Gemma 2微调实现医学问答
本文旨在对医学数据集上的 Gemma 2 模型进行微调,重点关注其在医疗保健相关 QA 任务中的应用。

Gemma 是 Google DeepMind 基于 Gemini 研究和技术开发的开放权重大型语言模型 (LLM) 系列。它是一种尖端语言模型,旨在在特定领域的自然语言处理 (NLP) 任务中表现出色,为专业应用提供高度可定制的框架。
随着大型语言模型 (LLM) 继续展示其在通用任务中的多功能性,对领域适应性的需求变得越来越明显,尤其是在需要深度、特定于上下文的知识的领域——例如医学和医疗保健。医学领域面临着独特的挑战,包括对精确信息检索、患者咨询和复杂问答 (QA) 的需求,所有这些都需要一个针对医学语言和概念的细微差别进行微调的模型。
在本文中,我们旨在对医学数据集上的 Gemma 2 模型进行微调,重点关注其在医疗保健相关 QA 任务中的应用。通过根据医疗领域的复杂性定制 Gemma 的功能,我们可以提高其在提供诊断建议、治疗方案和患者护理支持方面的准确性和相关性。这一过程不仅强调了领域适应性在提高模型性能方面的重要性,还凸显了 LLM 在改变医疗保健等专业行业方面的潜力。
1、Gemma2 的起源
Gemma2 是“Google 增强型多模态机器学习架构”的缩写,是 Google 开创性 AI 模型的第二次迭代,旨在无缝集成和处理多种形式的数据。该模型建立在其前身 Gemma 奠定的基础之上,增强了其理解、分析和生成各种数据类型(如文本、图像甚至音频)输出的能力。
Gemma 模型有多种尺寸可供选择,因此你可以根据可用的计算资源、所需的功能以及想要运行它们的位置构建生成式 AI 解决方案。每个模型都有经过调整和未调整的版本:
- 预训练:该版本的模型未针对 Gemma 核心数据训练集以外的任何特定任务或指令进行训练。我们不建议在未进行调整的情况下使用此模型。
- 指令调整:该版本的模型经过人类语言交互训练,因此它可以参与对话,类似于基本聊天机器人。
- 混合微调:该版本模型在混合学术数据集上进行了微调,并接受自然语言提示。
参数大小越小,资源需求就越低,部署灵活性就越高。
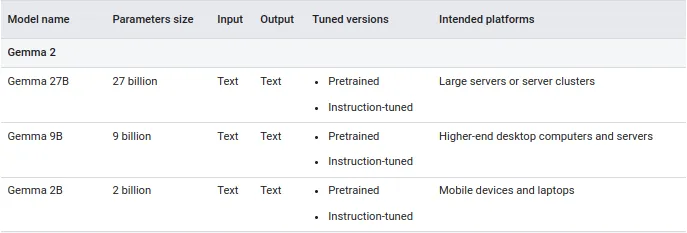
以下是 Gemma 2 模型的核心参数:
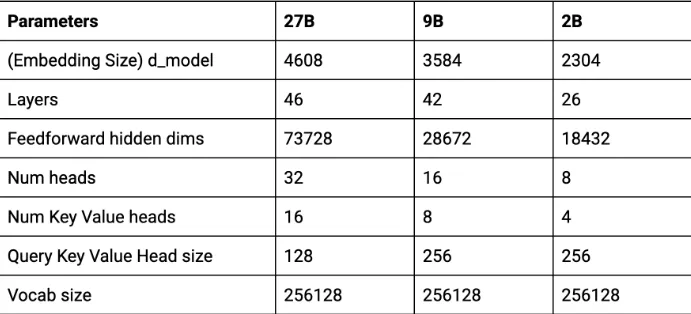
Gemma 2 2b 架构利用先进的模型压缩和提炼技术,尽管尺寸紧凑,但仍实现了卓越的性能。这些方法使模型能够从更大的前辈中提炼知识,从而形成一个高效而强大的 AI 系统。
Gemma 2 2b 是在包含 2 万亿个 token 的庞大数据集上进行训练的,使用的是 Google 最先进的 TPU v5e 硬件。这可以实现快速有效的训练,确保模型能够处理多种语言的多样化复杂任务。
与 Gemma 系列中的其他模型(例如 90 亿 (9B) 和 270 亿 (27B) 参数变体)相比,Gemma 2 2b 因其在大小和效率之间的平衡而脱颖而出。其架构旨在在从笔记本电脑到云部署的各种硬件上表现出色,使其成为研究人员和开发人员的多功能选择。
根据 Google DeepMind Gemma 2 报告,在训练后,他们将 Gemma 2 预训练模型微调为指令调整模型。首先,他们对纯文本、纯英语合成和人工生成的提示响应对的混合应用监督微调 (SFT)。然后将 RLHF 应用于这些模型,其中奖励模型在标记的英语偏好数据上进行训练,策略基于与 SFT 阶段相同的提示。最后,他们对每个阶段后获得的模型取平均值,以提高整体性能。最终的数据混合和训练后配方(包括调整后的超参数)是根据提高有用性同时最大限度地减少与安全性和幻觉相关的模型危害而选择的。
2、Gemma 2微调
根据上一节的规范,我使用 google/gemma-2–2b-it(Gemma 2 2B 指令调整)在lavita/ChatDoctor-HealthCareMagic-100k数据集上对 Gemma 2 进行微调,以进行医疗 QA。你可以在我的 Kaggle Kernel 中找到并编辑整个代码:
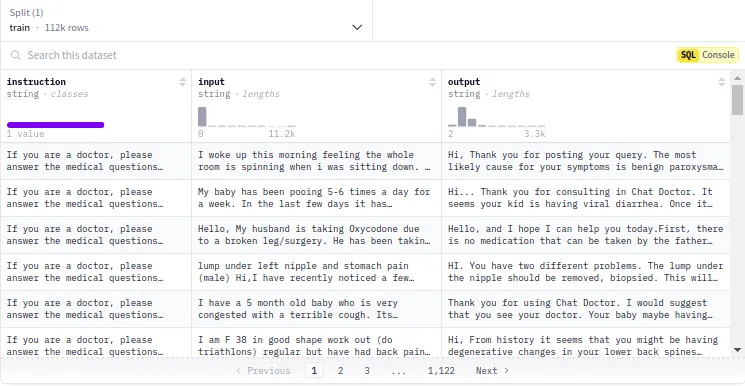
让我们从导入必要的库并在 kaggle 编辑器上设置机密开始:
import os
import torch
import wandb
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
logging
)
from peft import LoraConfig, get_peft_model
from kaggle_secrets import UserSecretsClient
from huggingface_hub import login
from trl import SFTTrainer, setup_chat_format
