本地微调 Qwen3-VL 模型
在本文中,我们将探讨 Qwen3-VL 与 Qwen2.5-VL 在架构、训练和整体性能方面的区别,介绍 GPU 要求,并逐步讲解如何使用 Unsloth进行微调。

Qwen 于 9 月发布了首批 Qwen3-VL 模型。他们首先发布了 Qwen3-VL-235B-A22B,然后逐步发布了基于 Qwen3 A30B-A3B、8B 和 4B 的模型。它们都可以在 Hugging Face Hub 上找到(Apache 2.0 许可)。
或许会有更小的模型出现(可能性不大)(10 月 21 日更新:他们发布了 2B 和 32B 版本),但由于后两个模型足够小,可以在消费级 GPU 上运行,我认为现在是时候回顾一下目前最好的开源权重视觉语言模型 (VLM) 了!
在本文中,我们将探讨 Qwen3-VL 与 Qwen2.5-VL 在架构、训练和整体性能方面的区别。我们还将介绍 GPU 要求,展示如何运行这些模型,并逐步讲解如何使用 Unsloth 对 Qwen3-VL 进行微调。
1、Qwen3-VL vs. Qwen2.5-VL:新增功能
Qwen3-VL 保留了与早期 Qwen-VL 模型相同的“图像-视频-文本输入,文本输出”模式,但底层架构已更新。
Qwen3-VL 依赖于 Qwen3 LLM。它们本身并非多模态模型。视觉编码器被挂载在 LLM 之上,然后整个模型栈在多模态数据上进行后训练。
视觉栈迁移到了一种名为 DeepStack 的更深层次的特征融合方法,该方法在将多级 ViT 特征输入语言模型之前进行融合。位置处理方式通过交错式多分辨率嵌入(Interleaved-MRoPE)进行了全面改进,使空间宽度/高度和时间共享一个稳健的嵌入方案,并且视频路径将标记与明确的时间戳对齐,而不是使用较为宽松的时间提示。这些改进共同实现了长时域视频推理和细粒度的空间定位,同时避免了标记数量的膨胀,这对于保持图像标记数量的合理性并避免内存消耗过大至关重要。
以下是 Qwen2.5-VL 与 Qwen3-VL 的对比(插图由 Qwen 提供):
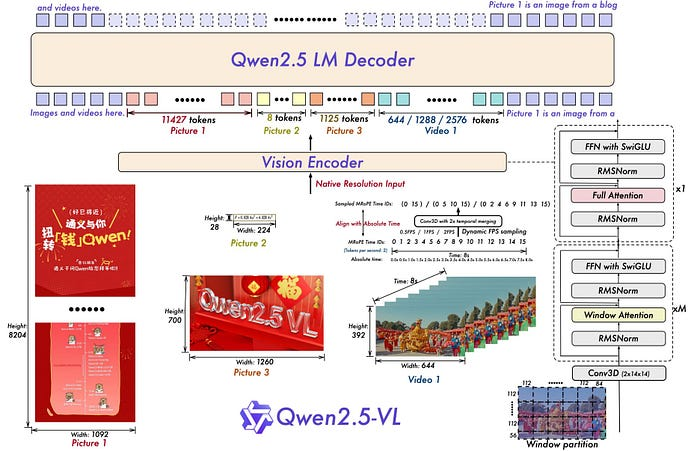
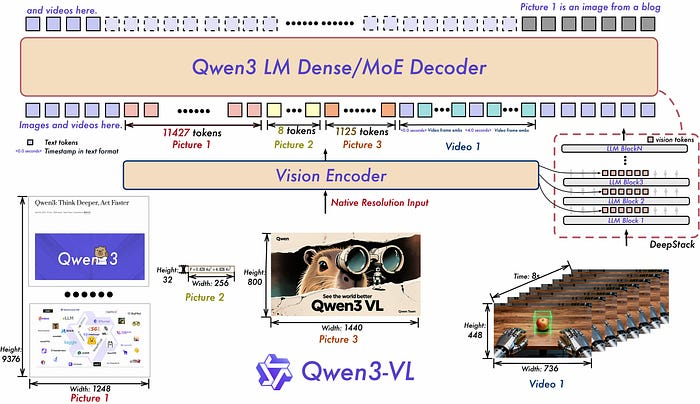
训练过程遵循 Qwen3 的方案:大规模预训练,然后进行多模态对齐和指令调优。
Qwen3-VL 代码库记录了一个经过改进的视觉处理器,它采用了不同的图像块大小,并配备了用于控制每个输入像素预算的实用程序。实际上,这使得您可以在关键区域保留高细节,避免在冗余帧上浪费上下文信息。最终实现了原生 256K 上下文窗口,对于检索密集型任务,该窗口还可以进一步扩展,视频流水线将事件索引到秒级,而不是大片段。
性能表现符合预期,这得益于架构的转变和强大的 Qwen3 模型:更强大的文档解析能力、对 32 种语言更可靠的 OCR、更佳的空间推理和定位能力,以及更稳定的长视频理解能力。他们在常见的视觉和文本基准测试中均取得了提升,并突出了 GUI 控制中“视觉代理”行为的改进,这依赖于更精确的识别和更稳健的逐步推理。
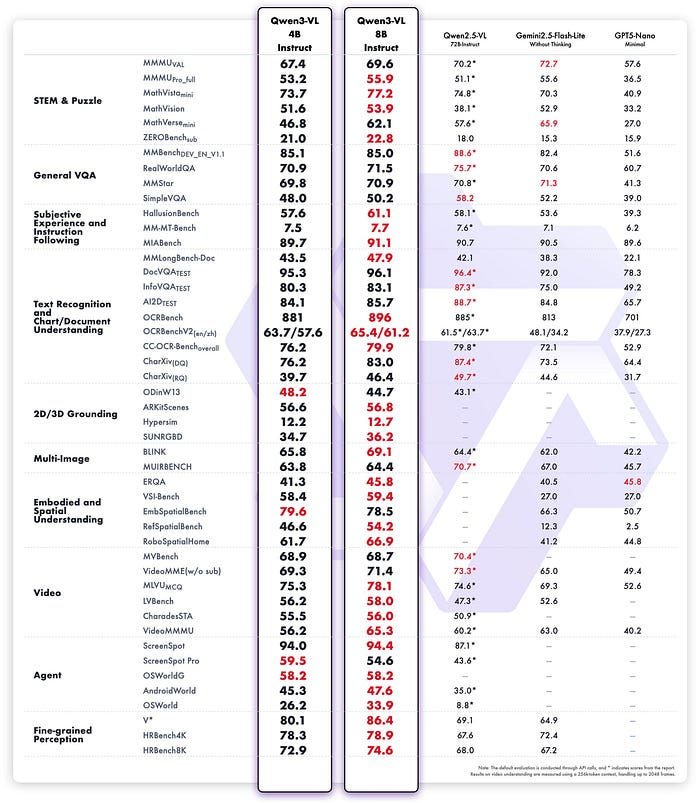
Qwen3-VL 是优秀的语言模型,规模较大的模型在语言任务上的表现往往优于其基础语言学习模型 (LLM)。这些改进的根源目前尚未得到充分研究,但其原理显而易见:由于 Qwen3-VL 使用新数据(图像/视频+文本)进行后训练,因此它会接触到新的词元,也就是说,Qwen3-VL 的训练时间比 Qwen3 更长。对于规模较小的模型而言,引入新的模态往往会使其学习能力饱和,并常常导致其语言理解准确率下降,这一点在 Qwen3-VL 4B 中体现得尤为明显。
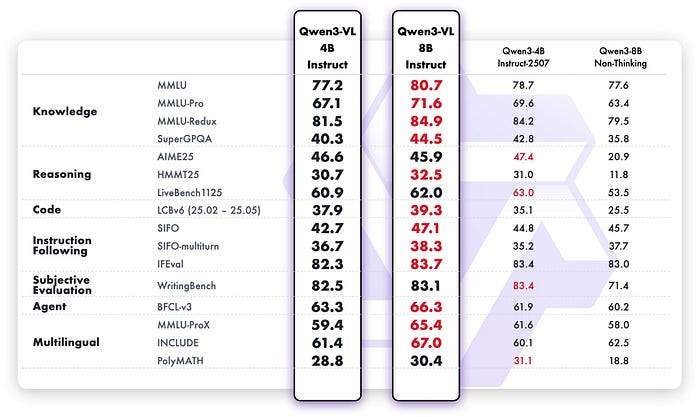
