FLUX.1 低成本LoRA微调
本指南将向你展示如何在自己的图像上集微调FLUX.1,使用消费级硬件,不到一小时即可完成。
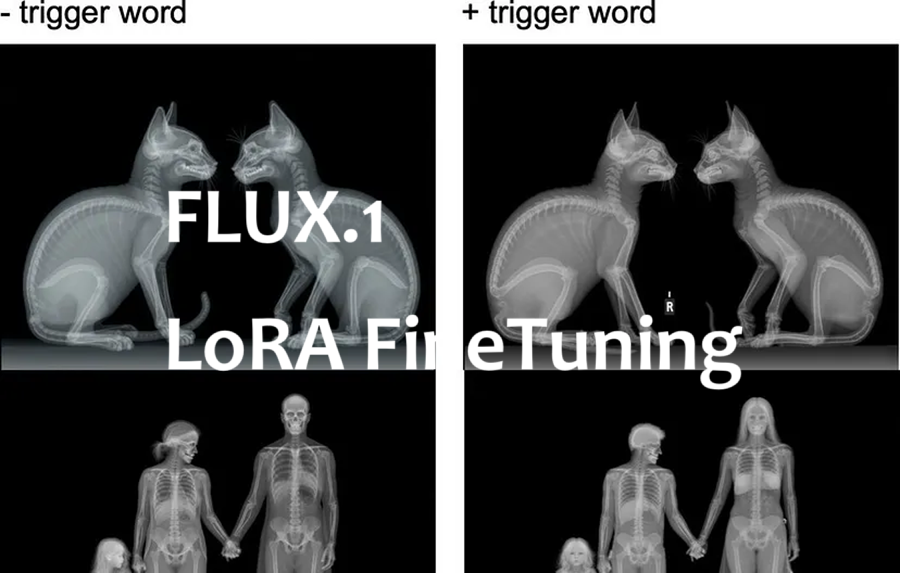
FLUX.1 风靡全球,在这篇文章中,我将向你介绍如何在自定义图像上训练 LoRA(低秩自适应),使 FLUX1 能够学习特定的风格或特征并重现它们。
我选择了一些不寻常的东西作为我的目标:X 射线图像!

本指南将向你展示如何在自己的照片、风格或任何类型的图像上训练这样的 LoRA;使用 Ostris 的 AI 工具包和廉价的云 GPU 或你的家庭设置,不到一小时即可完成。
1、数据集
对于这个项目,我从网上收集了 30 张 X 射线图像。数据集包括人类和非人类示例,其中一些非常不寻常。由于版权原因,这些图像不公开,但此处构建的 LoRA 适配器纯粹用于教育目的。
