用MLX-LM微调Mistral-7B
在本教程中,我们将借助 mlx-lm 包加载Mistral-7B-Instruct-v0.3–4bit 模型,并使用LoRA对其进行微调。

MLX 是一个专为Apple硅片上的高效机器学习研究设计的数组框架。其最大的优势在于利用了Apple设备的统一内存架构,并提供了类似于NumPy的API。Apple还开发了一个用于LLM文本生成、微调等的包,称为MLX LM。
总体来说,mlx-lm 支持许多Hugging Face格式的LLM。使用 mlx-lm 可以非常方便地直接从Hugging Face的MLX社区加载模型。这是一个存放可以在Apple硅片上运行的预转换权重的模型的地方,包含了许多可以直接使用的模型。该框架还支持参数高效的微调(PEFT),包括LoRA和QLoRA。您可以在以下论文中找到更多关于LoRA的信息。
在本教程中,我们将借助 mlx-lm 包从MLX社区空间加载Mistral-7B-Instruct-v0.3–4bit 模型,并使用LoRA和数据集win-wang/Machine_Learning_QA_Collection对其进行微调。让我们开始吧。
1、包和模型加载
首先,我们需要加载所需的包。
import json
import os
from typing import Dict, List, Optional, Tuple, Union
import matplotlib.pyplot as plt
import mlx.optimizers as optim
from mlx.utils import tree_flatten
from mlx_lm import generate, load
from mlx_lm.tuner import TrainingArgs, datasets, linear_to_lora_layers, train
from transformers import PreTrainedTokenizer
然后,我们应该加载模型和分词器。
model_path = "mlx-community/Mistral-7B-Instruct-v0.3-4bit"
model, tokenizer = load(model_path)
让我们看看给定一个简单的提示如“什么是机器学习中的微调?”时,我们的模型会输出什么。
prompt = "What is fine-tuning in machine learning?"
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
模型生成的输出是:
在机器学习中,微调是指将一个已经在一个大型数据集上针对特定任务进行过预训练的模型,调整以适应新的相关任务或同一任务的不同方面。
例如,假设你有一个可以识别不同动物类型的预训练模型。你可以微调这个模型来识别特定品种的狗,甚至识别不同的花卉类型。想法是预训练模型已经学到了对新任务有用的通用特征,而微调有助于模型学习新任务的重要具体细节。
当新任务的数据量较小的时候,微调通常会被用到,因为它允许模型利用从大型预训练数据集中获得的知识。它是深度学习中的一种常见技术,特别是在图像分类、自然语言处理和语音识别等任务中。
2、微调准备
让我们创建一个名为 adapters 的目录,并设置适配器配置路径(在我们的例子中是LoRA配置)和适配器文件路径。
adapter_path = "adapters"
os.makedirs(adapter_path, exist_ok=True)
adapter_config_path = os.path.join(adapter_path, "adapter_config.json")
adapter_file_path = os.path.join(adapter_path, "adapters.safetensors")
我们需要设置LoRA参数配置。这可以通过一个单独的.yml文件完成,如这里所示,但为了代码简洁性和展示LoRA和mlx-lm微调的过程,我们将采用简单的内联配置
lora_config = {
"num_layers": 8,
"lora_parameters": {
"rank": 8,
"scale": 20.0,
"dropout": 0.0,
},
}
将其保存到我们已经创建的 adapters 目录中。
with open(adapter_config_path, "w") as f:
json.dump(lora_config, f, indent=4)
我们还可以设置训练参数,指定适配器文件路径、迭代次数以及每次评估的步数。
training_args = TrainingArgs(
adapter_file=adapter_file_path,
iters=200,
steps_per_eval=50,
)
在LoRA框架中,大多数原始参数在微调过程中保持不变。model.freeze() 命令用于将这些参数设置为不可训练状态,以便它们的权重不会在反向传播过程中更新。这样,只有新引入的低秩自适应矩阵(LoRA参数)被优化,从而减少了计算开销和内存使用,同时保留了原始模型的知识。
linear_to_lora_layers 函数将模型的一些线性层转换或包装成LoRA层。本质上,它用(或增加)选定的线性层替换为LoRA层,这些层包括将要训练的额外低秩矩阵。配置参数(如层数和特定的LoRA参数)决定了哪些层被修改以及如何设置LoRA适配器。
我们还应该验证只有少量参数被设置为训练,并在保持主要模型参数冻结状态的同时激活训练模式。
model.freeze()
linear_to_lora_layers(model, lora_config["num_layers"], lora_config["lora_parameters"])
num_train_params = sum(v.size for _, v in tree_flatten(model.trainable_parameters()))
print(f"Number of trainable parameters: {num_train_params}")
model.train()
我们还可以创建一个类来跟踪训练过程中的训练和验证损失指标
class Metrics:
def __init__(self) -> None:
self.train_losses: List[Tuple[int, float]] = []
self.val_losses: List[Tuple[int, float]] = []
def on_train_loss_report(self, info: Dict[str, Union[float, int]]) -> None:
self.train_losses.append((info["iteration"], info["train_loss"]))
def on_val_loss_report(self, info: Dict[str, Union[float, int]]) -> None:
self.val_losses.append((info["iteration"], info["val_loss"]))
并创建该类的一个实例。
metrics = Metrics()
3、数据加载
这里,我们创建了一个简化版本的以下函数,用于加载Hugging Face数据集。
def custom_load_hf_dataset(
data_id: str,
tokenizer: PreTrainedTokenizer,
names: Tuple[str, str, str] = ("train", "valid", "test"),
):
from datasets import exceptions, load_dataset
try:
dataset = load_dataset(data_id)
train, valid, test = [
(
datasets.create_dataset(dataset[n], tokenizer)
if n in dataset.keys()
else []
)
for n in names
]
except exceptions.DatasetNotFoundError:
raise ValueError(f"Not found Hugging Face dataset: {data_id} .")