我还通过 Kaitchup 指数确认,4B VL 版本在语言任务方面优于原始 LLM:
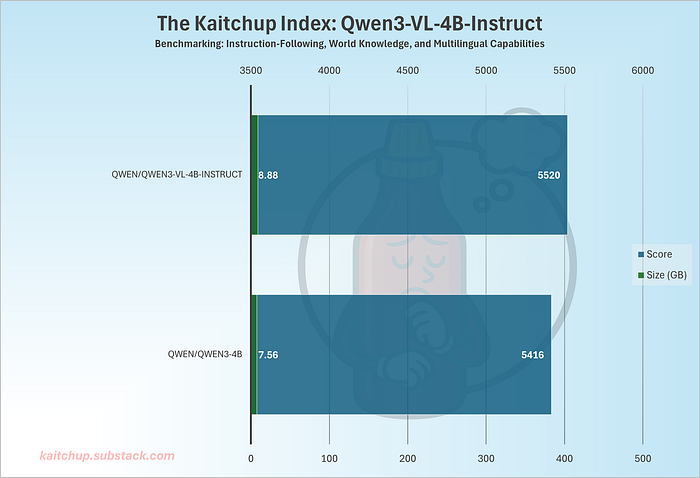
它的性能显著提升,但 VL 模型会占用更多内存。
与 Qwen2.5-VL 相比,差异显而易见。Qwen2.5-VL 引入了现代基线、图像动态分辨率、窗口注意力机制以加速 ViT 运算、升级了 MRoPE 算法以及动态帧率采样,从而能够处理超过一小时的视频,此外还支持使用框和点进行良好的目标定位。Qwen3-VL 保留了这些优势,但替换了位置和融合的内部机制,扩展了 OCR 覆盖范围,并将上下文窗口从 Qwen2.5-VL 的 128K 标准值提升至原生 256K,同时还增强了视频的时间戳级别定位。如果您使用 Qwen2.5-VL 处理文档、图表和长视频,则需要支付 Qwen3-VL 的费用。它既熟悉又更精确,并且在处理长篇混合媒体提示时也更稳定。
我预计您可以安全地在应用程序中用 Qwen3-VL 替换 Qwen2.5-VL。唯一可能重要的区别是模型大小不同(例如,Qwen2.5-VL 有 3B 和 7B 版本,而 Qwen3-VL 没有),并且可能比其最接近的 Qwen3-VL 版本占用更多或更少的内存。
让我们看看如何使用这些模型。
2、Qwen3-VL 的 GPU 要求
4B 和 8B 模型是仅有的能够常规地在单个消费级 GPU 上进行 LoRa/QLoRA 微调的模型。
实际上,Qwen3-VL 4B 在批处理大小为 1、权重为 4 位、梯度检查点和约 448 像素图像的情况下,需要 16 GB 显存才能运行。 20–24 GB 的内存允许您将批处理大小设置为 2,但这未必能提高训练速度。
8B 模型占用内存更大:在相同设置下,批处理大小为 1–2 时,预算约为 24 GB;16 GB 内存只有在严格限制条件下(批处理大小为 1、序列更短、积极进行内存卸载)才可行。这些数据与当前的 Qwen3-VL 指南和社区运行手册一致,这些指南和手册展示了在 Unsloth 的内存节省方案下,如何在单张显卡上对 8B 模型进行 LoRa 微调。
对于 MoE 变体,如果您保持专家模型和路由器冻结(常用方法)并使用 4 位加载,则可以在单张约 18 GB 的显卡上对 Qwen3-VL-30B-A3B 模型进行 LoRa 微调。
Unsloth 明确指出,30B-A3B 模型的微调可在约 17.5 GB 显存下运行。
相比之下,旗舰级的 Qwen3-VL-235B-A22B 则属于另一个级别:它至少需要 8 个 80 GB 的 GPU 用于 LoRa。为了对 235B-A22B 进行完整的微调(FFT),它需要解冻专家模型。您需要为活跃的专家模型添加完整的梯度和优化器状态,这样很快就会超过 8 个 80 GB 的 GPU 占用。实际上,这是一个大型分布式作业(FSDP/ZeRO/Megatron-MoE + 专家并行)。
本文将重点放在一个更实际的目标上:Qwen3-VL-8B。
3、使用 Unsloth 对 Qwen3-VL 进行监督式微调
这个 notebook 使用 Unsloth 对 Qwen3-VL-8B 指令进行微调,使其能够使用轻量级 LoRa 适配器进行图表问答。
注意:避免对思考版本进行微调;除非在训练过程中提供良好的多模态推理轨迹,否则将会破坏模型的“推理”能力。
核心思路很简单:冻结庞大的视觉塔,在语言栈中训练小型适配器,向模型输入格式良好的多模态序列,并运行一个包含 TRL 的短 SFT 循环,以快速学习任务。
我使用了 Unsloth 官方 notebook 中的一些单元格,他们还发布了一个 GRPO notebook 。