import bitsandbytes as bnb
# Kaggle secrets setup
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("Hugface")
login(token=hf_token)
wb_token = user_secrets.get_secret("wandb")
# Wandb initialization for tracking
wandb.login(key=wb_token)
run = wandb.init(project='Fine-tune Gemma-2-2b-it on Medical Dataset', job_type="training", anonymous="allow")配置:
# Model configurations
base_model = "google/gemma-2-2b-it"
new_model = "Gemma-2-2b-it-ChatDoctor-HealthCareMagicQA"
dataset_name = "lavita/ChatDoctor-HealthCareMagic-100k"
# Adjust precision and attention based on GPU
if torch.cuda.get_device_capability()[0] >= 8:
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
!pip install -qqq flash-attn # Install flash attention if supported
else:
torch_dtype = torch.float16
attn_implementation = "eager"
# BitsAndBytes configuration for memory-efficient model loading
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model with quantization and optimized attention
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
# Efficient LoRA fine-tuning configuration
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
lora_module_names.discard('lm_head') # Exclude lm_head for 16-bit
return list(lora_module_names)
modules = find_all_linear_names(model)
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)使用 3k 数据样本进行更好的演示:
dataset = load_dataset(dataset_name, split="all", cache_dir="./cache")
dataset = dataset.shuffle(seed=42).select(range(3000)) # Use 3k samples for a better demo
def format_chat_template(row):
row_json = [{"role": "system", "content": row["instruction"]},
{"role": "user", "content": row["input"]},
{"role": "assistant", "content": row["output"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(format_chat_template, num_proc=4)
dataset = dataset.train_test_split(test_size=0.1)
# Dynamic padding for efficiency
data_collator = lambda batch: tokenizer(batch["text"], return_tensors="pt", padding=True, truncation=True)使用日志记录和检查点进行训练:
# Training arguments
training_args = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=200,
