EmbeddingGemma轻量嵌入模型
EmbeddingGemma是一个小型的开源嵌入模型(3.08 亿个参数),可以直接在你的笔记本电脑、台式机甚至手机上运行。

如今,大多数 AI 工具都运行在云端。
这很好,但这也意味着两件事:你需要互联网,而且你的数据正在离开你的设备。
并不总是理想的。
EmbeddingGemma 另辟蹊径。它是一个小型的开源嵌入模型(3.08 亿个参数),可以直接在你的笔记本电脑、台式机甚至手机上运行。无需服务器,无需互联网,只有你和模型。
1、首先,什么是嵌入?
可以将嵌入视为将单词转换为数字的一种方式。它不是随机数,而是有意义的数字。
- “苹果”和“香蕉”最终靠得很近,因为它们都是水果。
- “汽车”则落在很远的地方,因为它完全是另一种东西。
这就是诀窍:嵌入让计算机“理解”单词、句子甚至整个文档之间的关系。没有它们,语义搜索或 RAG 之类的功能就无法运行。
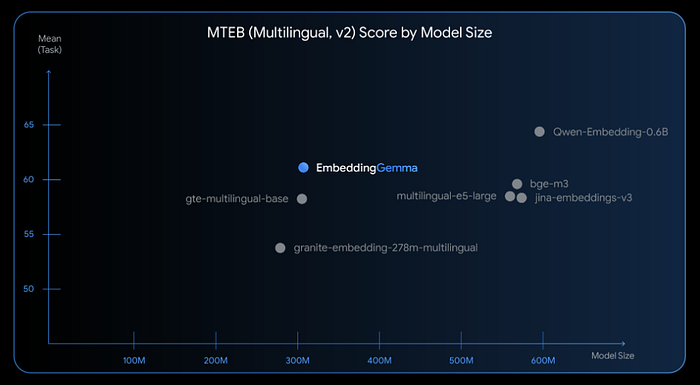
2、为什么这个模型脱颖而出
以下是人们关注 EmbeddingGemma 的原因:
- 它小巧而强大 → 5 亿参数下最佳的多语言嵌入模型。
- 离线工作 → 因此您的数据会保留在您的设备上。
- 灵活 → 根据您的需求,向量可以很大(768)或缩小(128)。
- 已支持 → 可与句子转换器、LangChain、Ollama、Weaviate 等兼容。
所以基本上,你不需要强大的 GPU 或持续的互联网连接即可使用它。
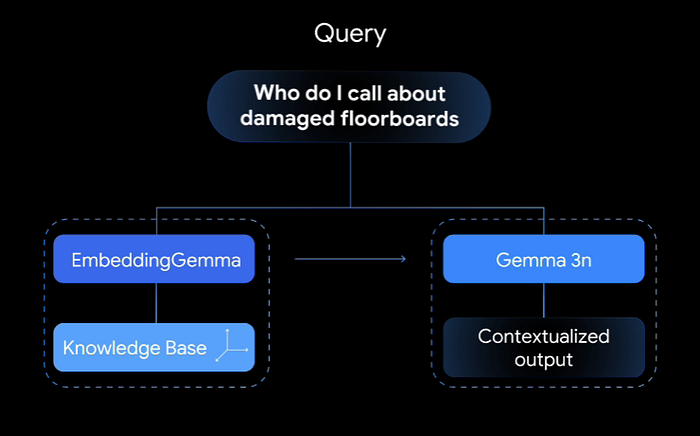
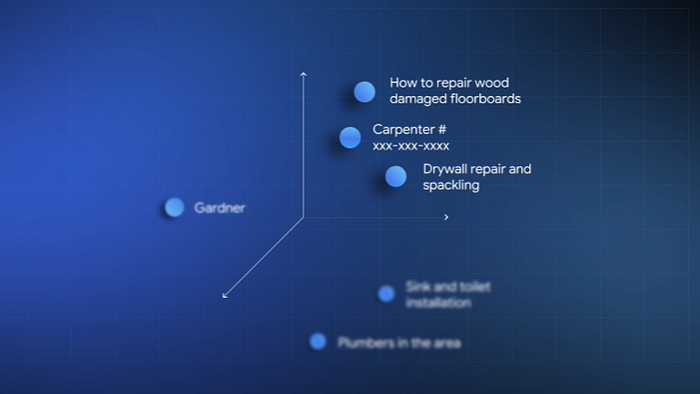
3、无需云端的 RAG
如果你玩过 RAG(检索增强生成),你就会知道流程:
- 有人提出一个问题。
- 系统会将该问题转换为嵌入。
- 它会将其与文档的嵌入进行比较。
- 找到最接近的匹配项。
- 将这些匹配项传入生成模型(例如 Gemma 3)。
如果你的嵌入质量不好,你提取了错误的文档,最终得到的答案就会崩溃。Gemma 的 Embedding 可以帮助你巩固第一步,即使是离线也能做到。
4、Python 示例
以下是如何运行它。
安装:
pip install -U sentence-transformers git+https://github.com/huggingface/transformers@v4.56.0-Embedding-Gemma-preview
同意许可协议后,您需要一个合法的 Hugging Face 令牌才能访问该模型。
# Login into Hugging Face Hub
from huggingface_hub import login
login()加载模型:
import torch
from sentence_transformers import SentenceTransformer
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "google/embeddinggemma-300M"
model = SentenceTransformer(model_id).to(device=device)
print(f"Device: {model.device}")
print(model)
print("Total number of parameters in the model:", sum([p.numel() for _, p in model.named_parameters()]))
Device: cuda:0
SentenceTransformer(
(0): Transformer({'max_seq_length': 2048, 'do_lower_case': False, 'architecture': 'Gemma3TextModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 3072, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(3): Dense({'in_features': 3072, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(4): Normalize()
)
Total number of parameters in the model: 307581696用单词测试:
words = ["apple", "banana", "car"]
# Calculate embeddings by calling model.encode()
embeddings = model.encode(words)
print(embeddings)
for idx, embedding in enumerate(embeddings):
print(f"Embedding {idx+1} (shape): {embedding.shape}")你会看到它们都是 (768,)。“Apple”和“Banana”比较接近;“Car”则偏离了另一个方向。
5、检查相似度
# The sentences to encode
sentence_high = [
"The chef prepared a delicious meal for the guests.",
"A tasty dinner was cooked by the chef for the visitors."
]
sentence_medium = [
