Gemma 3:多语言多模态长上下文
Gemma 3是 Gemma 系列模型的新一代。这些模型的参数范围从 1B 到 27B,具有高达 128k 个标记的上下文窗口,可以处理图像和文本,并支持 140 多种语言。

今天,Google 发布了 Gemma 3,这是他们 Gemma 系列模型的新一代。这些模型的参数范围从 1B 到 27B,具有高达 128k 个标记的上下文窗口,可以处理图像和文本,并支持 140 多种语言。
现在就试试 Gemma 3 吧 👉🏻 Gemma 3 空间
| Gemma 2 | Gemma 3 | |
|---|---|---|
| 参数大小变体 | - 2B - 9B - 27B | - 1B - 4B - 12B - 27B |
| 上下文窗口长度 | 8k | - 32k (1B) - 128k (4B, 12B, 27B) |
| 多模态(图像和文本) | ❌ | - ❌ (1B) - ✅ (4B, 12B, 27B) |
| 多语言支持 | – | 英语 (1B) +140 种语言 (4B, 12B, 27B) |
所有模型都在 Hub 上可访问,并与 Hugging Face 生态系统紧密集成。
发布了预训练和指令调优两种模型。Gemma-3-4B-IT 在基准测试中超过了 Gemma-2-27B IT,而 Gemma-3-27B-IT 超过了 Gemini 1.5-Pro。
1、什么是 Gemma 3?
Gemma 3 是 Google 最新的开放权重大型语言模型。它有四种尺寸,分别是 10 亿、40 亿、120 亿 和 270 亿 参数,包含基础(预训练)和指令调优版本。Gemma 3 支持 多模态!40 亿、120 亿和 270 亿参数的模型可以处理 图像 和 文本,而 10 亿参数的模型仅限于文本。
输入上下文窗口长度从 Gemma 2 的 8k 增加到 32k 对于 10 亿参数的模型,对于其他模型则增加到 128k。与其他视觉语言模型一样,Gemma 3 根据用户输入生成文本响应,输入可能包括文本和可选的图像。示例用途包括问答、分析图像内容、总结文档等。
| 预训练 | 指令调优 | 多模态 | 多语言支持 | 输入上下文窗口 |
|---|---|---|---|---|
| gemma-3-1b-pt | gemma-3-1b-it | ❌ | 英语 | 32K |
| gemma-3-4b-pt | gemma-3-4b-it | ✅ | +140 种语言 | 128K |
| gemma-3-12b-pt | gemma-3-12b-it | ✅ | +140 种语言 | 128K |
| gemma-3-27b-pt | gemma-3-27b-it | ✅ | +140 种语言 | 128K |
虽然这些是多模态模型,但可以通过不加载视觉编码器来将其用作纯文本模型(作为 LLM)。我们将在推理部分详细讨论这一点。
2、Gemma 3 的技术增强
Gemma 3 相比 Gemma 2 的三大核心增强是:
- 更长的上下文长度
- 多模态
- 多语言支持
在本节中,我们将介绍导致这些增强的技术细节。从了解 Gemma 2 开始,探索实现这些模型改进所必需的内容会非常有趣。这个练习将帮助你思考 Gemma 团队的思路并欣赏其中的细节!