代码通过 FastVisionModel.from_pretrained 加载 Qwen/Qwen3-VL-8B-Instruct 模型,然后通过 FastVisionModel.get_peft_model 挂载 LoRa 适配器。
model_name = "unsloth/Qwen3-VL-8B-Instruct-unsloth-bnb-4bit" # base 8B VL Instruct already quantized (faster download)
max_seq_length = 16384 # tokenizer context; VLMs can go long
load_in_4bit = True # QLoRA style
dtype = torch.bfloat16 # bfloat16 not on all Colab GPUs
model, tokenizer = FastVisionModel.from_pretrained(
model_name = model_name,
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = False, # I recommend to freeze the vision tower
finetune_language_layers = True, # set False to freeze the text backbone
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 16,
lora_alpha = 16,
lora_dropout = 0.0,
bias = "none",
random_state = 3407,
use_gradient_checkpointing = "unsloth", # True or "unsloth" for long context
)视觉层保持冻结状态以节省内存并稳定训练,而语言侧的注意力模块和 MLP 模块则设置 LoRA 排名和 alpha 值(例如,r=16,lora_alpha=16,无 dropout)。这是典型的 LoRA 做法。训练占用空间从“在单个 GPU 上不切实际”降至“可行”,因为只有极小一部分参数可以训练。我们得到:
trainable params: 43,646,976 || all params: 8,810,770,672 || trainable%: 0.4954这种选择(冻结视觉层,调整语言层)与任务相符:模型主要需要学习如何读取它已经“看到”的图表特征,而不是重新学习视觉特征。
第二个关键部分是提示和分词路径。每个 ChartQA 示例都会被转换成一个聊天消息列表,其中包含一张图片、一条说明和一个问题。
[{'role': 'user', 'content': [{'type': 'text', 'text': 'You are a precise chart analyst. Read the chart and answer the question.\nKeep the final answer concise (numbers/text only).\nQuestion: What is the sum difference of Remain in EU and Leave in EU in the year 2014?'}, {'type': 'image', 'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=309x351 at 0x7BC9FBAC23C0>}]}, {'role': 'assistant', 'content': [{'type': 'text', 'text': '9'}]}]这一格式化步骤使得模型表现得像一个会说话的语音交互模型(VLM),而不是一个纯文本模型。
