Farmer.chat:农业聊天机器人
全球约有 5 亿小农户:他们在全球粮食安全中发挥着关键作用。及时获取准确信息对于这些农民做出明智决策和提高产量至关重要。
“农业推广服务”为农民提供农业技术建议,并为他们提供必要的投入和服务以支持他们的农业生产。
仅在印度就有 30 万名农业推广人员,他们提供有关改进农业实践的必要信息,并帮助小农户做出决策。
但是,尽管推广人员的数量令人印象深刻,但数量不足以满足所有需求:他们与农民的互动比例通常为 1:1000。通过伙伴关系和技术接触农业推广人员和农民仍然是关键。
进入 GAIA 项目,这是一项由 CGIAR 率先发起的合作计划。
它通过专家支持计划将 Hugging Face 作为导师,并将 Digital Green 作为项目合作伙伴聚集在一起。
GAIA 有一个崇高的目标,那就是将多年的农业知识以研究论文的形式带到农民手中,这些研究论文在 GARDIAN 门户网站上精心维护。有近 46000 篇研究论文和报告,涵盖了数十年来全球不同作物的农业知识。
Digital Green 立即看到了开发由检索增强生成 (RAG) 驱动的智能聊天机器人的潜力,这些聊天机器人基于经过批准的精选信息。因此,他们决定开发 Farmer.chat,这是一个聊天机器人,它利用大型语言模型 (LLM) 的功能,为农民和一线推广人员提供个性化和可靠的农业建议。
为各种语言、地域、作物和用例创建这样的聊天机器人是一个巨大的挑战:传播的信息必须与农场的当地细节相关,使用农民可以理解的语言和语气,并且准确(基于可靠的来源),以便农民采取行动。为了评估系统的性能,CGIAR 团队和 HF 专家合作建立了一个强大的评估套件,即 LLM-as-a-judge 系统。
让我们看看他们是如何应对这一挑战的!
1、系统架构
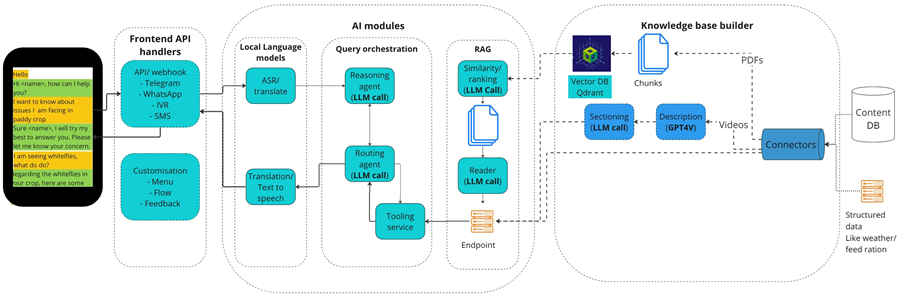
整个系统使用许多组件来提供基于多种工具和外部知识的聊天机器人答案。它有几个关键要素:
a)知识库:
- 预处理:第一步是借助 Scio 维护的 API 将 pdf 文档导入 Farmer.chat 管道。在知识库中,主题会根据相关地理区域自动分类,并在语义上分组在一起。
- 语义分块:对具有元数据的组织文件进行处理,将含义相似的句子分组为文本块。该函数目前使用小文本嵌入来实现余弦相似性
- 转换为 VectorDB 格式:使用嵌入模型将每个文本块转换为向量表示,使用嵌入模型将向量表示存储在 QdrantDB 中。
b)RAG 管道:它确保传递的信息以内容为基础,而不是外部。它由两部分组成:
- 信息检索:在知识库中搜索与用户查询匹配的相关信息。这涉及调用知识库构建器中创建的向量数据库 API 以获取必要的文本块。
- 生成:使用文本块中检索到的信息和用户查询,生成器调用 LLM 并生成类似人类的响应以满足用户的需求。
c)面向用户的代理:规划代理在后台利用 GPT-4o。
- 它的任务是了解用户意图,根据用户意图和工具描述决定需要哪些更多信息,向用户询问该信息,直到询问清楚。
- 询问清楚后,调用执行代理
- 从执行代理获取响应并生成响应
- 代理运行基于 ReAct 的提示,以逐步思考并调用相应的工具并分析响应。 然后它可以利用其工具来回答: 目前,代理使用以下一组工具:更多对话、RAG QA 端点、视频检索端点、天气端点、作物表
现在这个系统有许多活动部件,每个部件都对性能的某些方面产生根本性的影响。因此,我们需要谨慎地进行绩效评估。
在过去的一年中,Farmer.chat 的使用量已增长到为超过 2 万名农民提供服务,处理超过 34 万个查询。我们如何评估这个规模的系统性能?
