Gemini问答数据集微调
本文介绍如何通过构建一个基于斯坦福问答数据集 (SQuAD 1.1) 微调的强大问答系统来增强 Gemini 1.5 Flash 的功能。

想象一下,一个基础模型不仅可以生成文本,而且在你的特定用例(例如,在企业文档和数据中进行问答)中表现出色。这就是微调语言模型的力量。
在本博客中,我们将展示如何通过构建一个基于斯坦福问答数据集 (SQuAD 1.1) 微调的强大问答系统来增强 Gemini 1.5 Flash 的功能。我们将引导你完成从数据准备到评估的整个过程,揭示针对你自己的 GenAI 应用程序微调 Gemini 的技术和最佳实践。
让我们开始吧!你可以在此笔记本中找到所有代码。
1、什么是微调?
为了提高基础模型在特定任务(例如问答)上的性能,我们可以利用一种称为“微调”的技术。这涉及在具有已知输入和输出(已标注)的样本上训练模型;我们称之为监督微调 (SFT)。有两种主要方法通常需要监督:
- 完全微调:更新模型的所有参数。这种方法需要大量计算资源,在实践中并不常用。
- 参数高效微调 (PEFT):冻结原始模型并仅更新一小部分新参数。更新更少的参数意味着它更高效、更快速,非常适合处理大型模型和有限的资源。
在这篇文章中,当我们谈论微调时,我们指的是 PEFT,尤其是 LoRA。LoRA(低秩自适应)是一种通过训练一组较小的参数来微调大型语言模型的技术,使其更高效、内存占用更少。
2、何时使用微调?
当你有特定任务和标注数据时,PEFT 是一种用于增强基础模型的强大技术。它在以下领域表现出色:
- 领域专业知识:使你的模型在法律或医学等领域更加专业化。
- 格式定制:根据特定结构定制输出,如 JSON 输出。
- 任务优化:提高总结等任务的性能。
- 行为控制:指导模型的响应风格(例如,简洁与详细)。
PEFT 效率高,通常需要的数据比其他方法少,并且可以通过较短的提示更轻松地与模型交互。但是,由于它修改了模型的底层权重,因此它不适合具有动态或不断变化的信息的任务——想想实时天气更新。在这些情况下,你可能需要使用诸如检索增强生成 (RAG) 或函数调用之类的东西,它们可以访问和处理实时数据。
考虑到这些因素,你如何选择最佳方法?重要的是要了解最佳路径取决于你对用例的独特需求、资源和目标。这些技术并不相互排斥,通常可以组合使用以获得更高的性能。让我们探索一个可以帮助指导你做出决定的框架:
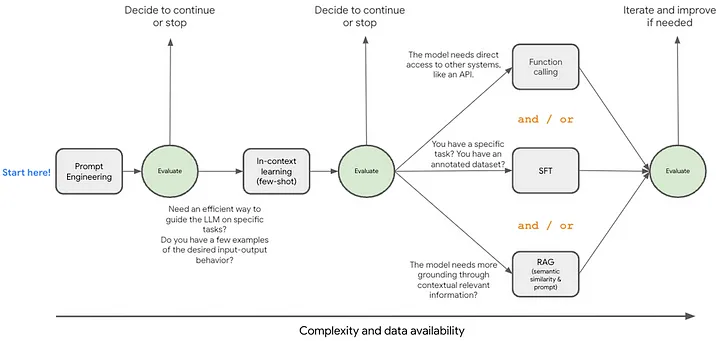
从提示工程开始。接下来,你可以通过添加一些示例来探索上下文学习。在探索更高级的技术(如 RAG、大型上下文窗口以及微调)之前,请确保进行适当的评估。
3、数据和用例
如前所述,对于 SFT,您需要有一个代表您的用例的特定任务和注释。在此示例中,我们使用斯坦福问答数据集 (SQuAD 1.1)。这个流行的阅读理解数据集由维基百科文章(上下文)上提出的问题组成,其中答案是相应段落中的一段文本(跨度)。有时,问题甚至可能无法回答,这增加了额外的挑战。
微调不仅仅是为了提高特定任务的性能;它还是一种控制输出行为的强大工具,如前所述。例如,请考虑以下内容:
- 上下文:黑豹队在分区赛中击败了西雅图海鹰队,半场领先 31-0,然后在下半场奋力反击,以 31-24 获胜,为一年前的淘汰报了仇。随后,黑豹队在 NFC 冠军赛中以 49-15 击败了亚利桑那红雀队,累计 487 码,迫使对方 7 次失误。
- 问题:卡罗莱纳队在分区赛中击败了谁?