以下是四张输入图像的选择以及标题。
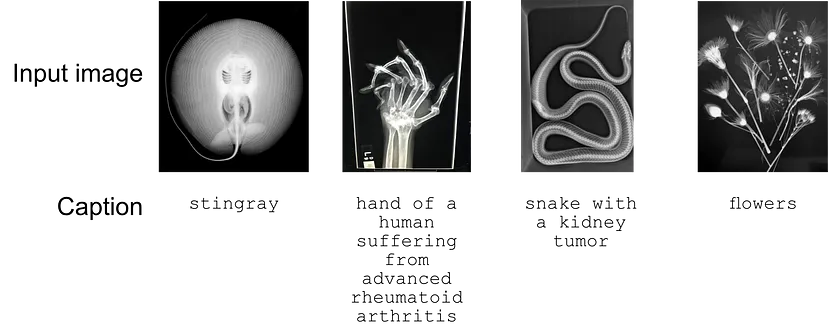
总共对 30 张图像进行了 LoRA 训练。
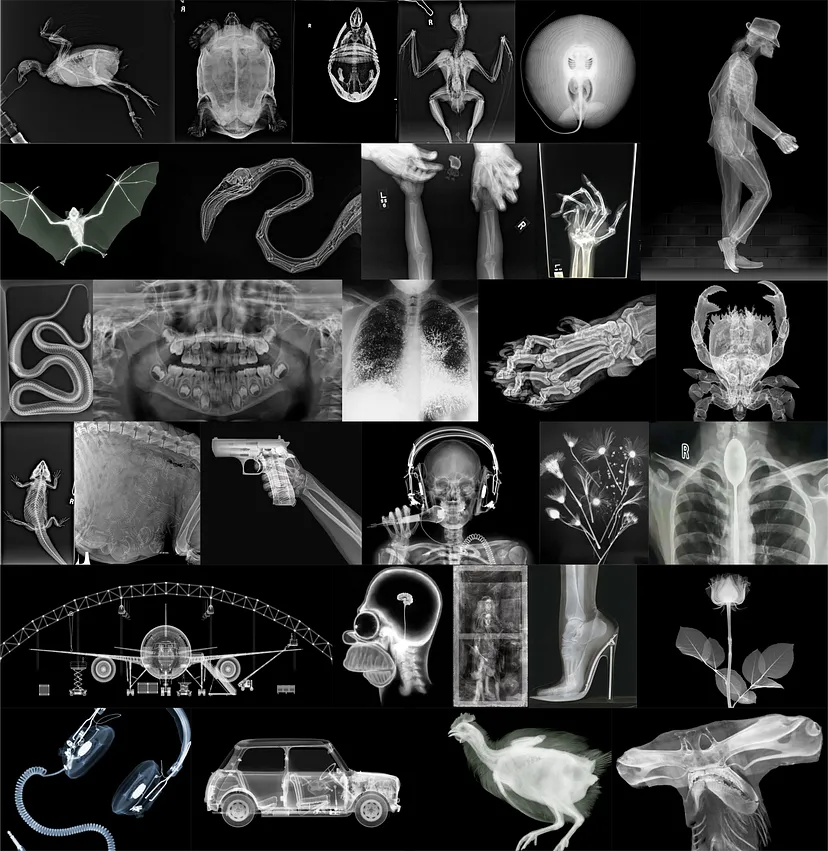
请注意,这些图像中的大多数都受版权保护,此处制作的适配器仅用于教育目的。
2、训练
为了训练这个 LoRA,我在 RunPod 上租了一个 GPU,但如果你有合适的设置,可以使用任何 GPU 提供商,甚至可以在家训练。以下是使用 RunPod 和 RTX 3090 或 4090 复制此过程的方法,两者都为这项任务提供了足够的内存。
步骤 1:租用 GPU 并启动 Jupyter Notebook
如果你家里有 GPU,请跳过此步骤。如果没有,请前往 RunPod 租用 pod。以下是操作方法:
创建或登录你的 runpod 帐户,然后前往控制台部署新的 pod。