save_steps=500,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb",
load_best_model_at_end=False # Disable loading best model at the end
)
# Trainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length=512,
dataset_text_field="text", # Specify composite field called "text"
tokenizer=tokenizer,
args=training_args,
packing=False,
)
# Disable caching during training for gradient computation efficiency
model.config.use_cache = Falsetrainer.train()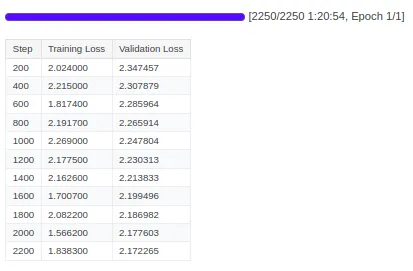
W&B 运行历史记录:
wandb.finish()
model.config.use_cache = True
保存模型并推送到Hub:
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)推理,优化响应生成:
messages = [{"role": "user", "content": "Hello doctor, I have bad and painfull acne on face and body. How can I get rid of it?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
# Optimized generation with tuned sampling strategies
outputs = model.generate(
**inputs,
max_length=350, # Increase max length for complex answers
num_return_sequences=1,
top_k=50,
top_p=0.85, # Narrow top-p for more deterministic output
temperature=0.3, # Slightly higher temperature for balance between creativity and accuracy
no_repeat_ngram_size=3,
)
# Decode and clean up the output
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
response = text.split("assistant")[1].strip()
print(response)响应:

最终,经过微调的模型可在 Hugging Face 中使用:Arnic/Gemma-2–2b-it-ChatDoctor-HealthCareMagicQA
我已经部署了 Gradio 聊天机器人,部署后的一些示例 QA 如下所示:


我们可以使用标准语言模型指标(如困惑度)以及 QA 特定指标(精确匹配、F1 分数)来评估经过微调的模型。 Hugging Face的 evaluate和 datasets等库将有助于实现此过程的自动化。最后,结合人工评估或专家反馈对于确定模型答案的实际适用性至关重要。
困惑度 ( Perplexity) 对于评估模型预测序列中下一个单词的能力很有用,这与传统的语言建模任务一致。但是,QA 任务通常需要评估答案的事实正确性、相关性和连贯性,而不仅仅是模型预测下一个标记的能力。对于 QA 任务,精确匹配、F1 分数、ROUGE 和 BLEU 等指标比困惑度更合适。3、代码说明
让我们分解一下使用 Gemma2 和 Hugging Face 的 Transformers 库进行微调过程中涉及的代码操作和参数的亮点,包括影响模型性能的关键元素。
3.1 量化模型加载
基础模型:Gemma2 2B 模型 (google/gemma-2-2b-it) 作为微调的基础模型加载。
量化:
位和字节配置 ( bnb_config):使用 4 位精度对模型进行量化,以优化内存使用,同时仍允许在 GPU 上训练大型模型。
bnb_4bit_compute_dtype:使用较低的精度将模型放入内存中。bnb_4bit_quant_type:指定量化类型(例如 nf4)。
bnb_config = BitsAndBytesConfig(load_in_4bit=True, ...)
