ExtractThinker+Gemini 2.0
本文探讨 Google 的 Gemini 2.0 模型如何与 ExtractThinker结合使用,从而增强智能文档处理 (IDP)

在本文中,我们将探讨 Google 的 Gemini 2.0 模型如何与 ExtractThinker(一种旨在协调 OCR、分类、文档拆分和数据提取管道的开源框架)结合使用,从而增强智能文档处理 (IDP)。我们将介绍 Google Document AI 如何融入其中,以及 Gemini 2.0 Flash 的新功能,并通过代码示例和定价见解总结所有内容。
1、简介
智能文档处理 (IDP) 是将非结构化数据(如发票、驾驶执照和报告)转换为结构化、可操作信息的关键工作流程。虽然大型语言模型 (LLM) 现在可以直接处理图像和 PDF,但仅仅将图像输入 LLM 并希望获得完美的结果通常是不够的。相反,强大的 IDP 管道结合了:
- OCR 或其他布局提取工具(如 Google Document AI、Tesseract 或 PyPDF)。
- 分类以识别文档类型(发票、合同、许可证等)。
- 拆分以处理大型组合文件并将其分解为逻辑部分。
- 提取以将信息映射到结构化的 Pydantic 模型中 — 例如提取发票号、日期、总金额或解释图表数据。
ExtractThinker 是一个开箱即用的库,可让你将它们与 Google 全新的 Gemini 2.0 模型无缝集成。
2、Google Document AI
在深入研究基于 LLM 的提取之前,让我们先谈谈 Google Document AI。这是 Google Cloud 提供的解决方案,提供 OCR、结构解析、分类和专用域提取器(例如发票解析、W2 表格、银行对账单等)。
Document AI 提供:
- 文档 OCR 每 1,000 页 1.50 美元(每月最多 500 万页),批量越大可享受更多折扣。
- 表单解析器和自定义提取器,每 1,000 页 30 美元(每月 100 万页后有折扣)。
- 布局解析器,每 1,000 页 10 美元。
- 预训练的专用处理器(如美国驾照解析器或发票解析器),每文档或每页收费(例如,发票解析每 10 页 0.10 美元)。
使用 ExtractThinker 时,你可以附加 DocumentLoaderDocumentAI,以统一 Document AI OCR 或基于 LLM 的管道进行表单解析。协同作用非常强大:Document AI 可靠地提取文本,而 Gemini 或其他模型解释该文本(加上图像)以生成高级结构化输出。
你可以使用任何处理器,但只能使用文档 OCR 或布局解析器。文档 OCR 应与视觉配对,当视觉不可用时应使用布局解析器。如果可能的话,视觉是首选,因为它会为 LLM 提供大量背景信息,但你可以使用 Layout 来完成额外的工作。你也可以只使用 Gemini,它只会使用视觉进行读取。
提示:如果你只想使用“纯 LLM 方法”将文档读取为图像,可能会遇到幻觉或扫描精度差的问题。将 Document AI 与 LLM 相结合通常会产生更精确、更具成本效益的结果。
3、Gemini 2.0
Google 的 Gemini 2.0 是其多模态模型系列的下一个发展,支持文本、图像、音频以及高级“代理”功能。在 Gemini 2.0 中,有多个变体:
- Gemini 2.0 Flash:一种实验性但高速的模型,具有强大的 IDP 工作流性能。非常适合快速从文档中提取数据,并以低延迟大规模处理文本或图像。
- Gemini 2.0 Thinking:一种更“注重推理”的模型,它能够处理极其复杂的任务,具有更深的思路和工具使用。
可以将 Gemini 2.0 与 ExtractThinker 一起使用。Gemini 2.0 Flash 特别适合 IDP,因为:
- 它速度更快,非常适合大规模提取任务。
- 它支持多模式(图像 + 文本)输入,这对于阅读扫描的页面或图表至关重要。
- 它可以很好地处理简单的分类和结构化输出,成本低于“高阶”模型。
4、ExtractThinker:LLM 的 IDP
ExtractThinker 是一个灵活的库,它抽象了构建智能文档处理流程的复杂性。它可以帮助你:
- 通过不同的 DocumentLoader(Tesseract、PyPDF、Google Document AI、AWS Textract 等)加载文档。
- 将组合文档拆分为单独的文档(例如,将两个文档拆分为一个文档)。
- 使用多种策略和方法对每个文档进行分类
- 使用基于 Pydantic 的“合约”提取结构化数据。
以下是 ExtractThinker 通常如何处理 IDP 工作流程的高级示意图:

但首先请先安装它:
pip install extract-thinker4.1 文档加载器
下面是一个最小代码片段,展示了如何使用 Google Document AI 作为 DocumentLoader 加载 PDF:
from extract_thinker.document_loader.document_loader_google_document_ai import DocumentLoaderDocumentAI
# Initialize the DocumentLoader for Google Document AI
doc_loader = DocumentLoaderDocumentAI(
project_id="YOUR_PROJECT_ID",
location="us", # or eu
processor_id="YOUR_PROCESSOR_ID",
credentials="path/to/google_credentials.json"
)
# Now load or extract:
pdf_path = "path/to/your/bulk_documents.pdf"
