Gemini结构化输出API实践
最近我了解到Gemini的结构化输出API。与传统的多模态提示响应不同,它可以根据输入模式返回一个JSON负载。

大型语言模型已经引起了很大的兴奋,但我对一连串只是告诉你想要听到的内容的聊天机器人感到相当失望。我希望AI能做得更多,比如帮我完成任务,并帮助我理解数字世界,让我的生活更加宁静。
最近我了解到Gemini的结构化输出API。与传统的多模态提示响应不同,它可以根据输入模式返回一个JSON负载。
因此,我可以使用Gemini将非结构化的输入转换为结构化的输入,并将其作为更好程序的基础。
例如,我读了很多书。今年我已经读了28本书。我通过Goodreads跟踪我的阅读,但Goodreads不再支持API。我也经常使用纽约公共图书馆,但它也没有API。我希望能够创建一个系统,从Goodreads获取我的待读书籍并请求这些书籍从图书馆。
为此,我需要定义一种标准格式来表示Goodreads和NYPL上的书籍。除了书籍,我还希望LLM能够以结构化的方式理解任何内容。
所以我转向了schema.org,这是一个旨在帮助定义语义网的项目。这些类型已经在网络上广泛使用,并提供了各种对象的通用词汇表,包括Book。
我可以轻松地从他们的GitHub存储库中的单个JSON文件中提取所有现有的模式。这种格式是JSON,尽管它使用了大量的链接和属性来表示每个属性或类型:
{
"@id": "schema:illustrator",
"@type": "rdf:Property",
"rdfs:comment": "The illustrator of the book.",
"rdfs:label": "illustrator",
"schema:domainIncludes": {
"@id": "schema:Book"
},
"schema:rangeIncludes": {
"@id": "schema:Person"
}
},
{
"@id": "schema:Book",
"@type": "rdfs:Class",
"rdfs:comment": "A book.",
"rdfs:label": "Book",
"rdfs:subClassOf": {
"@id": "schema:CreativeWork"
}
},
这并不是特别有帮助,因为我需要将这些转换成更标准的JSON模式格式,以便在Gemini API要求中提供。
所以我开始编写一个简短的脚本来处理这个文件。
const schemas = require('../src/schemaorg-jsonld.json')
const graph = schemas['@graph']
const geminiGraph: Record<string, Schema> = {}
const possibleTypes: string[] = []
const simpleDataTypes = {
'schema:Text': SchemaType.STRING,
'schema:URL': SchemaType.STRING,
'schema:Boolean': SchemaType.BOOLEAN,
'schema:Number': SchemaType.NUMBER,
'schema:Integer': SchemaType.INTEGER,
'schema:Time': SchemaType.STRING, // Timestring
'schema:DateTime': SchemaType.STRING, // Timestring
'schema:Date': SchemaType.STRING, // Timestring
}
// First pass creates an entry for each thing in the graph
for (const property of graph) {
const id = property['@id']
if (simpleDataTypes[id]) {
geminiGraph[id] = {
type: simpleDataTypes[id],
description: property['rdfs:comment'] || property['rdfs:label'] || "",
}
continue
}
geminiGraph[id] = {
type: simpleDataTypes[property['@type']] ?? SchemaType.OBJECT,
description: property['rdfs:comment'] || property['rdfs:label'] || "",
}
// Do this now to begin the process of memory mapping
if (!simpleDataTypes[property['@type']]) {
geminiGraph[id].properties = {}
}
if (property['rdfs:subClassOf']) {
if (property['rdfs:subClassOf']['@id'] === 'schema:Enumeration') {
// This is an enum
geminiGraph[property['@id']].type = SchemaType.STRING
geminiGraph[property['@id']].enum = []
continue
}
}
}
// Next pass attaches entries in the graph
for (const property of graph) {
if (geminiGraph[property['@id']].type !== 'object') {
continue
}
const potentialTypes: string[] = (() => {
const sp = property['schema:rangeIncludes']
if (sp === undefined) return [0] // DataType
if (Array.isArray(sp)) {
return sp.map(x => x['@id'])
}
return Object.values(sp)
})()
const type = potentialTypes[0]
// for (const type of potentialTypes) {
const id = (() => {
const origId = property['@id']
if (potentialTypes.length === 1) {
return origId
}
// return `${origId}_${type}`
return `${origId}`
})()
geminiGraph[id] = {...geminiGraph[property['@id']]}
if (property['schema:rangeIncludes']) {
const ref = simpleDataTypes[type] ?