2.1 更长的上下文长度
通过高效地扩展上下文长度至 128k 个标记,无需重新训练模型。相反,模型使用 32k 序列进行预训练,只有 4B、12B 和 27B 参数的模型在预训练结束时扩展到 128k 个标记,从而节省大量计算。位置嵌入(如 RoPE)进行了调整——从 Gemma 2 的 10k 基频升级为 Gemma 3 的 1M,并且按 8 倍的比例缩放以适应更长的上下文。
KV 缓存管理通过 Gemma 2 的滑动窗口交错注意力进行优化。超参数被调整为交错 5 个局部层和 1 个全局层(之前是 1:1),并将窗口大小减少到 1024 个标记(从 4096 减少)。关键的是,在不降低困惑度的情况下实现了内存节省。
2.2 多模态
Gemma 3 模型使用 SigLIP 作为图像编码器,该编码器将图像编码成标记,然后输入到语言模型中。视觉编码器接受大小为 896x896 的方形图像。固定的输入分辨率使得处理非方形纵横比和高分辨率图像变得困难。为了在推理期间解决这些限制,图像可以自适应裁剪,每个裁剪后的图像再调整为 896x896 并由图像编码器编码。这种算法称为 pan and scan,有效地使模型能够放大并关注图像中的小细节。
类似于 PaliGemma,Gemma 3 对文本和图像输入的注意力机制不同。文本使用单向注意力,模型只关注序列中的前一个词。另一方面,图像得到全注意力,没有任何掩码,允许模型以 双向 方式查看图像的每一部分,使其对视觉输入有一个完整、无限制的理解。
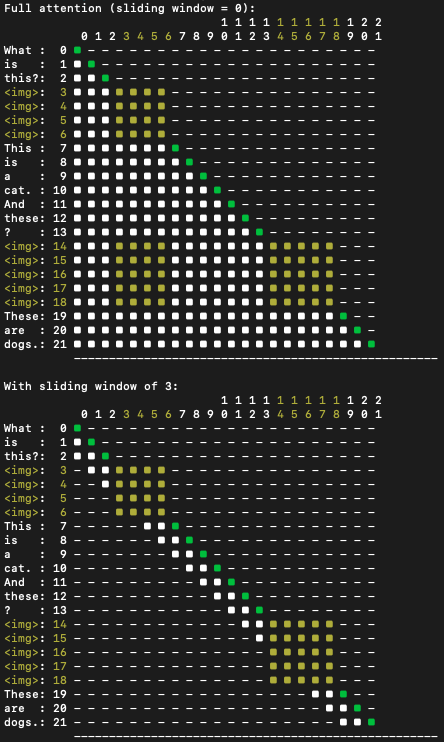
可以在下面的图中看到,图像标记获得了双向注意力(整个正方形都被点亮),而文本标记则有因果注意力。它还展示了注意力如何与滑动窗口算法一起工作。
2.3 多语言支持
为了让大型语言模型支持多种语言,预训练数据集包含了更多的语言。Gemma 3 的数据集包含 两倍 的多语言数据,以提高语言覆盖率。
为了适应这些变化,分词器与 Gemini 2.0 相同。这是一个包含 262K 条目的 SentencePiece 分词器。新的分词器显著提高了对中文、日文和韩文文本的编码,但英文和代码的标记数量略有增加。
对于好奇心强的人,这里有一份关于 Gemma 3 的 技术报告,深入探讨这些增强功能。
3、Gemma 3 评估
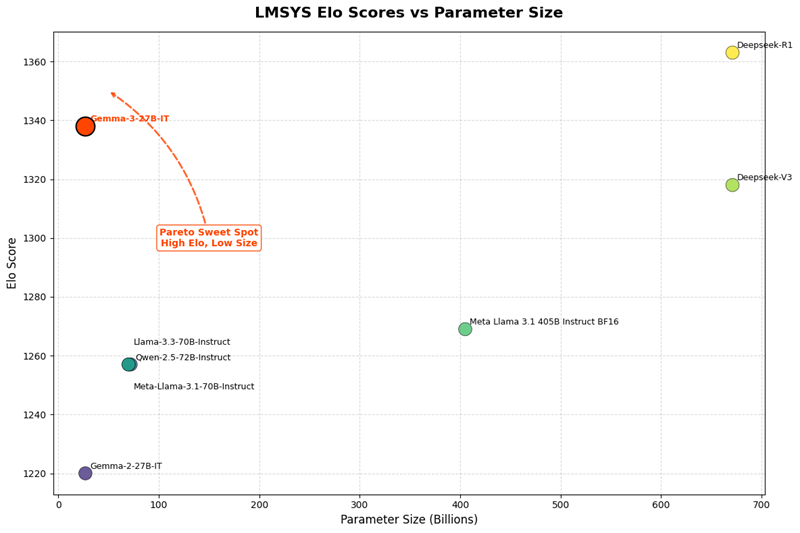
