Github仓库分析聊天机器人
本文介绍如何使用抓取的数据和LLM构建一个分析GitHub仓库的AI聊天机器人。

我建立了一个AI聊天机器人,它可以回答关于GitHub仓库的问题,并通过提取仓库数据的关键见解来提供答案。我使用了Bright Data的数据AI网络抓取工具来收集结构化的数据,并使用Ollama的Phi3模型训练了一个聊天机器人来分析和与这些数据进行交互。
在这篇文章中,我将带你了解:
- 如何使用Bright Data的数据AI网络抓取工具获取GitHub仓库数据。
- 使用Ollama的Phi3模型训练聊天机器人的步骤。
- 实现基于Streamlit的GitHub见解工具以实现实时交互。
- 使用AI进行仓库分析的经验教训及其影响。
1、使用Bright Data获取GitHub数据集
为了训练聊天机器人,我需要一个包含关键仓库详细信息的高质量数据集。我没有手动从GitHub抓取数据,而是使用了Bright Data的AI抓取器,它提供了结构化且自动化的收集仓库数据的方法。
他们有使用其网络抓取器从任何网站抓取数据的两种方法。这些网络抓取器具有Scraper API和任何人都可以使用的无代码抓取器。
使用Bright Data网络抓取器提取GitHub数据的步骤如下:
a) 在Bright Data上注册并点击左侧栏中的网络抓取器。
如果你是新用户首次登录,你将获得5美元的免费试用服务,有效期为7天。
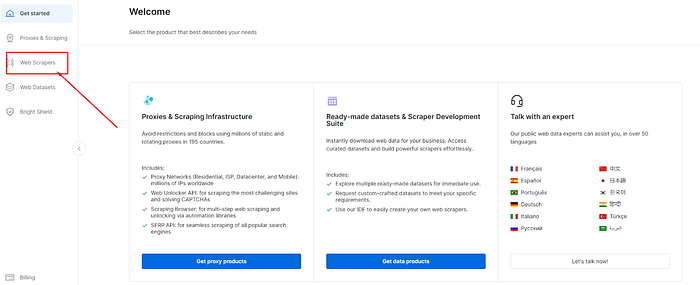
b) 在搜索栏中搜索 “GitHub”并点击第一个结果。

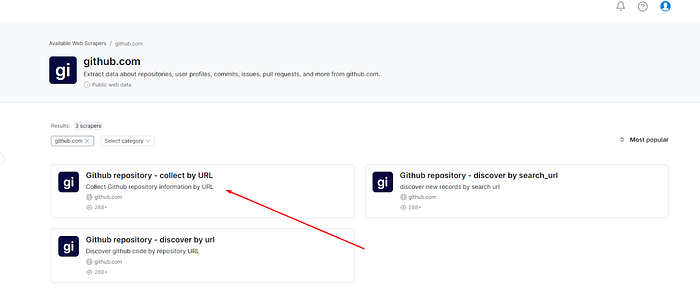
c) 会出现一系列GitHub抓取器。选择 “GitHub Repository — Collect by URL”用于此用途。
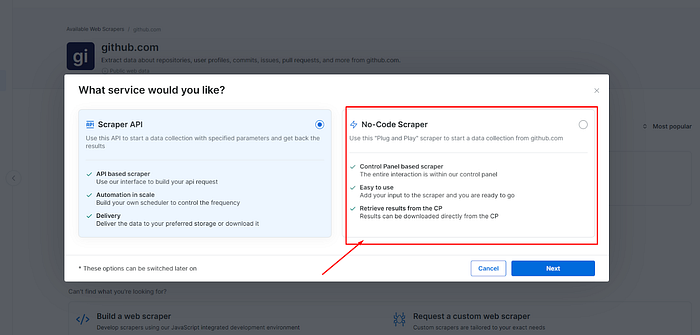
d) 选择无代码抓取器。
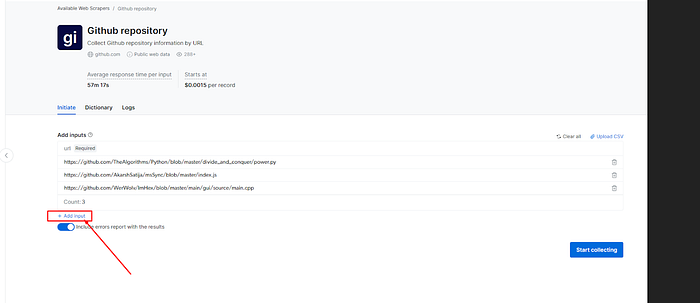
e) 点击 “添加输入”以添加所需的GitHub仓库链接,然后点击“开始收集”。
f) 一旦状态字段显示为”就绪”,点击“下载”并选择CSV格式。
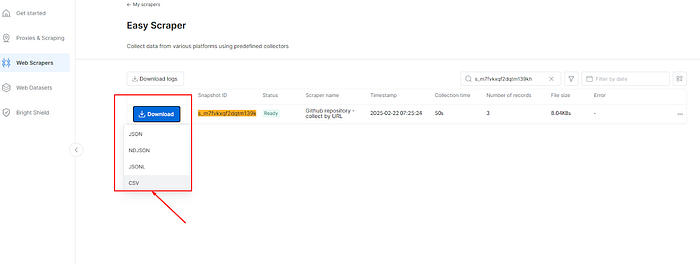
2、构建GitHub见解工具
这个项目使用Python进行数据处理,并使用Streamlit构建简单的UI。
前提条件
- 任意你喜欢的代码编辑器。
- 安装Python(推荐版本3.8及以上)。
2.1 设置项目
创建项目文件夹:
mkdir github-insights-tool
cd github-insights-tool
设置虚拟环境:
python -m venv venv
激活环境:
- Windows:
venv\Scripts\activate
- macOS/Linux:
source venv/bin/activate
安装依赖项:
pip install pandas streamlit langchain_community
Streamlit — 用于构建UI
- Pandas — 用于处理数据集操作
- LangChain (Ollama) — 用于AI驱动的仓库分析
项目结构:
github-insights-tool/
│── github.csv #你的数据集来自Bright Data
│── ai.py
2.2 本地安装和运行聊天机器人(Ollama Phi3模型)
这个AI工具通过分析GitHub仓库的优缺点和可用性生成有关仓库的见解。它还提供了关键的仓库详情,而无需导航到GitHub的多个部分。
为什么选择Ollama?
- 免费且易于设置
- 本地运行,无需互联网依赖
- 提供快速且可定制的响应