选择社区云上的 NVIDIA GeForce RTX 4090,每小时 0.44 美元,这是速度和价格之间的良好权衡。
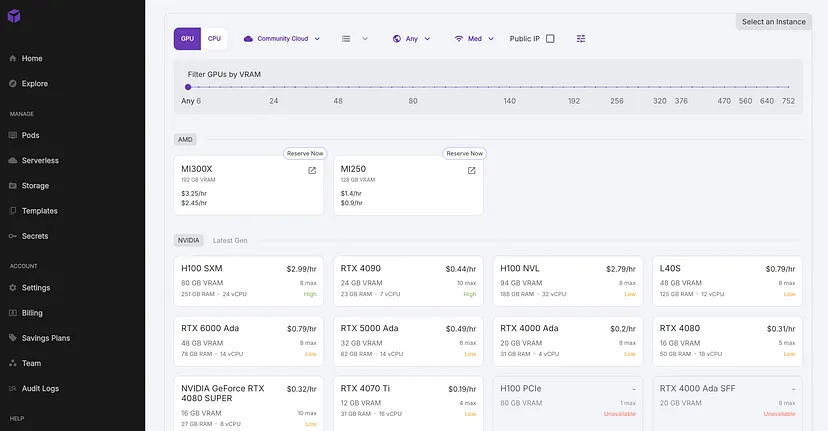
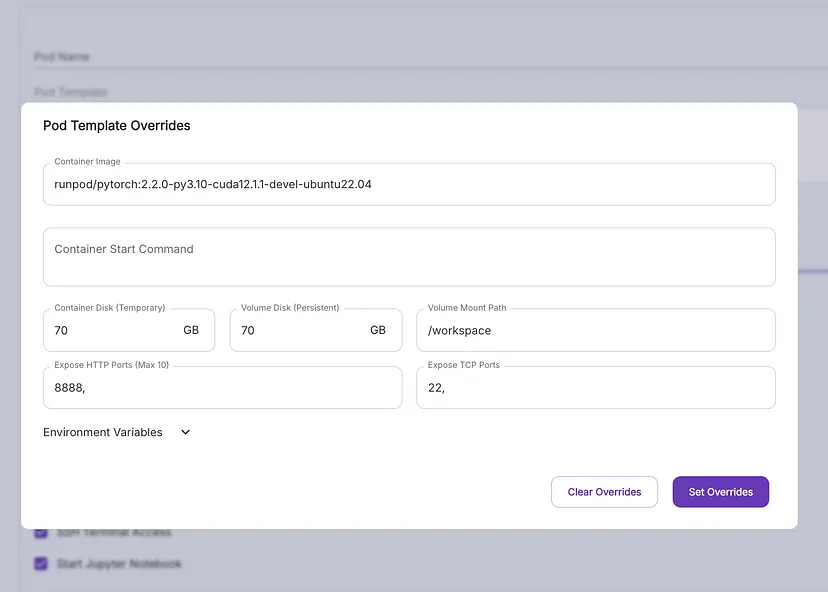
标准 PyTorch 模板就可以了;选择编辑模板并请求 70GB 的容器和卷磁盘空间。
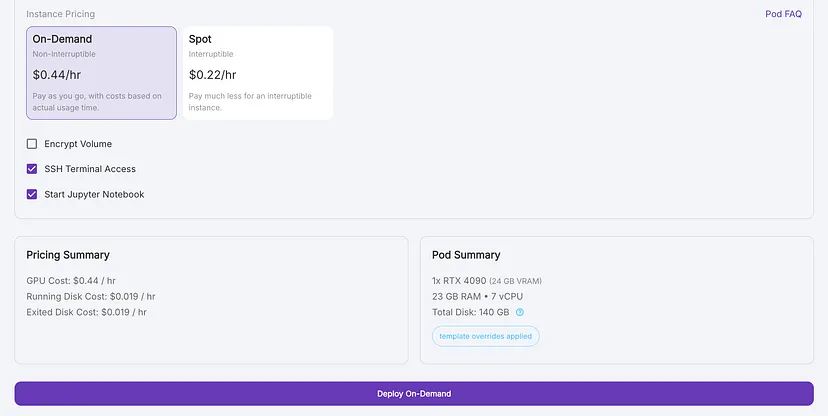
部署 pod,默认情况下会选中“Jupyter 笔记本”,这是我们指导训练过程所需要的。
pod 准备就绪后,单击“连接”>“连接到 Jupyter Lab”
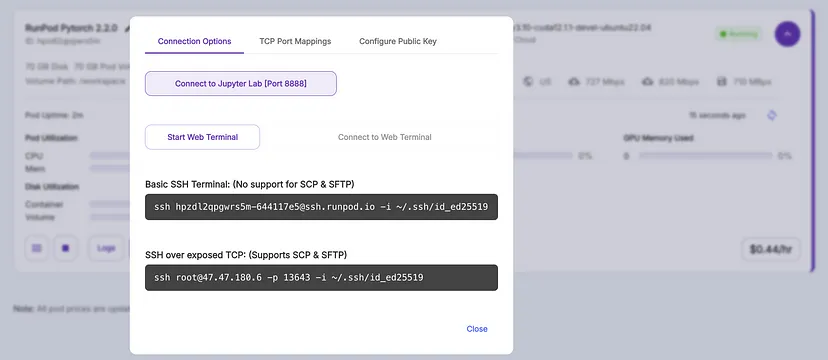
在 Jupyter Lab 中,创建一个新的“Python 3”笔记本,您就可以开始了!