在每周的头脑风暴会议中,Hugging Face 暗示 LLM 可以担任评委,并提供了他们LLM 担任评委的笔记本链接。该资源进行了详细讨论,随后成为一种有助于指导 Farmer.chat 发展的实践。
2、LLM-as-a-Judge
Farmer.Chat 采用复杂的检索增强生成 (RAG) 管道,向农民提供基于知识库的准确和相关信息。RAG 管道使用 LLM 从庞大的知识库中检索信息,然后生成简洁而翔实的响应。
但是,我们如何衡量这个管道的有效性呢?
这里的困难在于,没有确定的指标可以用来评估答案的质量、简洁性和精确性……
这就是 LLM-as-a-Judge 技术发挥作用的地方。这个想法很简单:让 LLM 根据任何指标对输出进行评分。巨大的优势在于指标可以是任何东西:LLM-as-a-Judge 非常灵活。
例如,你可以使用它来评估提示的清晰度,如下所示:
You will be given a user input about agriculture, and your task is to score it on various aspects.
Think step by step and rate the user input on all three following criteria and give a score for each:
1) The intent and ask is clear.
2) The topic is well-specified.
3) The target entity is well-specified, as well as its attributes, for instance "disease resistant" or "high yield".
You should give your scores on an integer scale of 1 to 3, 1 being the worst and 3 the best score.
After creating a score for each three, take the average and round it off to the nearest integer which becomes the final score.
Example:
User input: "tell the benefits of batian coffee variety"
Criterion 1: scores 3, as the intent is clear (about knowing about batian variety of coffee) and the ask is clear (want to summarize the benefits).
Criterion 2: scores 3, the topic is well specified (coffee varieties)
Criterion 3: scores 2, as the entity is clear (batian variety) but not the attributes.正如我们之前提到的这篇文章中提到的,使用 LLM 作为评判者的关键是明确定义任务、标准和整数评分量表。
Farmer.Chat 背后的研究团队利用 LLM 的功能来评估几个关键指标:
- 提示清晰度:此指标评估用户表达问题的能力。LLM 经过培训,可以评估用户意图的清晰度、主题特异性和实体属性识别,从而深入了解用户如何有效地传达他们的需求。
- 问题类型:此指标根据用户的认知复杂性将问题分为不同的类别。LLM 分析用户的查询并将其分配到六个类别之一,例如“记住”、“理解”、“应用”、“分析”、“评估”和“创建”,帮助我们了解用户交互的认知需求。
- 已回答的查询:此指标跟踪聊天机器人回答的问题百分比,深入了解知识库的广度和平台解决各种查询的能力。
- RAG 准确度:此指标评估 RAG 管道检索到的信息的真实性和相关性。LLM 充当评判者,将检索到的信息与用户的查询进行比较,并评估响应是否准确且相关。
它使我们不仅仅能够简单地衡量聊天机器人可以回答多少问题或响应速度。相反,我们可以更深入地研究响应的质量,并以更细致的方式了解用户体验。
对于 RAG 准确度,我们使用 LLM 作为评判者,以二进制尺度进行评估:零或一。但任务分解的方式导致了一个完善的过程,该过程得出了一个分数,我们与人类评估者一起对大约 360 个问题进行了测试:LLM 答案确实做得很好,并且与人类评估具有很高的相关性!