{ type: simpleDataTypes[type] } :
geminiGraph[type]
if (geminiGraph[id].properties) {
geminiGraph[id].properties![type] = ref
} else {
geminiGraph[id].properties = {
[type]: ref
}
}
}
const superProperties: string[] = (() => {
const sp = property['schema:domainIncludes']
if (sp === undefined) return []
if (Array.isArray(sp)) {
return sp.map(x => x['@id'])
}
return Object.values(sp)
})()
for (const superProperty of superProperties) {
if (!geminiGraph[superProperty].properties) {
geminiGraph[superProperty]!.properties = {
[id]: geminiGraph[id]
}
} else {
geminiGraph[superProperty]!.properties![id] = geminiGraph[id]
}
}
// }
}
// Do an enum pass
for (const property of graph) {
const ptype = property['@type']
if (geminiGraph[ptype]?.enum !== undefined) {
geminiGraph[ptype].enum?.push(property['rdfs:label'])
}
}
function subclassPass(property: any) {
const log = false
const subClassOf = (() => {
const sp = property['rdfs:subClassOf']
if (sp === undefined) return []
if (Array.isArray(sp)) {
return sp.map(x => x['@id'])
}
return Object.values(sp)
})()
if (log) { console.log('sarr', subClassOf) }
for (const sco of subClassOf) {
if (log) { console.log(sco) }
if (log) { console.log(geminiGraph[sco]) }
if (sco === 'schema:Enumeration') return
if (!geminiGraph[sco]) continue
const graphSco = graph.find(x => x['@id'] === sco)
if (graphSco['rdfs:subClassOf']) {
if (log) { console.log('scp', sco) }
subclassPass(graphSco)
}
const superclass = geminiGraph[sco]
if (!superclass || !superclass.properties) continue
if (!geminiGraph[property['@id']].properties) {
geminiGraph[property['@id']].properties = {}
}
for (const [k, v] of Object.entries<Schema>(superclass.properties ?? {})) {
const pid = property['@id']
if (log) { console.log('kv', k) }
geminiGraph[pid]!.properties![k] = v
}
}
}
// Do a subclass pass
for (const property of graph) {
if (!property['rdfs:subClassOf']) continue
subclassPass(property)
}
const schema = 'schema:Book'
const jsonout = geminiGraph[schema]
console.log(JSON.stringify(jsonout))
经过一些工作和迭代,我使用内存引用确保顺序不重要。最后我还需要一次迭代来正确处理枚举。这虽然不是最高效的脚本,但只需要运行一次作为预处理器来转换所有类型。然后在生产环境中可以使用这些类型。
逐段运行脚本,它有效。当我尝试运行JSON.stringify时,我遇到了一个意外错误。它提到了循环引用。这是怎么回事。
schema.org类型的缺点在于它们过于灵活且强类型。这在某些方面很好,但使得序列化成为一个问题。
如果你查看Book类型,你会看到像Boolean abridged和Text isbn这样的属性。它继承了CreativeWork类型的属性,如Number copyrightYear,以及Thing类型的属性,如Text name。这也意味着它带来了许多优先级较低的属性,如Text interactivityType。这导致了一个非常冗长的类型,但这些类型可以忽略,不是大问题。
更大的问题是,一本书有一个名为Person illustrator的属性,指向一个规范的Person类型。这个person类型有一个属性Person children。当一个人是另一个人的后代时,如果你尝试序列化整个结构,会导致无限递归。这很糟糕。
不幸的是,目前还没有很好的解决办法。我投入了很多想法。