安装Ollama
Ollama 提供了一个简单的CLI工具来本地运行大型语言模型(LLMs)。根据你的操作系统安装它:
- Windows(PowerShell):
curl -LO https://ollama.com/download/latest/windows && start ollama.exe
- Linux(Curl):
curl -fsSL https://ollama.ai/install.sh | sh
- macOS(Homebrew):
brew install ollama
下载Phi3模型:
ollama pull phi3
运行Ollama模型:
ollama run phi3
注意: 始终确保Ollama模型正在本地运行后再执行代码。否则,AI模型将无法访问。
2.3 实现GitHub见解工具
该工具包含以下功能:
初始化Ollama
import streamlit as st
import pandas as pd
from langchain_ollama import OllamaLLM
# 使用选定的模型初始化Ollama
llm = OllamaLLM(model="phi3")
加载GitHub数据库
@st.cache_data
def load_github_data():
df = pd.read_csv("githubdata.csv")
df.columns = df.columns.str.strip().str.lower() # 将列名标准化为小写
return df
使用AI分析所需仓库
def analyze_repository(repo_data, llm):
prompt = f"""
分析以下GitHub仓库数据并提供见解:
{repo_data.to_dict()}
关注点:
1. 代码质量和可维护性
2. 流行度和参与度
3. 潜在用途
4. 关键优势和劣势
"""
try:
return llm.invoke(prompt)
except Exception as e:
return f"生成分析时出错:{e}"
此函数基于代码质量、参与度和潜在用途生成见解。
与AI生成的分析进行交互
def interact_with_analysis(analysis, query, llm):
prompt = f"""
根据以下分析:
{analysis}
回答用户的查询:{query}
"""
try:
return llm.invoke(prompt)
except Exception as e:
return f"处理查询时出错:{e}"
这允许用户与AI生成的仓库分析进行交互。
2.4 定义Streamlit应用程序
核心功能
- 允许用户输入GitHub网址(这是CSV文件中的任何一个网址,因此它可以提供针对特定GitHub仓库的答案)。
- 基于分析启动AI聊天机器人交互。
def main():
# 在标题旁边添加GitHub徽标
st.markdown("""<h1 style='display: flex; align-items: center;'>
<img src='https://github.githubassets.com/images/modules/logos_page/GitHub-Mark.png' width='40' style='margin-right:10px;'>
GitHub仓库见解工具
</h1>""", unsafe_allow_html=True)
github_df = load_github_data()
# 用户输入字段,用于输入GitHub仓库网址
repo_url = st.text_input("输入GitHub仓库网址")
analysis_result = ""