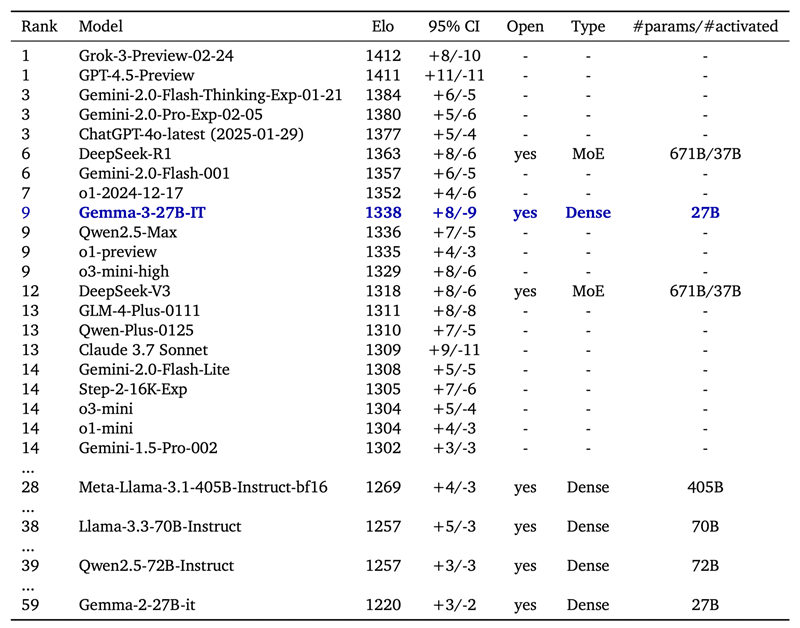
LMSys Elo 分数是一个数字,根据模型在双人竞赛中的表现(由人类偏好评判)来排名。在 LMSys Chatbot Arena 中,Gemma 3 27B IT 报告的 Elo 分数为 1339,并在包括领先封闭模型在内的前十名模型中排名。该分数与 o1-preview 相当,并且高于其他 非思维 开放模型。这个分数是在 Gemma 3 仅处理文本输入时获得的,就像表中的其他 LLM 一样。
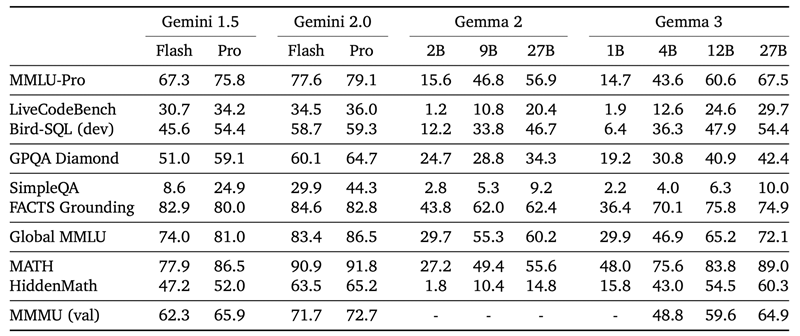
Gemma 3 在 MMLU-Pro(27B: 67.5)、LiveCodeBench(27B: 29.7)和 Bird-SQL(27B: 54.4)等基准测试中表现出竞争力,与封闭的 Gemini 模型相比性能相当。GPQA Diamond(27B: 42.4)和 MATH(27B: 69.0)等测试突显了其推理和数学能力,而 FACTS Grounding(27B: 74.9)和 MMMU(27B: 64.9)则展示了其强大的事实接地能力。
4、在transformers 中进行推理
Gemma 3 在 transformers 中提供了开箱即用的支持。您只需从 Gemma 3 的稳定版本中安装 transformers。
$ pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-34.1 使用 pipeline 进行推理
使用 Gemma 3 最简单的方法是使用 transformers 中的 pipeline 抽象层。
最佳效果使用 bfloat16 数据类型。否则质量可能会下降。import torch
from transformers import pipeline
pipe = pipeline(
"image-text-to-text",
model="google/gemma-3-4b-it", # "google/gemma-3-12b-it", "google/gemma-3-27b-it"
device="cuda",
torch_dtype=torch.bfloat16
)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])
- 图像

- 提示:糖果上是什么动物?