步骤 2:设置 ai-toolkit
我们首先从 GitHub 下载 Ostris 的 AI-Toolkit 并安装其所有依赖项。 /workspace 是 RunPod 上卷的通用挂载点,但你可以在此处使用任何其他目录。
!cd /workspace
!git clone https://github.com/ostris/ai-toolkit.git
!cd ai-toolkit && git submodule update --init --recursive && pip install -r requirements.txt步骤 3:上传你的图像和标题
创建一个文件夹 /workspace/images 来存储你的图像。
将你的 X 射线图像连同标题文件(.txt 格式的简短描述)拖放到此文件夹中。
在单独的 .txt 文件中上传至少 10 幅图像和包含图像简短描述的标题。
步骤 4:登录 huggingface
FLUX1-dev 模型的访问受到限制,因此你必须首先接受其条款。登录你的 Hugging Face 帐户(或创建一个)并接受其条款:FLUX1-dev 存储库。
接下来,在此处生成 Hugging Face API 令牌并登录:
!huggingface-cli login --token hf_XXXXTOKENXXXX步骤 5:开始训练
定义训练参数:
INPUT_FOLDER = "/workspace/images"
OUTPUT_FOLDER = "/workspace/output"
TRIGGER_WORD = "eksray"
LORA_RANK = 16
BATCHSIZE = 1
LEARNING_RATE = 0.0001
STEPS_TRAIN = 3000
STEPS_SAVE = 250
STEPS_SAMPLE = 250- 触发词 (
TRIGGER_WORD):可以是 FLUX1 尚不熟悉的任何单词。这个独特的词(例如,eksray)将触发我们训练过的特征。如果你的字幕文本文件不包含触发词,它将自动添加。 - LoRA 阶数 (
LORA_RANK):平衡可训练参数和模型容量。更复杂的适应可能需要更高的等级,但需要更多的 VRAM。根据我的经验,16 是一个好的开始,但对于 X-Rays,等级越高,如 32,代数肯定越好。 - 批次大小 (
BATCHSIZE):低批次大小 1 可最大限度地减少 VRAM 使用量并降低内存耗尽的风险,但会减慢训练速度,并且可能无法充分利用 GPU 的功能。同样,更高的批次大小需要更多的 VRAM,而对于 24GB VRAM GPU,我们只能使用 1 的批次大小。 - 学习率 (
LEARNING_RATE):指定在每个更新步骤中权重在梯度方向上的变化量。我在这里选择了 0.0001,这是大多数训练师用作起点的。对角色(面部)的训练也适用于更高的 LR 0.0004。更高的值仍将产生良好的适配器取决于数据集,但根据我的经验,高于 0.001 的一切都不是一个好主意。 - 训练步骤 (
STEPS_TRAIN):提供足够的训练时间来学习所需的特征,但可能很耗时。我为 X 射线选择了 3000 步,但根据训练集和其他参数,您可以期望仅用 500 到 1000 步就能获得不错的结果。 - 保存步骤 (
STEPS_SAVE):保存适配器的频率。我建议将其保持在较低水平并经常保存,以查看在哪个点生成开始看起来像您期望的那样以及过了这个点(过度训练) - 样本步骤 (
STEPS_SAMPLE):生成样本图像的频率。
创建一个包含 AI Toolkit 所有参数的字典。
from collections import OrderedDict
job_to_run = OrderedDict([
('job', 'extension'),
('config', OrderedDict([
# this name will be the folder and filename name
('name', 'my_first_flux_lora_v1'),
('process', [
OrderedDict([
('type', 'sd_trainer'),
('training_folder', OUTPUT_FOLDER),
('performance_log_every', 100),
('device', 'cuda:0'),
('trigger_word', TRIGGER_WORD),
('network', OrderedDict([
('type', 'lora'),
('linear', LORA_RANK),
('linear_alpha', LORA_RANK)
])),
('save', OrderedDict([
('dtype', 'float16'), # precision to save
('save_every', STEPS_SAVE), # save every this many steps
('max_step_saves_to_keep', 10) # how many intermittent saves to keep
])),
('datasets', [
# datasets are a folder of images. captions need to be txt files with the same name as the image
# for instance image2.jpg and image2.txt. Only jpg, jpeg, and png are supported currently
# images will automatically be resized and bucketed into the resolution specified
OrderedDict([
('folder_path', INPUT_FOLDER),
('caption_ext', 'txt'),
('caption_dropout_rate', 0.05), # will drop out the caption 5% of time
('shuffle_tokens', False), # shuffle caption order, split by commas
('cache_latents_to_disk', True), # leave this true unless you know what you're doing
('resolution', [512, 768, 1024]) # flux enjoys multiple resolutions
])
]),
('train', OrderedDict([
('batch_size', BATCHSIZE),
('steps', STEPS_TRAIN), # total number of steps to train 500 - 4000 is a good range
('gradient_accumulation_steps', 1),
('train_unet', True),
('train_text_encoder', False), # probably won't work with flux
('content_or_style', 'balanced'), # content, style, balanced
('gradient_checkpointing', True), # need the on unless you have a ton of vram
('noise_scheduler', 'flowmatch'), # for training only
('optimizer', 'adamw8bit'),
('lr', LEARNING_RATE),
# ema will smooth out learning, but could slow it down. Recommended to leave on.
('ema_config', OrderedDict([
('use_ema', True),
('ema_decay', 0.99)
])),
# will probably need this if gpu supports it for flux, other dtypes may not work correctly
('dtype', 'bf16')
])),
('model', OrderedDict([
# huggingface model name or path
('name_or_path', 'black-forest-labs/FLUX.1-dev'),
('is_flux', True),
('quantize', True), # run 8bit mixed precision
#('low_vram', True), # uncomment this if the GPU is connected to your monitors. It will use less vram to quantize, but is slower.