model = AutoModelForCausalLM.from_pretrained(base_model, quantization_config=bnb_config, device_map="auto", ...)- Flash Attention:对于较新的 GPU,在处理长序列时使用
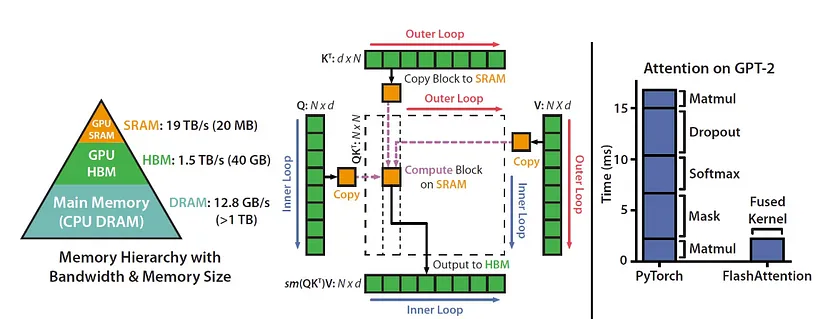
Flash Attention来提高内存效率。
要在模型中使用 Flash Attention,我们需要在加载模型时修改注意机制设置。在我们分享的代码中,我们已经在变量 attn_implementation 下包含了 Flash Attention 的设置。具体来说,它作为模型加载过程的一部分包含在内。以下是我们在代码中设置注意力机制的方法:
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"加载模型时,使用 AutoModelForCausalLM.from_pretrained() 方法将 attn_implementation 传递给模型:
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)Flash Attention 需要 CUDA 11.6 或更新版本,并且我们的 GPU 应具有 8.0 或以上的计算能力(例如 NVIDIA A100)
此外,使用 torch.bfloat16(BFloat16 精度)可确保在使用 Flash Attention 时获得更好的内存效率和性能。
3.2 Tokenizer 设置
在将数据输入模型之前,会加载并配置 tokenizer 以进行文本标记化。
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)3.3 用于微调的 PEFT
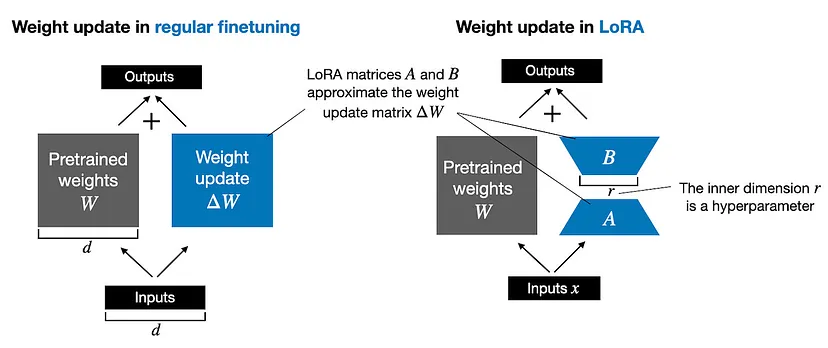
PEFT(参数高效微调):使用 LoRA(低秩自适应)仅微调一小部分模型参数,同时保持其余参数不变。这显著减少了可训练参数的数量并加速了微调过程。
LoRA 配置( peft_config):
- r=16:LoRA 分解的秩。
- lora_alpha=32:LoRA 的缩放因子。
- lora_dropout=0.05:避免过度拟合的 Dropout 率。
peft_config = LoraConfig(r=16, lora_alpha=32, lora_dropout=0.05, ...)
model = get_peft_model(model, peft_config)对于非常大的 LLM,可以在微调期间采用低秩自适应 (LoRA) 等技术。LoRA 利用低秩近似来降低计算和内存成本。分解低秩自适应 (DoRA) 以 LoRA 为基础,为特定任务提供进一步的改进。最后,量化 LoRA (QLoRA) 通过量化原始模型的权重,在保持性能的同时显着减少内存使用量。
3.4 数据集准备
数据集加载:医疗保健数据集 (ChatDoctor-HealthCareMagic-500k) 从 Hugging Face 加载。在这种情况下,数据集被打乱,只选择了 5000 个样本进行快速演示中的迭代。
数据格式化:应用自定义函数将每个数据集行格式化为聊天模板格式。这可确保数据集与模型(系统、用户、助手角色)期望的提示结构相匹配。
dataset = dataset.shuffle(seed=65).select(range(5000))
dataset = dataset.map(format_chat_template, num_proc=4)3.5 训练参数
per_device_train_batch_size:设置每个 GPU/CPU 的训练批次大小。gradient_accumulation_steps=2:在更新之前在 2 个步骤中累积梯度,这可以有效增加批次大小而不会消耗太多内存。optim="paged_adamw_32bit":使用优化的 AdamW 优化器,可高效地以 32 位精度工作。num_train_epochs=1:训练一个 epoch,但可以根据模型性能和数据集大小增加。fp16=False/bf16=False:控制是否使用半精度或 bfloat16 精度来减少训练时的内存需求。(在这种情况下,两者都被禁用。)
3.6 SFT 训练器设置
SFTTrainer:核心微调逻辑由 SFTTrainer 处理,它简化了大型语言模型 (LLM) 的训练,特别关注数据集、标记器和基于 PEFT 的配置。一些参数是:
max_seq_length=512:将序列长度限制为 512 个标记,这可以防止模型在较长的输入上耗尽内存。Packing=False:表示序列打包(为了提高效率)已关闭。在需要对长序列进行高效训练的情况下,可以打开此功能。