"She is an expert in machine learning.",
"He has a deep interest in artificial intelligence."
]
sentence_low = [
"The weather in Tokyo is sunny today.",
"I need to buy groceries for the week."
]
for sentence in [sentence_high, sentence_medium, sentence_low]:
print("🙋♂️")
print(sentence)
embeddings = model.encode(sentence)
similarities = model.similarity(embeddings[0], embeddings[1])
print("`-> 🤖 score: ", similarities.numpy()[0][0])这应该会给你一个大约 0.8 的分数。非常接近——很有道理,因为两个句子表达的意思几乎相同。
6、提示让它更智能
你也可以使用提示来引导模型。例如,如果你正在处理句子相似度:
embeddings = model.encode(sentence)
print("Available tasks:")
for name, prefix in model.prompts.items():
print(f" {name}: \"{prefix}\"")
print("-"*80)
for sentence in [sentence_high, sentence_medium, sentence_low]:
print("🙋♂️")
print(sentence)
embeddings = model.encode(sentence, prompt_name="STS")
similarities = model.similarity(embeddings[0], embeddings[1])
print("`-> 🤖 score: ", similarities.numpy()[0][0])对于 RAG 流程:
- 查询 → 检索-查询
- 文档 → 检索-文档
示例:
Available tasks:
query: "task: search result | query: "
document: "title: none | text: "
BitextMining: "task: search result | query: "
Clustering: "task: clustering | query: "
Classification: "task: classification | query: "
InstructionRetrieval: "task: code retrieval | query: "
MultilabelClassification: "task: classification | query: "
PairClassification: "task: sentence similarity | query: "
Reranking: "task: search result | query: "
Retrieval: "task: search result | query: "
Retrieval-query: "task: search result | query: "
Retrieval-document: "title: none | text: "
STS: "task: sentence similarity | query: "
Summarization: "task: summarization | query: "
--------------------------------------------------------------------------------
🙋♂️
['The chef prepared a delicious meal for the guests.', 'A tasty dinner was cooked by the chef for the visitors.']
`-> 🤖 score: 0.9363755
🙋♂️
['She is an expert in machine learning.', 'He has a deep interest in artificial intelligence.']
`-> 🤖 score: 0.6425841
🙋♂️
['The weather in Tokyo is sunny today.', 'I need to buy groceries for the week.']
`-> 🤖 score: 0.385874037、为什么这很酷
您可以构建以下内容:
- 无需联网即可搜索文件或笔记。
- 无需调用 API 的私人聊天机器人。
- 手机或笔记本电脑上的轻量级 RAG 应用。
如果您需要更强大的功能,服务器端的 Gemini Embedding 始终是您的理想之选。但对于离线和隐私优先的应用,EmbeddingGemma 是一个不错的选择。
我喜欢 EmbeddingGemma 的一点是它的实用性。它并不试图成为房间里最大的模型。
原文链接:Google's EmbeddingGemma: A Lightweight, Open-Source Embedding Model You Can Run Anywhere
汇智网翻译整理,转载请标明出处