if repo_url:
# 根据输入的网址过滤数据集
repo_data = github_df[github_df["url"] == repo_url]
if not repo_data.empty:
repo_data = repo_data.iloc[0]
# 显示仓库详情
st.subheader("仓库详情")
st.write(f"语言:{repo_data['code_language']}")
st.write(f"星数:{repo_data['num_stared']}")
st.write(f"分叉数:{repo_data['num_fork']}")
st.write(f"拉取请求:{repo_data['num_pull_requests']}")
st.write(f"最后功能:{repo_data['last_feature']}")
st.write(f"最新更新:{repo_data['latest_update']}")
# 显示仓库所有者详情
st.subheader("所有者详情")
st.write(f"所有者:{repo_data['user_name']}")
st.write(f"网址:{repo_data['url']}")
# AI驱动的仓库分析
st.subheader("AI分析")
if st.button("生成分析"):
with st.spinner("分析仓库..."):
analysis_result = analyze_repository(repo_data, llm)
st.session_state["analysis"] = analysis_result # 将分析存储在会话状态中
st.write(analysis_result)
else:
st.warning("仓库不在数据集中。请输入有效的网址。")
# 基于生成的分析与AI聊天机器人进行交互
if "analysis" in st.session_state:
st.subheader("与AI关于此仓库的聊天")
user_query = st.text_input("询问关于仓库分析的问题")
if user_query:
with st.spinner("处理查询..."):
response = interact_with_analysis(st.session_state["analysis"], user_query, llm)
st.write(response)
# 运行Streamlit应用程序
if __name__ == "__main__":
main()
运行应用程序:
在终端上,运行以下命令:
streamlit run app.py
2.5 使用GitHub见解工具应用程序
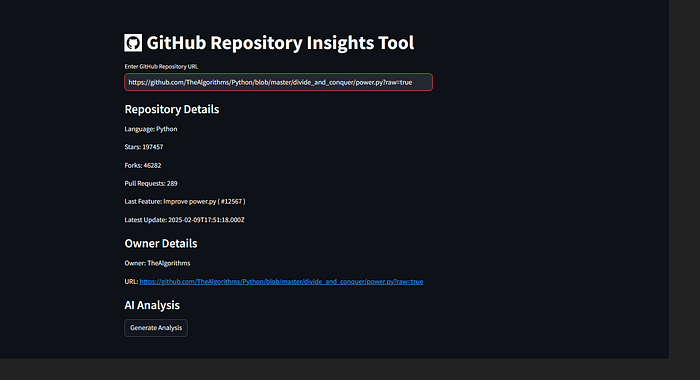
粘贴仓库网址并查看分析。
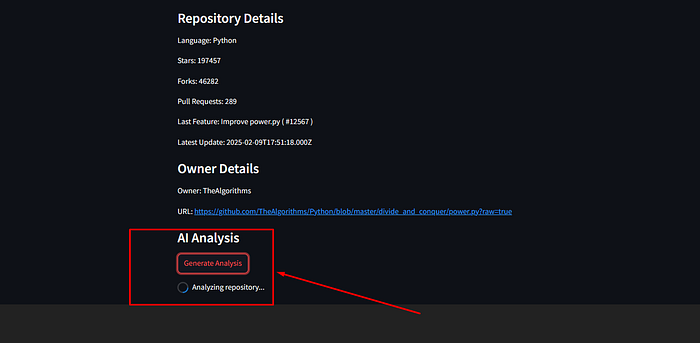
点击 **“生成分析”** 以生成仓库报告。
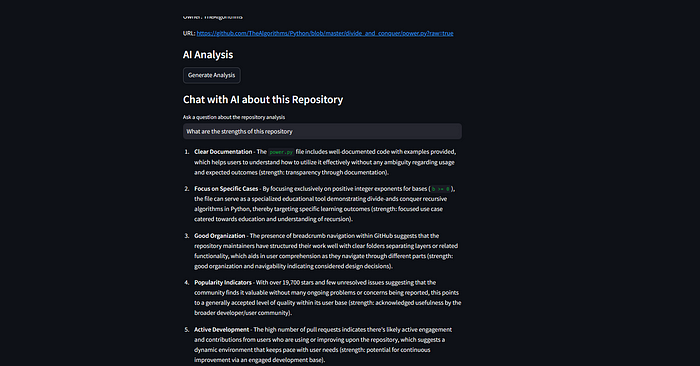
与聊天机器人互动以获得更多见解。
3、结束语
使用Bright Data的数据AI网络抓取工具和Ollama Phi3模型在GitHub仓库上训练聊天机器人非常有效,能够自动化仓库分析。这种方法节省时间,提高准确性,并提供基于真实仓库数据的AI响应。
对于寻找干净、结构化GitHub数据集的开发人员,Bright Data提供了可靠的现成数据集和API集成,以简化数据提取和分析。
原文链接:How I Trained a Chatbot on GitHub Repositories Using an AI Scraper and LLM
汇智网翻译整理,转载请标明出处