为了尝试一下,我尝试将很多类型硬编码为字符串。因为虽然我的书有一个Person插图者很好,将数据类型简化为字符串虽然解决了循环引用的问题,但也导致了信息的丢失。经过一番挣扎,我最终决定我的方法从根本上是有缺陷的。尽管我可以使用Schema类型来表示复杂的数据结构,但实际操作中却发现这种方法难以处理大量的丰富模式类型,从而引发了一系列问题。
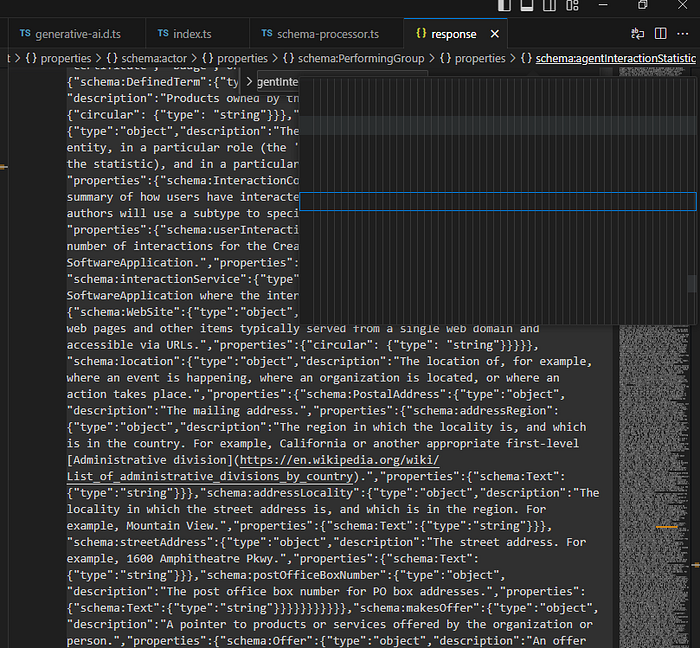
我尝试了几种库来解决循环引用的问题,并试图切断所有循环引用,但最终结果仍然是一个混乱且冗长的JSON块,这使得Gemini难以处理。这是我在AI Studio中的截图,经过几个小时的努力后,我决定放弃这种做法。
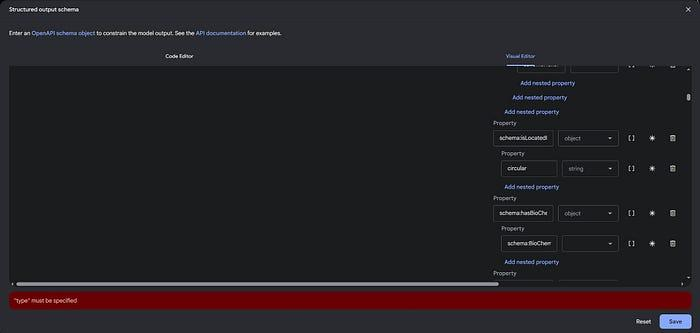
经过长时间的挣扎,我终于意识到我的方法存在根本性的问题。虽然可以使用Schema类型来表示复杂的数据结构,但在实际操作中发现这种方法难以处理大量的丰富模式类型,从而引发了一系列问题。
const simpleDataTypes = {
'schema:Text': SchemaType.STRING,
'schema:URL': SchemaType.STRING,
'schema:Boolean': SchemaType.BOOLEAN,
'schema:Number': SchemaType.NUMBER,
'schema:Integer': SchemaType.INTEGER,
'schema:Time': SchemaType.STRING, // Timestring
'schema:DateTime': SchemaType.STRING, // Timestring
'schema:Date': SchemaType.STRING, // Timestring
'schema:ListItem': SchemaType.STRING, // Workaround
'schema:DefinedTerm': SchemaType.STRING, // Workaround
'schema:Taxon': SchemaType.STRING, // Workaround
'schema:BioChemEntity': SchemaType.STRING, // Workaround
'schema:DefinedTermSet': SchemaType.STRING, // Workaround
'schema:ImageObject': SchemaType.STRING, // Workaround
'schema:MediaObject': SchemaType.STRING, // Workaround
'schema:TextObject': SchemaType.STRING, // Workaround
'schema:VideoObject': SchemaType.STRING, // Workaround
'schema:AudioObject': SchemaType.STRING, // Workaround
'schema:Language': SchemaType.STRING, // Workaround
'schema:QuantitativeValue': SchemaType.NUMBER, // Workaround
'schema:AboutPage': SchemaType.STRING, // Workaround
'schema:Audience': SchemaType.STRING, // Workaround
'schema:Claim': SchemaType.STRING, // Workaround
'schema:Comment': SchemaType.STRING, // Workaround
'schema:bioChemInteraction': SchemaType.STRING, // Workaround
'schema:bioChemSimilarity': SchemaType.STRING, // Workaround
'schema:hasBioChemEntityPart': SchemaType.STRING, // Workaround
'schema:softwareAddOn': SchemaType.STRING, // Workaround
'schema:worksFor': SchemaType.STRING, // Workaround
'schema:parents': SchemaType.STRING, // Workaround
'schema:advanceBookingRequirement': SchemaType.STRING, // Workaround
'schema:potentialAction': SchemaType.STRING, // Workaround
'schema:publisherImprint': SchemaType.STRING, // Workaround
'schema:subjectOf': SchemaType.STRING, // Workaround
'schema:offeredBy': SchemaType.STRING, // Workaround
'schema:interactionType': SchemaType.STRING, // Workaround
'schema:address': SchemaType.STRING, // Workaround
'schema:spatial': SchemaType.STRING, // Workaround
'schema:geoTouches': SchemaType.STRING, // Workaround
'schema:sourceOrganization': SchemaType.STRING, // Workaround