- Gemini 1.5 Flash 响应:黑豹队在分区赛中击败了西雅图海鹰队。
- SQuAD 数据集:西雅图海鹰队
发现区别了吗?两个答案都是正确的,但 SQuAD 数据集的答案更简洁、更集中。微调可以帮助你调整模型的输出以满足你的特定需求。
4、数据准备
预处理是微调的关键步骤,它不仅仅是快速清理。研究表明,最重要的预处理步骤之一是重复数据删除,这涉及识别和删除重复的数据点。重复数据删除可以删除冗余数据,要点,确保你的模型从不同的示例中学习。
但这还不是全部!处理文本数据时,我们还需要考虑如何处理那些令人讨厌的不一致之处,例如大写字母、多余的空格和标点符号。不一致的数据会使你的模型感到困惑或弄乱你的评估,因此我们需要对其进行标准化。对于此示例,我们将删除多余的空格并将所有答案小写以确保一致性。
在此示例中,我们将删除多余的空格并将答案变为小写:
def normalize_answer(s):
"""Lower text and remove extra whitespace, but preserve newlines."""
def white_space_fix(text):
return ' '.join(text.split()) # Splits by any whitespace, including \n
def lower(text):
return text.lower()
return white_space_fix(lower(s))5、模型选择
使用 Vertex AI 对 Gemini 进行微调时,你可以选择功能强大的模型,每个模型都针对不同的需求进行了优化:
- Gemini 1.5 Pro:Google 针对通用用例的最佳性能模型。如果你需要在各种任务中获得最佳准确性,那么这就是你的首选。
- Gemini 1.5 Flash:专为速度和效率而设计。当你需要快速响应和具有成本效益的性能时,请选择此模型。
选择 Gemini 模型时,请考虑:
- 功能:从最适合你需求的模型开始。如果你需要高精度和复杂的推理,请使用 Gemini Pro。如果延迟和成本更重要,请尝试 Gemini Flash。
- 高效微调:在微调较大的模型之前,先在较小的模型(如 Gemini Flash)上测试数据。这有助于确保你的数据在投资微调较大的模型之前提高准确性。
在此示例中,我们将使用:
base_model = 'gemini-1.5-flash-002'6、建立基线
在微调语言模型之前,先建立性能基线。这意味着评估数据上的基础模型以了解其初始功能。在此示例中,我们使用基于计算的指标来衡量性能,将模型的输出与参考进行比较。对于此示例,我们将使用:
- 精确匹配 (EM):测量完美匹配的百分比。
- F1 分数:同时考虑精度和召回率以获得更细致入微的视图。
最好使用多种指标来全面了解模型的优势和劣势。你还可以查看 Vertex AI 平台上提供的评估功能,以帮助指导你的微调策略。
7、数据集格式
在微调 Gemini 时,你的训练数据需要采用特定格式:JSON 行文件,其中每行都是一个单独的样本。 确保你将文件存储在 Google Cloud Storage (GCS) 存储桶中。 JSONL 文件中的每一行都必须遵循以下架构:
{
"contents":[
{
"role":"user", # This indicates input content
"parts":[
{
"text":"Here goes the question and context"
}
]
},
{
"role":"model", # This indicates target content
"parts":[ # text only
{
"text":"Here goes the model response"
}
]
}
# ... repeat "user", "model" for multi turns.
]
}在此结构中:
- “contents”是内容。
- “contents”中的每个对象都有指定的角色:“user”代表用户的输入,“model”代表所需的模型输出。
- “parts”包含实际数据,如模型输入(问题、上下文和指令)和模型响应(答案)。
提示:对于多轮对话,只需在“内容”中重复“用户”和“模型”结构即可。
你可以选择让系统为你进行训练和验证拆分。然后,你只需提供一个 train_dataset(请参阅下面的代码),或者你可以自己决定将数据拆分为训练和验证。