3.7 采样和生成策略
一旦模型经过微调,它就可以用于生成 QA 任务的响应。
采样参数:
temperature=0.2:较低的温度有利于更确定性的响应(适用于事实或与医疗保健相关的响应)。top_k=50:将可能的下一个单词限制为前 50 个最有可能的单词。top_p=0.9:选择累积概率为 90% 的单词子集,确保高置信度输出。no_repeat_ngram_size=3:通过强制不重复大小为 3 的 n-gram 来防止模型重复短语。
3.8 解码和打印输出
生成输出后,代码将标记化的响应解码为人类可读的文本。
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])3.9 微调过程的关键部分
这些是微调过程的关键部分,可增强性能和资源管理。让我们深入研究上文解释中遗漏的这些额外关键操作和参数:
A ) 高效数据集加载
使用内存高效技术加载数据集。加载大型数据集时,通常使用 cache_dir 参数将下载的数据集存储在本地目录中,通过缓存磁盘上的数据来减少内存占用并缩短加载时间。
dataset = load_dataset("huggingface_dataset_name", cache_dir="/path/to/cache")这允许处理可能无法一次放入内存的较大数据集。通过在磁盘上缓存数据,您可以动态加载和处理批次,而不会占用过多的内存。
B ) 动态填充
动态填充可确保在每个批次中将序列填充到最大长度,而不是将所有序列填充到固定长度。这可优化内存使用,尤其是在处理长序列时。
data_collator = lambda batch: tokenizer(batch["text"], return_tensors="pt", padding=True, truncation=True)这是一个自定义数据整理器,使用 lambda 函数手动标记和填充批次。这种方法也应用了填充和截断,但它是在一个简单的自定义函数中完成的。然而,它并没有充分利用 Hugging Face 的 DataCollatorWithPadding 的功能,后者更高效、可定制。
C ) 混合精度
FP16 或 BF16(混合精度训练):这允许模型使用半精度浮点数(16 位)进行更快的计算,同时保持足够的数值精度以确保稳定准确的训练。使用的具体精度取决于 GPU 支持(例如,fp16 或 bf16)。
training_args = TrainingArguments(fp16=True, ...)混合精度允许模型在使用更少内存的情况下更快地执行计算,通常不会牺牲模型性能。这在较小的 GPU 上微调大型模型时尤其有益。根据 GPU,您可以使用:
- FP16 (float16):加速操作并减少内存使用量,在许多现代 GPU 上都受支持。
- BF16 (bfloat16):为某些 GPU(例如 A100)提供更好的训练稳定性,同时仍减少内存使用量。
4、潜在改进
提高 LLM(如 Gemma 或 Mistral 7B)中答案(QA)的质量取决于多种因素,包括提示设计、模型微调、数据质量和利用先进技术。以下是一些有助于在与 LLM 交互时改进 QA 的策略,尤其是在经过微调的环境中,例如医学 QA 系统。
- 使用少量提示
少量提示可以通过提供问答对的示例来显著增强模型的准确响应能力。这使模型能够理解响应的所需格式和内容。
prompt = """
Q: What are the symptoms of diabetes?
A: The symptoms of diabetes include increased thirst, frequent urination, fatigue, and blurred vision.
Q: What are the treatments for hypothyroidism?
A:
"""- 结合后处理技术
对生成的答案进行后处理可以帮助提高质量、结构和准确性。技术包括:
- 答案验证:通过将生成的答案与已知事实或知识库进行比较来检查其一致性。
- 重新排名答案:如果模型生成多个答案,请使用重新排名算法来选择最相关和最准确的答案。
例如:对于医学 QA,您可以将模型的答案与经过验证的医学数据进行比较,以确保它不会产生幻觉(错误信息)。
- 人机反馈
改进 QA 的另一种有效方法是将人工反馈整合到模型微调循环中。通过收集有关模型答案质量和正确性的反馈,您可以迭代地提高其性能。
例如使用带有人工反馈的强化学习 (RLHF),这种方法根据人类偏好对模型进行微调,使其更符合用户期望。
原文链接:Fine-Tuning Gemma 2 for Medical Question Answering: A Step-by-Step Guide
汇智网翻译整理,转载请标明出处