训练本身使用 TRL 的 SFTTrainer、SFTConfig 和 UnslothVisionDataCollator。根据 Unsloth 的 SFT notebook,在启动之前似乎需要调用 FastVisionModel.for_training(model),但 GRPO notebook 没有使用这一步,所以我猜测即使没有明确编写,它也可能已经执行了。以下三个参数也很重要,它们通常是使用 TRL 进行 VLM 微调的必要条件,以防止模型破坏已准备好的数据集(例如,重新准备数据集、删除图像等):
dataset_text_field = "",
dataset_kwargs = {"skip_prepare_dataset": True},
remove_unused_columns = False,4、使用 Qwen3-VL 进行推理
现在我们知道如何微调模型了,接下来看看如何运行它。
使用 VLM 进行推理现在已经非常规范化了。与纯文本任务类似,查询是一个消息列表,其中可以包含文本、多张图像或视频。
使用 vLLM,这很简单:启动一个指向 Qwen/Qwen3-VL-8B-Instruct 的 OpenAI 兼容服务器,然后使用包含文本和图像的标准聊天补全请求调用它。
# 1) Start a server
vllm serve Qwen/Qwen3-VL-8B-Instruct --trust-remote-code --host 0.0.0.0 --port 8000
# 2) Query it with the OpenAI-compatible API (another terminal)
import base64, requests, json
API_URL = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
def file_to_data_url(path):
with open(path, "rb") as f:
b64 = base64.b64encode(f.read()).decode()
return f"data:image/png;base64,{b64}"
image_url = file_to_data_url("receipt.png") # or a https URL
payload = {
"model": "Qwen/Qwen3-VL-8B-Instruct",
"messages": [
{"role": "user",
"content": [
{"type": "text", "text": "Read all the text in the image."},
{"type": "image_url", "image_url": {"url": image_url}}
]}
],
"temperature": 0.0,
"max_tokens": 256
}
resp = requests.post(API_URL, headers=headers, data=json.dumps(payload), timeout=120)
print(resp.json()["choices"][0]["message"]["content"])此设置提供了一个本地多模态端点,其中图像通过 OpenAI 消息模式传递,其余部分由 Qwen3-VL 处理。如果以后需要跨多个 GPU 扩展,请保留相同的客户端代码,并在 serve 命令中添加 tensor_parallel_size 标志。vLLM 将在保持 API 接口不变的情况下对模型进行分片。
原文链接:Qwen3-VL Fine-Tuning on Your Computer
汇智网翻译整理,转载请标明出处