'schema:mainEntityOfPage': SchemaType.STRING, // Workaround
'schema:isBasedOnUrl': SchemaType.STRING, // Workaround
'schema:servicePostalAddress': SchemaType.STRING, // Workaround
'schema:publishedOn': SchemaType.STRING, // Workaround
'schema:diversityStaffingReport': SchemaType.STRING, // Workaround
'schema:archivedAt': SchemaType.STRING, // Workaround
'schema:publishingPrinciples': SchemaType.STRING, // Workaround
'schema:occupationLocation': SchemaType.STRING, // Workaround
'schema:educationRequirements': SchemaType.STRING, // Workaround
'schema:performerIn': SchemaType.STRING, // Workaround
'schema:correctionsPolicy': SchemaType.STRING, // Workaround
'schema:hostingOrganization': SchemaType.STRING, // Workaround
'schema:composer': SchemaType.STRING, // Workaround
'schema:funding': SchemaType.STRING, // Workaround
'schema:recordedAt': SchemaType.STRING, // Workaround
'schema:material': SchemaType.STRING, // Workaround
'schema:license': SchemaType.STRING, // Workaround
'schema:usageInfo': SchemaType.STRING, // Workaround
'schema:producer': SchemaType.STRING, // Workaround
'schema:countryOfOrigin': SchemaType.STRING, // Workaround
'schema:exampleOfWork': SchemaType.STRING, // Workaround
'schema:workExample': SchemaType.STRING, // Workaround
'schema:hasCertification': SchemaType.STRING, // Workaround
'schema:hasCredential': SchemaType.STRING, // Workaround
'schema:containedIn': SchemaType.STRING, // Workaround
'schema:department': SchemaType.STRING, // Workaround
'schema:makesOffer': SchemaType.STRING, // Workaround
'schema:translationOfWork': SchemaType.STRING, // Workaround
'schema:serviceSmsNumber': SchemaType.STRING, // Workaround
'schema:subEvent': SchemaType.STRING, // Workaround
'schema:eventSchedule': SchemaType.STRING, // Workaround
'schema:shippingOrigin': SchemaType.STRING, // Workaround
'schema:validForMemberTier': SchemaType.STRING, // Workaround
'schema:openingHoursSpecification': SchemaType.STRING, // Workaround
'schema:geoCrosses': SchemaType.STRING, // Workaround
'schema:contributor': SchemaType.STRING, // Workaround
'schema:accountablePerson': SchemaType.STRING, // Workaround
'schema:affiliation': SchemaType.STRING, // Workaround
'schema:funder': SchemaType.STRING, // Workaround
'schema:alumniOf': SchemaType.STRING, // Workaround
'schema:brand': SchemaType.STRING, // Workaround
'schema:memberOf': SchemaType.STRING, // Workaround
'schema:recordedIn': SchemaType.STRING, // Workaround
'schema:deathPlace': SchemaType.STRING, // Workaround
'schema:homeLocation': SchemaType.STRING, // Workaround