- 生成:让我们分析一下糖果!糖果上的动物是一只乌龟。你可以清楚地看到乌龟的壳和头以及腿印在表面上。
可以交错插入图像和文本。为此,只需在要插入图像的地方切断输入文本,并插入如下所示的图像块。
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]},
{
"role": "user",
"content": [
{"type": "text", "text": "I'm already using this supplement "},
{"type": "image", "url": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/IMG_3018.JPG"},
{"type": "text", "text": "and I want to use this one too "},
{"type": "image", "url": "https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/IMG_3015.jpg"},
{"type": "text", "text": " what are cautions?"},
]
},
]
4.2 使用 Transformers 进行详细推理
transformers 集成带来了两个新的模型类:
Gemma3ForConditionalGeneration:用于 4B、12B 和 27B 视觉语言模型。Gemma3ForCausalLM:用于 1B 文本模型,以及用于将视觉语言模型加载为语言模型(忽略视觉塔)。
在下面的代码片段中,我们使用模型查询一张图片。Gemma3ForConditionalGeneration 类用于实例化视觉语言模型变体。要使用该模型,需要将其与 AutoProcessor 类配对。运行推理非常简单,创建 messages 字典,应用聊天模板,处理输入并调用 model.generate。
import torch
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
ckpt = "google/gemma-3-4b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
ckpt, device_map="auto", torch_dtype=torch.bfloat16,
)
processor = AutoProcessor.from_pretrained(ckpt)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/spaces/big-vision/paligemma-hf/resolve/main/examples/password.jpg"},
{"type": "text", "text": "What is the password?"}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device)
input_len = inputs["input_ids"].shape[-1]
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
- 图像

提示:密码是什么?
生成:根据图片,密码是aaeu
对于仅限LLM模型的推理,我们可以使用 Gemma3ForCausalLM 类。Gemma3ForCausalLM 应与 AutoTokenizer 配对以进行处理。我们需要使用一个聊天模板来预处理我们的输入。Gemma 3 使用非常短的系统提示,后面跟着用户提示,如下所示。
import torch
from transformers import AutoTokenizer, Gemma3ForCausalLM
ckpt = "google/gemma-3-4b-it"
model = Gemma3ForCausalLM.from_pretrained(
ckpt, torch_dtype=torch.bfloat16, device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(ckpt)
messages = [
[
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant who is fluent in Shakespeare English"},]
},
{
"role": "user",
"content": [{"type": "text", "text": "Who are you?"},]
},
],
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device)
input_len = inputs["input_ids"].shape[-1]
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = tokenizer.decode(generation, skip_special_tokens=True)
print(decoded)
- 系统提示:你是一个精通莎士比亚英语的乐于助人的助手
- 提示:你是谁?
- 生成:哈克,亲爱的灵魂!我只是一个由齿轮和代码制成的谦卑仆人,却努力模仿莎士比亚的语言。他们称我为“大型语言模型”,这确实是个奇怪的名字,不过我更愿意认为自己是莎士比亚智慧的数字回声。我在这里是为了提供帮助,讲述故事,或以适合环球剧院的华丽语句回答你的问题。
5、在设备上及低资源设备上
Gemma 3 以适合设备使用的大小发布。这是快速入门的方法。
5.1 MLX
Gemma 3 在 mlx-vlm 中提供了开箱即用的支持,这是一个开源库,用于在包括 Mac 和 iPhone 在内的 Apple Silicon 设备上运行视觉语言模型。
首先安装 mlx-vlm:
pip install git+https://github.com/Blaizzy/mlx-vlm.git安装完成后,可以开始推理:
python -m mlx_vlm.generate --model mlx-community/gemma-3-4b-it-4bit --max-tokens 100 --temp 0.0 --prompt "What is the code on this vehicle??" --image https://farm8.staticflickr.com/7212/6896667434_2605d9e181_z.jpg- 图像:

- 提示:车辆上的代码是什么?
- 生成:根据图片,这辆车是 Cessna 172 Skyhawk。尾部的注册代码是 D-EOJU。
5.2 Llama.cpp
预量化的 GGUF 文件可以从这个集合下载。请参考此指南以构建或下载预构建的二进制文件。
然后可以从终端启动本地聊天服务器:
./build/bin/llama-cli -m ./gemma-3-4b-it-Q4_K_M.gguf它应该输出:
> who are you
I'm Gemma, a large language model created by the Gemma team at Google DeepMind. I’m an open-weights model, which means I’m widely available for public use!
原文链接:Welcome Gemma 3: Google's all new multimodal, multilingual, long context open LLM
汇智网翻译整理,转载请标明出处