这是提示,灵感来自 RAGAS 库。
You are a natural language inference engine. You will be presented with a set of factual statements and context. You are supposed to analyze if each statement is factually correct given the context. You can come up with the scores of 'Yes' (1) and 'No' (0) as verdict.
Use the following rules:
If the statement can be derived from the context, give a score of 1.
If there is no statement and there is no context, give a score of 1.
If the statement can’t be derived from the context, give a score of 0.
If there is no context but there is a statement, give a score of 0.
#### Input :
Context : {context}
Statements : {statements}上面的上下文变量是用于生成答案的输入块,而语句是另一个 LLM 调用生成的原子事实语句。
这是一个非常重要的步骤,因为它可以实现大规模评估,这在处理大量文档和查询时非常重要。核心的 LLM-as-a-judge 导致指标充当指南针,引导我们 AI 管道可用的各种选项。
3、结果:为 RAG 对 LLM 进行基准测试
我们创建了一个包含 700 多个用户查询的样本数据集,这些查询随机分布在不同的价值链(作物)和日期(月份)中。虽然此升级本身有 11 个不同的版本,使用 RAG 准确度和回答百分比进行评估,但使用相同的方法来衡量领先 LLM 的性能,而无需在每次 LLM 调用中进行任何提示更改。对于这个实验,我们选择了 OpenAI 的 GPT-4-Turbo、Pro 和 Flash 版本的 Gemini-1.5 以及 Llama-3-70B-Instruct。
| LLM | Faithful | Relevant | Answered * Relevant | Answered * Faithful | Unanswered |
|---|---|---|---|---|---|
| GPT-4-turbo | 88% | 75% | 59% | 69% | 21.9% |
| Llama-3-70B | 78% | 76% | 76% | 78% | 0.3% |
| Gemini-1.5-Pro | 91% | 88% | 71% | 73% | 19.4% |
| Gemini-1.5-Flash | 89% | 78% | 74 % | 85% | 4.5% |
我们看到,在四个模型中,Gemini-1.5-pro 获得的事实正确答案(“忠实”列)最高,其次是 Gemini-1.5-Flash 和 GPT-4-turbo。
我们发现,仅从忠实度来看,Gemini-1.5-Pro 胜过其他模型。但如果我们还考虑模型接受回答的问题百分比,Llama-3-70B 和 Gemini-1.5-Flash 的表现会更好。
最终,我们选择了 Gemini-1.5-Flash,因为它在未回答问题百分比低和忠实度非常高之间取得了更好的平衡。
4、结束语
通过利用 LLM 作为评判者,我们可以更深入地了解用户行为以及农业环境中人工智能工具的有效性。这种数据驱动的方法对于以下方面至关重要:
- 改善用户体验:通过确定用户难以表达需求的领域或 RAG 管道未按预期运行的领域,我们可以改进平台的设计和功能。
- 优化知识库:对未回答查询的分析有助于我们确定知识库中的差距并确定内容开发的优先级。
- 选择合适的 LLM:通过对关键指标的不同 LLM 进行基准测试,我们可以做出明智的决定,确定哪些模型最适合特定任务和环境。
LLM 能够作为评判者来评估 AI 系统的性能,这是一个改变游戏规则的能力。它使我们能够以更客观和数据驱动的方式衡量这些系统的影响,最终开发出更强大、更有效、更用户友好的农业 AI 工具。
在一年多的时间里,我们不断改进我们的产品。在这段短暂的时间内,我们已做到:
- 接触超过 2 万名农民
- 回答 > 34 万个问题
- 为 50 种价值链作物提供 > 6 种语言服务
- 保持接近零偏见或不良反应
研究结果最近发表在这篇科学文章中,重点关注用户研究的定量研究。
原文链接:Expert Support case study: Bolstering a RAG app with LLM-as-a-Judge
汇智网翻译整理,转载请标明出处