'schema:workLocation': SchemaType.STRING, // Workaround
'schema:locationCreated': SchemaType.STRING, // Workaround
'schema:spatialCoverage': SchemaType.STRING, // Workaround
'schema:attendee': SchemaType.STRING, // Workaround
'schema:workFeatured': SchemaType.STRING, // Workaround
'schema:workPerformed': SchemaType.STRING, // Workaround
'schema:itemOffered': SchemaType.STRING, // Workaround
'schema:availableAtOrFrom': SchemaType.STRING, // Workaround
'schema:parentOrganization': SchemaType.STRING, // Workaround
'schema:manufacturer': SchemaType.STRING, // Workaround
'schema:isRelatedTo': SchemaType.STRING, // Workaround
'schema:birthPlace': SchemaType.STRING, // Workaround
'schema:character': SchemaType.STRING, // Workaround
'schema:illustrator': SchemaType.STRING, // Workaround
'schema:sponsor': SchemaType.STRING, // Workaround
'schema:author': SchemaType.STRING, // Workaround
'schema:creator': SchemaType.STRING, // Workaround
'schema:editor': SchemaType.STRING, // Workaround
'schema:maintainer': SchemaType.STRING, // Workaround
'schema:provider': SchemaType.STRING, // Workaround
'schema:translator': SchemaType.STRING, // Workaround
'schema:publisher': SchemaType.STRING, // Workaround
'schema:sdPublisher': SchemaType.STRING, // Workaround
'schema:seller': SchemaType.STRING, // Workaround
'schema:contentLocation': SchemaType.STRING, // Workaround
'schema:publishedBy': SchemaType.STRING, // Workaround
'schema:director': SchemaType.STRING, // Workaround
'schema:directors': SchemaType.STRING, // Workaround
'schema:attendees': SchemaType.STRING, // Workaround
'schema:founder': SchemaType.STRING, // Workaround
'schema:members': SchemaType.STRING, // Workaround
'schema:actor': SchemaType.STRING, // Workaround
'schema:actors': SchemaType.STRING, // Workaround
'schema:organizer': SchemaType.STRING, // Workaround
'schema:copyrightHolder': SchemaType.STRING, // Workaround
'schema:musicBy': SchemaType.STRING, // Workaround
'schema:partOfEpisode': SchemaType.STRING, // Workaround
'schema:partOfSeason': SchemaType.STRING, // Workaround
'schema:partOfSeries': SchemaType.STRING, // Workaround
'schema:productionCompany': SchemaType.STRING, // Workaround
'schema:performer': SchemaType.STRING, // Workaround
'schema:performers': SchemaType.STRING, // Workaround
'schema:eligibleTransactionVolume': SchemaType.STRING, // Workaround
'schema:superEvent': SchemaType.STRING, // Workaround
'schema:subEvents': SchemaType.STRING, // Workaround
'schema:video': SchemaType.STRING, // Workaround
'schema:workTranslation': SchemaType.STRING, // Workaround
'schema:isPartOf': SchemaType.STRING, // Workaround
