处