# You can directly call:
pages = doc_loader.load(pdf_path)4.2 提取
定义 DocumentLoader 后,下一步就是提取结构化数据。ExtractThinker 通过基于 Pydantic 的 Contract 实现此目的 - 一种描述从文档中提取哪些字段的架构。无论你是从发票中解析行项目还是从驾驶执照中解析字段,工作流程都保持一致。
from extract_thinker import Contract
from extract_thinker import Extractor
from pydantic import Field
from typing import List
class InvoiceLineItem(Contract):
description: str = Field(description="Description of the item")
quantity: int = Field(description="Quantity of items purchased")
unit_price: float = Field(description="Price per unit")
amount: float = Field(description="Total amount for this line")
class InvoiceContract(Contract):
invoice_number: str = Field(description="Unique invoice identifier")
invoice_date: str = Field(description="Date of the invoice")
total_amount: float = Field(description="Overall total amount")
line_items: List[InvoiceLineItem] = Field(description="List of items in this invoice")然后我们继续执行 Extractor。使用 DocumentLoader 将 Gemini 2.0 Flash 指定为 LLM。可以随意更换其他加载器,例如 DocumentLoaderTesseract 或 DocumentLoaderAzureForm :
# Create Extractor & attach the loader
extractor = Extractor()
extractor.load_document_loader(doc_loader)
# Assign Gemini 2.0 Flash model for extraction
extractor.load_llm("vertex_ai/gemini-2.0-flash-exp")然后,对其进行处理以进行提取。您只需传递路径或流以及定义的合同。你还有其他可选字段,例如 vision,如果是 vision 模型,它会将页面转换为要在模型内部使用的图像。
extracted_invoice = extractor.extract(
source=test_file_path,
response_model=InvoiceContract,
vision=False
)
# Access the structured data
print("Invoice Number:", extracted_invoice.invoice_number)
print("Invoice Date:", extracted_invoice.invoice_date)
print("Total Amount:", extracted_invoice.total_amount)
for item in extracted_invoice.line_items:
print(f"Item {item.description}: x{item.quantity} at ${item.unit_price} each.")4.3 分类
假设我们想将文档分类为“车辆登记”或“驾驶执照”。我们可以为每种类型定义基于 Pydantic 的合同,并将它们映射到 ExtractThinker 中的分类对象。像 Gemini 2.0 Flash 这样的快速模型可以处理大多数文档,但如果其置信度低于阈值,我们可以升级到更强大且更慢的 Gemini 2.0 Thinking。ExtractThinker 的多层方法可以自动化这种回退逻辑,在成本效率和稳健准确性之间取得平衡。
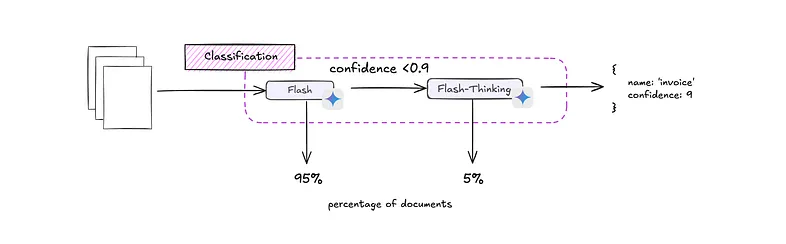
下面是一个简化的图示,其中包含两个分类对象:一个用于“驾驶执照”,另一个用于“车辆登记”, 你可以类似地定义“发票”、“信用票据”等。
from extract_thinker.models.classification import Classification
from tests.models.driver_license import DriverLicense
from tests.models.vehicle_registration import VehicleRegistration
driver_license_class = Classification(
name="Driver License",
description="A document representing a driver's license",
contract=DriverLicense
)
vehicle_registration_class = Classification(
name="Vehicle Registration",
description="Official document registering a vehicle ownership",
contract=VehicleRegistration