'schema:hasPart': SchemaType.STRING, // Workaround
'schema:isVariantOf': SchemaType.STRING, // Workaround
'schema:isSimilarTo': SchemaType.STRING, // Workaround
'schema:isAccessoryOrSparePartFor': SchemaType.STRING, // Workaround
'schema:predecessorOf': SchemaType.STRING, // Workaround
'schema:successorOf': SchemaType.STRING, // Workaround
'schema:model': SchemaType.STRING, // Workaround
'schema:isConsumableFor': SchemaType.STRING, // Workaround
'schema:sdLicense': SchemaType.STRING, // Workaround
'schema:warranty': SchemaType.STRING, // Workaround
'schema:hasProductReturnPolicy': SchemaType.STRING, // Workaround
'schema:hasMerchantReturnPolicy': SchemaType.STRING, // Workaround
'schema:mentions': SchemaType.STRING, // Workaround
'schema:educationalAlignment': SchemaType.STRING, // Workaround
'schema:about': SchemaType.STRING, // Workaround
'schema:mainEntity': SchemaType.STRING, // Workaround
'schema:additionalProperty': SchemaType.STRING, // Workaround
'schema:interactionStatistic': SchemaType.NUMBER, // Workaround
}
``````typescript
const simpleString = (description: string) => ({
type: SchemaType.STRING,
description,
})
const simpleBool = (description: string) => ({
type: SchemaType.BOOLEAN,
description,
})
schemaGraph['bookFormatType'] = simpleEnum('The publication format of the book.', [
'AudiobookFormat', 'EBook', 'GraphicNovel',
'Hardcover', 'Paperback',
])
schemaGraph['Book'] = {
type: SchemaType.OBJECT,
properties: {
...schemaGraph['creativeWork'].properties,
abridged: simpleBool('Indicates whether the book is an abridged edition.'),
bookEdition: simpleString('The edition of the book.'),
bookFormat: schemaGraph['bookFormatType'],
illustrator: simpleString('The illustrator of the book.'),
isbn: simpleString('The ISBN of the book.'),
numberOfPages: simpleInt('The number of pages in the book.'),
}
}
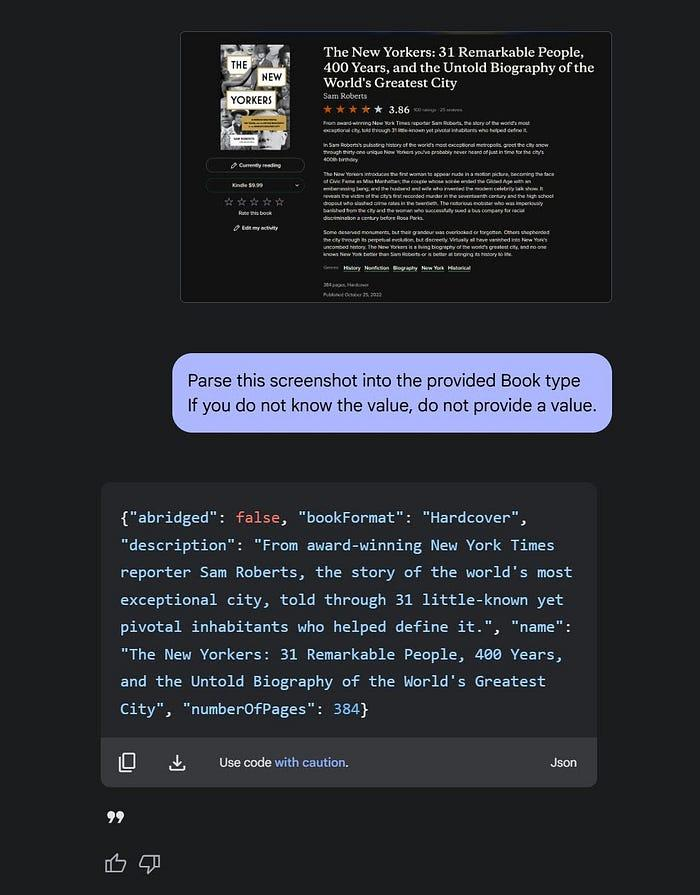
最后,我可以从Goodreads截图,并让Gemini正确地将其转换为高质量的JSON对象。
但我还需要超越这一点。我需要进行一次初步处理,将输入内容和截图中的对象底层类型提取出来。它可能不总是Book。所以我必须从所有驼峰命名的类型中创建一个枚举,并将其作为初始提示。
const typeEnums = {
type: SchemaType.STRING,
description: 'The best possible type that best represents the input',
enum: Object.keys(schemaGraph).filter(x => {
const x0 = x.substring(0, 1)
return x0 === x0.toUpperCase()
})
}
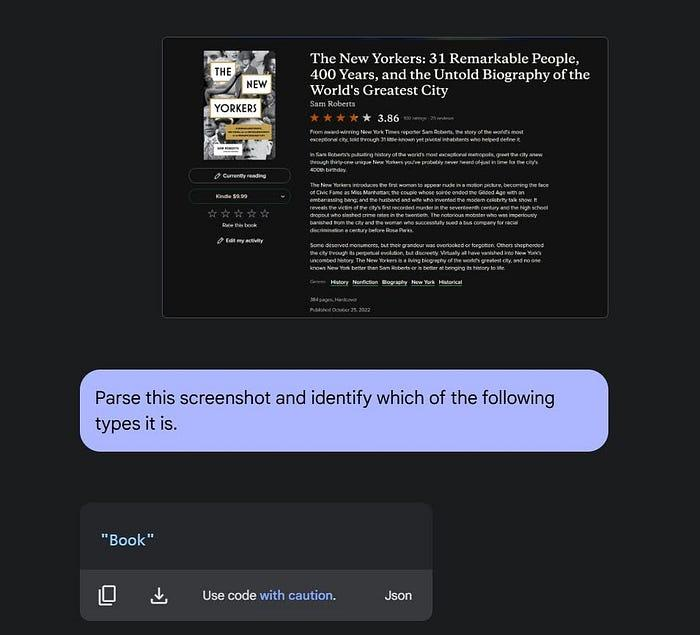
由于它正确识别了截图中的内容为Book,我可以继续进行第二次查询,获取Book模式并得到JSON输出。
这个初步的工作详细介绍了我在使用AI开始构建新的语义网络方面的一些早期工作。使用LLM将非结构化数据转换为结构化数据使我能够更容易地继续推进我的项目。通过标准化一组有限的标准类型,我可以整合不同的网站,并使数据从一个地方迁移到另一个地方变得更加容易。
我很快会发布另一篇后续文章,进一步探讨这项初步工作的内容以及我所学到的东西。
原文链接:Using Gemini API for the Semantic Web
汇智网翻译整理,转载请标明出处