])),
('sample', OrderedDict([
('sampler', 'flowmatch'), # must match train.noise_scheduler
('sample_every', STEPS_SAMPLE), # sample every this many steps
('width', 1024),
('height', 1024),
('prompts', [
# you can add [trigger] to the prompts here and it will be replaced with the trigger word
'xray of a Boeing 747 [trigger]',
'xray of a woman holding a coffee cup [trigger]',
'xray of a dog [trigger]',
]),
('neg', ''), # not used on flux
('seed', 42),
('walk_seed', True),
('guidance_scale', 4),
('sample_steps', 20)
]))
])
])
])),
# you can add any additional meta info here. [name] is replaced with config name at top
('meta', OrderedDict([
('name', '[name]'),
('version', '1.0')
]))
])我们已准备好开始训练我们的适配器:
import os
import sys
sys.path.append('/workspace/ai-toolkit')
from toolkit.job import run_job
run_job(job_to_run)步骤 6 :将 LoRA 上传到 Hugging Face
训练后,将你的 LoRA 上传到 Hugging Face 以便于共享和访问。
!huggingface-cli upload HF_ACCOUNT/HF_REPO /workspace/output/my_first_flux_lora_v1 将 HF_ACCOUNT 和 HF_REPO 更改为你的 Hugging Face 用户名和将要创建的存储库的名称。
3、结果
我以 0.0001 的学习率对模型进行了 3000 步训练。最初,结果并不令人满意。
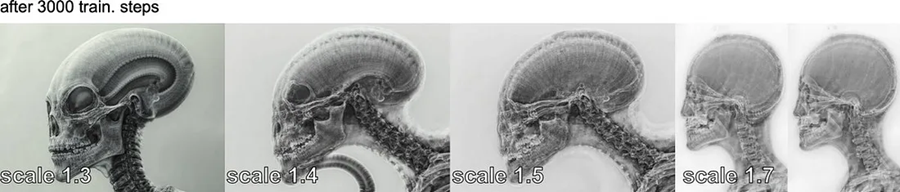
但是,我注意到在提示中添加“X 射线”可以显著改善结果。

这始终如一地给了我想要的 LoRA 1.0 规模。

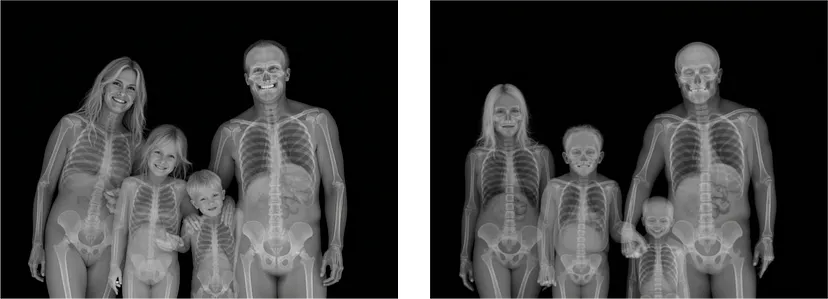
所有这些都是在没有触发词的情况下提示的。添加触发词会使图像更像 X-Ray,大部分是完美的正面/侧面视图,蓝色较少。

我注意到的另一件有趣的事情是,带有无法在 X-Ray 上表达的特征的提示会产生部分“真实”的图像。例如,“幸福的家庭”与“家庭”。
你可以在我的 Hugging Face 帐户上找到经过训练的 LoRA。
需要注意的一点是,FLUX1-dev 附带非商业许可证,这也适用于所有衍生产品,包括使用此模型训练的 LoRA。
4、结束语
在这篇博文中,我们介绍了在图像上训练 FLUX1-dev 的过程。我选择了 X 射线作为此示例,但你可以使用任何类型的图像,包括你自己的照片或特定风格。
默认参数是一个很好的起点,但你可能希望在更强大的 GPU 上使用更高的阶数,以确保模型学习你重视的所有特征。增加学习率可能会让你使用更少的步骤,具体取决于你的训练集。
原文链接:How to Train a FLUX.1 LoRA for $1
汇智网翻译整理,转载请标明出处