)
my_classifications = [driver_license_class, vehicle_registration_class]为了实现后备方法,我们设置了两个 Extractor 实例 — 一个由 Gemini 2.0 Flash(快速)提供支持,另一个由 Gemini 2.0 Thinking(后备)提供支持。每个提取器都与一个可读取 PDF 或图像的 DocumentLoader 相关联,例如 DocumentLoaderPyPdf。
from extract_thinker import Extractor
from extract_thinker.document_loader.document_loader_pypdf import DocumentLoaderPyPdf
from extract_thinker.process import Process, ClassificationStrategy
from extract_thinker.models.classification import Classification
# 1. Define your DocumentLoader
pdf_loader = DocumentLoaderPyPdf()
# 2. Create two Extractors: fast & fallback
flash_extractor = Extractor(pdf_loader)
flash_extractor.load_llm("vertex_ai/gemini-2.0-flash-exp")
thinking_extractor = Extractor(pdf_loader)
thinking_extractor.load_llm("vertex_ai/gemini-2.0-thinking-exp")
# 3. Define Classifications (e.g. "Vehicle Registration" & "Driver License")
vehicle_registration = Classification(name="Vehicle Registration", description="...")
driver_license = Classification(name="Driver License", description="...")
my_classifications = [vehicle_registration, driver_license]
# 4. Build a Process and add both extractors in separate layers
process = Process()
process.add_classify_extractor([
[flash_extractor], # Layer 1
[thinking_extractor] # Layer 2 (fallback)
])
# 5. Perform classification with CONSENSUS_WITH_THRESHOLD at 0.9
pdf_path = "path/to/document.pdf"
result = process.classify(
pdf_path,
my_classifications,
strategy=ClassificationStrategy.CONSENSUS_WITH_THRESHOLD,
threshold=9, # i.e., 0.9 confidence,
image=False # if vision is allowed, you can add it in the classification
)
print("Classified as:", result.name)
print("Confidence:", result.confidence)4.4 使用拆分器拆分文档
许多 IDP 工作流程涉及多页 PDF 或混合文档集。例如,一个文件可能同时包含发票和驾驶执照。ExtractThinker 提供拆分策略来自动分割文档。两种主要策略是:
- EAGER:一次处理整个文件,预先确定所有拆分点。
- LAZY:逐步比较页面,决定在哪里拆分。
下面,我们用一个假设的 PDF 演示了 EAGER 拆分,该 PDF 结合了不同的形式:
from extract_thinker.process import Process
from extract_thinker.splitter import SplittingStrategy
from extract_thinker.image_splitter import ImageSplitter
# 1. Prepare a Process
process = Process()
# 2. Assign a DocumentLoader (e.g., Tesseract, PyPdf, etc.) or an Extractor later
# Here we do it at the extractor level or process level:
# process.load_document_loader(my_loader)
# 3. Specify which Splitter to use
image_splitter = ImageSplitter(model="vertex_ai/gemini-2.0-flash-exp")
process.load_splitter(image_splitter)
# 4. Provide classifications—like "Invoice" vs "Driver License"
# (already defined as my_classifications or from a tree)在运行时, EAGER 拆分将扫描整个文档,检测逻辑边界(基于内容差异),并创建较小的“子文档”,然后可以对每个子文档进行分类和提取。
要将它们放在一起,你需要:
- 一个过程(带有已加载的拆分器)。
- 用于识别每个页面的分类。
- 已分配提取器或 LLM。
你可以在一次链式调用中加载文件、拆分文件并提取所有内容:
from extract_thinker.models.splitting_strategy import SplittingStrategy
BULK_DOC_PATH = "path/to/combined_documents.pdf"
result = process.load_file(BULK_DOC_PATH)
.split(my_classifications, strategy=SplittingStrategy.EAGER)
.extract(vision=True)
# 'result' is a list of extracted objects, each matching a classification's contract
for doc_content in result:
print(f"Extracted document type: {type(doc_content).__name__}")
print(doc_content.json(indent=2))load_file(...): 加载组合 PDF。split(...): 使用 EAGER 策略对内容进行分段,由 Splitter 模型和你的分类指导。extract(...):调用你选择的 LLM 将每个拆分块解析为结构化的 Pydantic 模型。
这种方法可以有效地处理大型或多文档输入,确保每个子文档都得到正确分类,然后用最少的额外代码提取。
在这个例子中,我们使用 ImageSplitter,但就 Flash-Thinking 而言,目前不支持图像。你可以改用 TextSplitter。
Document AI Splitter vs. ExtractThinker
Google Document AI 还提供了一个 Splitter 处理器,它可以识别子文档边界并为每个片段分配一个置信度分数。它输出结构化的 JSON(列出页面范围、分类标签等的实体)。但是,它有明显的限制——例如,不支持拆分大型(超过 30 页)逻辑文档,并且拆分器只会在页面边界处拆分文档,而不会真正为你拆分 PDF。
相比之下,ExtractThinker 的方法:
- 没有严格的页面限制——它可以通过分块或增量策略(例如惰性)分析任意长的文件。
- 集成分类逻辑——拆分决策可以由 LLM 洞察(例如 Gemini 2.0)而不是固定的页面级启发式方法驱动。
- 执行整个管道——在单个工作流中进行提取、分类和拆分,使用回退逻辑和用于结构化数据的高级基于 Pydantic 的合同。
简而言之,虽然 Document AI 的拆分器适用于较简单的情况(特别是如果你想要一个用于较短文档的开箱即用的处理器),但 ExtractThinker 的拆分器更加灵活,可以统一高级分类或多层 LLM 逻辑——一种用于大规模、复杂 IDP 管道的一体化方法。
5、价格比较
虽然谷歌尚未正式公布 Gemini 2.0 定价,但 Gemini 1.5 模型可以作为参考。在大多数公开预览中,适用以下费率:
- 输入令牌:每 100 万个令牌 0.075 美元
- 输出令牌:每 100 万个令牌 0.30 美元
例如,如果你发送 800 个文本令牌(提示)并收到 500 个令牌(模型响应),则总共需要 1,300 个令牌:

总费用 = 每页 0.00021 美元。
注意:输出令牌比输入令牌贵 4 倍。Gemini 的实际价格2.0 可能因地区、层级或 Google 的新公告而异。
6、选择Document AI 或 OCR
根据你的需求,可以将 Gemini 与以下产品配对:
Tesseract 或其他 OCR:
- 费用:通常为 0.00 美元(开源)。
- 如果与约 1,300 个令牌的 LLM 请求相结合,你的每页总费用仍约为 0.0002 美元 - 对于大批量来说非常便宜
Document AI OCR 或布局:
- 总计可能为每页 0.0017 美元 - 0.0102 美元,具体取决于文档 AI 处理器。
文档 AI 专用解析器(例如,布局):
- 每 10 页约 0.10 美元(0.01 美元/页),如果内置字段足够,则不需要 LLM。
- 如果你仍需要 LLM 来处理额外字段或验证,请每页添加 0.0002 美元(Gemini 令牌)。
- 每页总计约 0.0102 美元。
即使是较低级别的 Document AI 计划,Google 的 OCR 也是最先进的,尤其是对于质量较差的扫描或手写。如果你的文档是简单的图像(例如,键入的文本,对比度好),免费的 OCR 加上 Gemini 令牌可以节省大量成本——每页 0.0002 美元与 0.01 美元在规模上相差约 50 倍。
对于许多用例,具有开源 OCR 或直接 LLM 视觉的 ExtractThinker 是最具成本效益的解决方案,同时仍允许你在需要时结合 Document AI 的高级 OCR 来处理签名或具有挑战性的扫描。
7、结束语
通过将 ExtractThinker 与 Gemini 2.0 模型相结合,你可以构建一个全面的 IDP 工作流程,优雅地平衡速度、成本和准确性。文档加载(通过 DocumentLoader)、分类(如果置信度低,则使用后备层)、提取(使用基于 Pydantic 的合同)和拆分都集中在一个简化的系统中。
无论你处理的是扫描的发票、许可证、多页 PDF 还是其他文档类型,ExtractThinker 都可以在文档智能世界中为你提供支持!
原文链接:Extract any Document with Gemini 2.0 | Document Intelligence with ExtractThinker
汇智网翻译整理,转载请标明出处
