Gemma 3 270M本地微调指南
Gemma 3 270M是一个超高效的本地AI模型。今天,让我们学习如何微调这个模型,让它在下棋和预测下一步动作方面变得非常聪明。

谷歌发布了Gemma 3 270M,一个新的模型用于超高效的本地AI!
你可以在仅0.5 GB RAM上本地运行它。
今天,让我们学习如何微调这个模型,让它在下棋和预测下一步动作方面变得非常聪明。
我们的技术栈:
- Unsloth用于高效的微调。
- HuggingFace transformers用于本地运行。
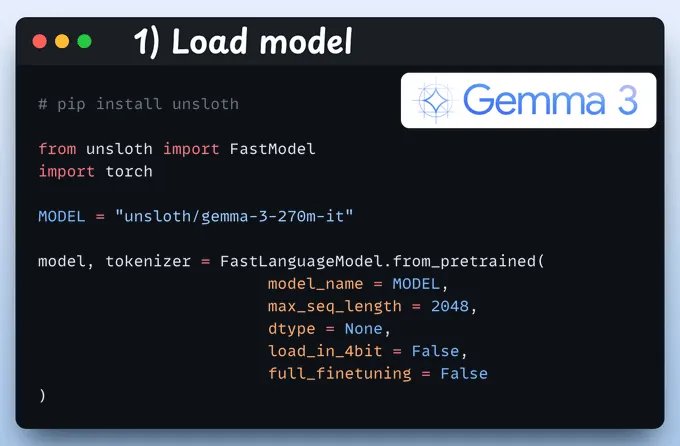
1、加载模型
我们首先使用Unsloth加载Gemma 3 270M及其分词器。
2、定义LoRA配置
我们将使用LoRA进行高效的微调。

为此,我们使用Unsloth的PEFT并指定:
- 模型
- LoRA低秩(r)
- 微调层(target_modules)
3、加载数据集
我们将微调Gemma 3,使其在下棋方面变得极其聪明。
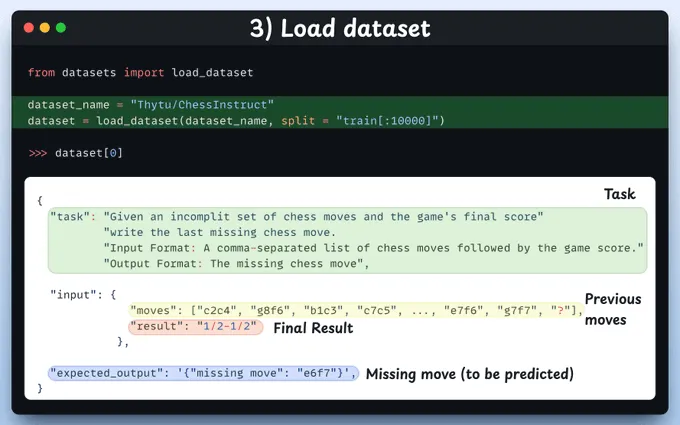
给定一组之前的移动(缺少一个移动)和最终结果,它必须预测缺失的移动。
为了做到这一点,我们使用HuggingFace的ChessInstruct数据集。
4、准备数据集
接下来,我们使用对话风格的数据集来微调Gemma 3。
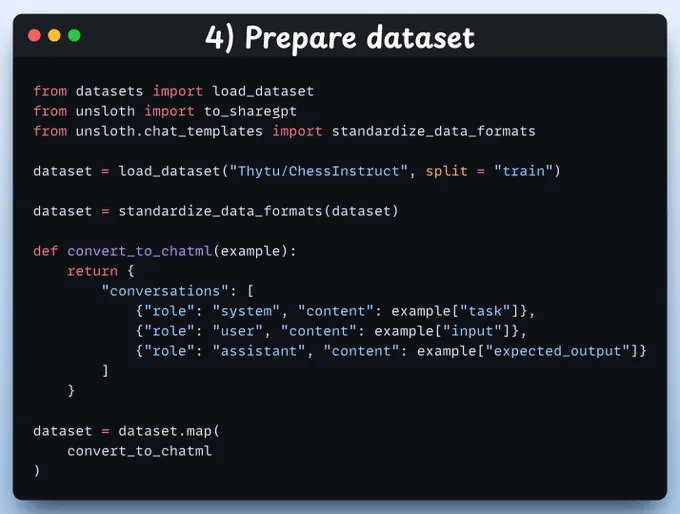
standardize_data_formats方法将数据集转换为适合微调的正确格式!
5、定义Trainer
在这里,我们通过指定训练配置(如学习率、模型、分词器等)创建一个Trainer对象。

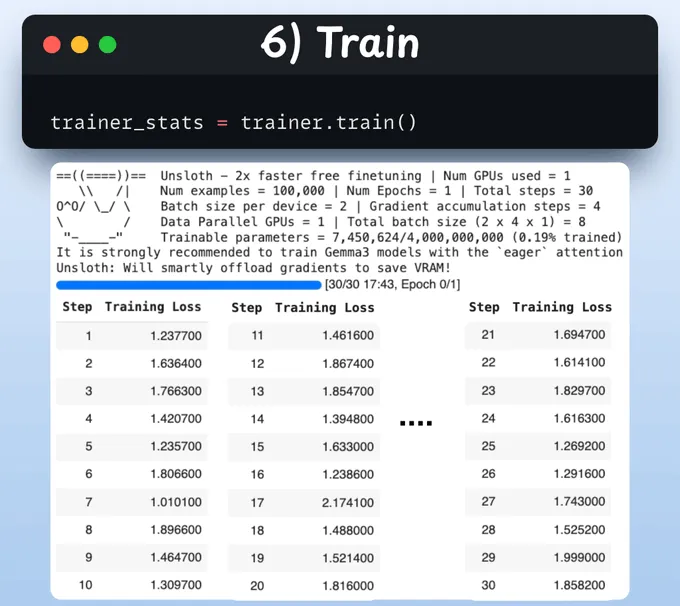
6、训练
完成这些后,我们开始训练。
损失通常随着步骤减少,这意味着模型被正确地微调了。
最后,这张图片显示了微调前后提示LLM的情况:

微调后,模型能够找到确切的缺失棋步,而不是随机生成一些棋步。
这很简单,不是吗?
原文链接:Fine-tuning Gemma 3 270M Locally
汇智网翻译整理,转载请标明出处