8、启动微调作业。
接下来,你可以使用 Vertex AI SDK for Python 启动微调作业。以下是使用 sft.train() 方法启动微调作业的方法:
from vertexai.preview.tuning import sft
tuned_model_display_name = "fine-tuning-gemini-flash-qa-v01"
sft_tuning_job = sft.train(
source_model=base_model,
train_dataset=f"""{BUCKET_URI}/squad_train.jsonl""",
# # Optional:
validation_dataset=f"""{BUCKET_URI}/squad_validation.jsonl""",
tuned_model_display_name=tuned_model_display_name,
)关键参数:
source_model:微调之旅的起点。指定您将基于的预训练 Gemini 模型版本。train_dataset:模型学习的燃料。以 JSONL 格式提供训练数据的路径。validation_dataset(可选):一个有价值的检查点。此数据集允许你在训练期间评估模型的性能。tuned_model_display_name:为你的创作起一个令人难忘的名字!这将设置微调模型的显示名称。
我们将超参数保留为默认值。你可以尝试使用可选参数(如等级和学习率)来优化性能。
9、评估微调模型
训练后,我们在用于基线的相同测试数据集上评估了微调模型。这使我们能够直接比较性能并量化通过微调获得的改进。
9.1 调整进度
在调整过程中,你需要关注训练和验证指标,你可以在开始训练作业后在 Google Cloud Console 中找到这些指标,如下所示:
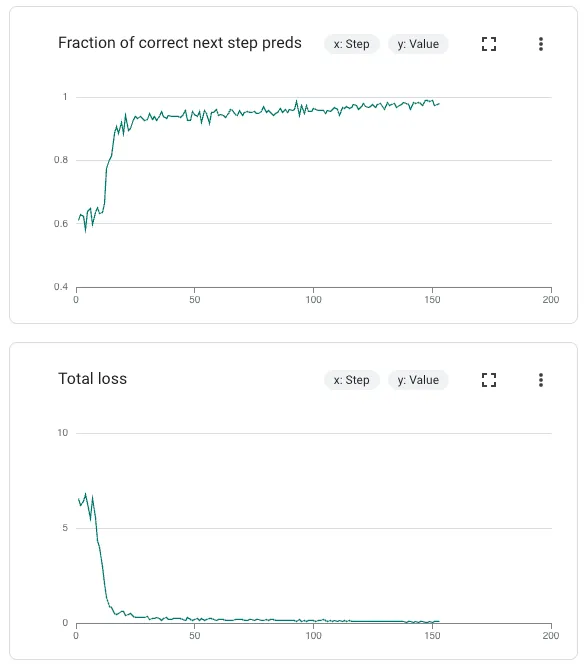
- 总损失衡量预测值和实际值之间的差异。训练损失减少表明模型正在学习。至关重要的是,还要观察验证损失。验证损失明显高于训练损失表明过度拟合。
- 正确的下一步预测分数衡量模型预测序列中下一个项目的准确性。该指标应随着时间的推移而增加,反映模型在顺序预测中的准确性不断提高。
此示例大约需要 20 分钟才能完成;但是,实际完成时间将根据你的具体用例和数据集大小而有所不同。
9.2 评估
评估经过微调的语言模型的性能对于理解其性能、检查点选择和超参数优化至关重要。评估对于生成模型来说可能具有挑战性,因为它们的输出通常是开放且富有创意的。为了全面了解性能,最好结合不同的评估方法,主要利用自动指标和基于模型的评估相结合,并可能通过人工评估进行校准。
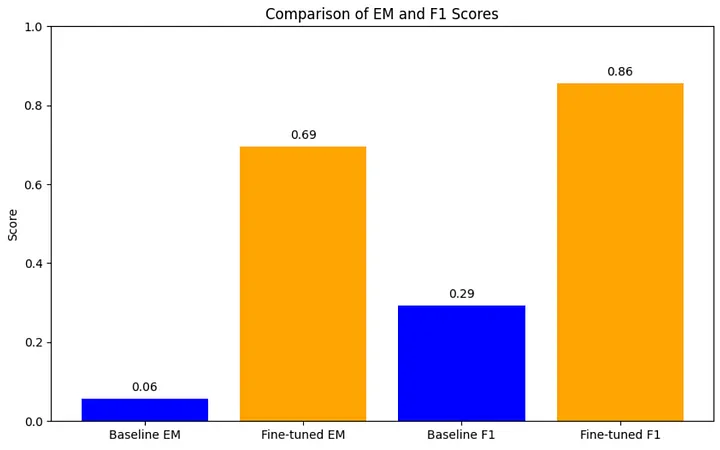
如上文所述,在这个例子中,我们使用 EM 和 F1。如你所见,针对这个特定的问答用例对 Gemini 1.5 Flash 进行微调,使我们在 F1 和 EM 上的性能得到了相当大的提升。当然,你可以利用提示工程和 RAG 来提高基线模型的性能。
9.3 使用经过微调的模型
微调工作完成后,你的模型就可以使用了!只需要加载经过微调的模型:
# tuned model endpoint name
tuned_model_endpoint_name = sft_tuning_job.tuned_model_endpoint_name
tuned_genai_model = GenerativeModel(tuned_model_endpoint_name)
# Test with the loaded model.
print("***Testing***")
print(tuned_genai_model.generate_content(contents=prompt))10、结束语
你现在已经掌握了微调 Gemini 的诀窍,可以将这个强大的基础模型变成一个专门的问答机器,供你参考。从准备数据到评估模型的性能,我们介绍了利用 Vertex AI 功能的基本步骤。你可以使用此笔记本开始使用。在同一个 repo 中,你还会找到一些其他关于微调的出色笔记本。
经过一点练习(也许再多喝几杯浓缩咖啡 ☕),你就可以微调 Gemini 以用于各种令人兴奋的应用程序。
原文链接:A Step-by-Step Guide to Fine-Tuning Gemini for Question Answering
汇智网翻译整理,转载请标明出处