return train, valid, test
然后,让我们从Hugging Face加载win-wang/Machine_Learning_QA_Collection数据集。
train_set, val_set, test_set = custom_load_hf_dataset(
data_id="win-wang/Machine_Learning_QA_Collection",
tokenizer=tokenizer,
names=("train", "validation", "test"),
)
4、微调
最后,我们可以调用 train() 函数开始LoRA微调过程。
train(
model=model,
tokenizer=tokenizer,
args=training_args,
optimizer=optim.Adam(learning_rate=1e-5),
train_dataset=train_set,
val_dataset=val_set,
training_callback=metrics,
)
训练完成后,我们还可以绘制训练和验证损失。
train_its, train_losses = zip(*metrics.train_losses)
validation_its, validation_losses = zip(*metrics.val_losses)
plt.plot(train_its, train_losses, "-o", label="Train")
plt.plot(validation_its, validation_losses, "-o", label="Validation")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.legend()
plt.show(
例如,一次训练的结果如下图所示。
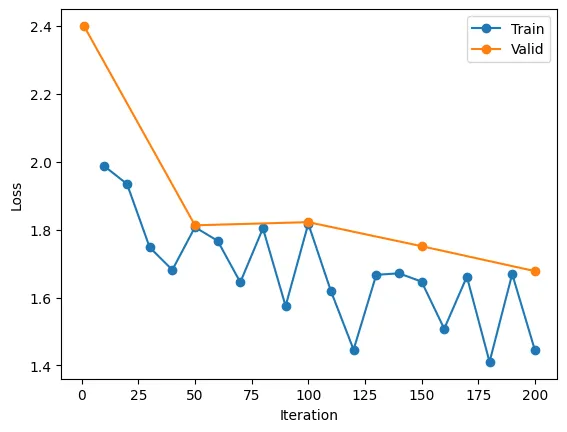
5、测试模型_lora
现在,我们可以加载微调后的模型,指定 adapter_path,
model_lora, _ = load(model_path, adapter_path=adapter_path)
并为之前的提示生成输出。
response = generate(model_lora, tokenizer, prompt=prompt, verbose=True)
生成的响应是:
在机器学习中,微调是指调整预训练模型的参数,使其适应特定的任务或数据集。这种方法常用于可用数据有限的情况,因为它允许模型利用之前训练中获得的知识。微调可以提高模型在新任务上的性能,使其成为许多机器学习应用中的宝贵技术。
6、结束语
在这篇教程中,我们探讨了如何利用MLX LM和LoRA在Apple硅片上微调大型语言模型。
我们从设置必要的环境开始,从MLX社区加载预训练模型,并从Hugging Face准备数据集。通过将选定的线性层转换为LoRA适配器并冻结大部分模型的权重,我们使用适度的计算资源有效地微调了模型。
这种方法不仅优化了资源使用,还打开了实验不同微调策略和数据集的大门。可以进一步探索其他修改,例如尝试其他适配器配置如QLoRA(通过集成量化技术扩展LoRA方法)、融合适配器、整合更多的评估指标以更好地理解模型的性能等。
原文链接:Fine-Tuning LLMs with LoRA and MLX-LM
汇智网翻译整理,转载请标明出处
