基于GNN的欺诈检测和蛋白质预测
金融交易网络和蛋白质结构有什么共同点?它们在欧几里得 (x, y) 空间中的建模都不太好,需要对复杂、庞大且异构的图进行编码才能真正理解。

金融交易网络和蛋白质结构有什么共同点?它们在欧几里得 (x, y) 空间中的建模都不太好,需要对复杂、庞大且异构的图进行编码才能真正理解。
图(Graph)是金融网络和蛋白质结构中表示关系数据的自然方式。它们捕获实体之间的关系和相互作用,例如金融系统中账户或债券之间的交易以及蛋白质中氨基酸之间的空间接近度。然而,更广为人知的深度学习架构,如 RNN/CNN 和 Transformers,无法有效地对图形进行建模。
你可能会问自己,为什么我们不能将这些图映射到 3D 空间中?如果我们将它们强制放入 3D 网格中:
- 我们会丢失边缘信息,例如分子图中的键类型或交易类型。
- 映射需要填充或调整大小,从而导致扭曲。
- 稀疏的 3D 数据结果会导致许多未使用的网格单元,从而浪费内存和处理能力。
鉴于这些限制,图神经网络 (GNN) 是一种强大的替代方案。在我们关于生物学应用的机器学习系列的续篇中,我们将探讨 GNN 如何应对这些挑战。
与往常一样,我们将从更熟悉的欺诈检测主题开始,然后了解类似概念如何应用于生物学。
1、欺诈检测
为了清楚起见,让我们首先定义什么是图。我们记得在小学时在 x、y 轴上绘制图形,但我们真正做的是绘制一个函数,其中我们绘制了 f(x)=y 的点。当我们在 GNN 的背景下谈论“图”时,我们的意思是对对象之间的成对关系进行建模,其中每个对象都是一个节点,关系是边。
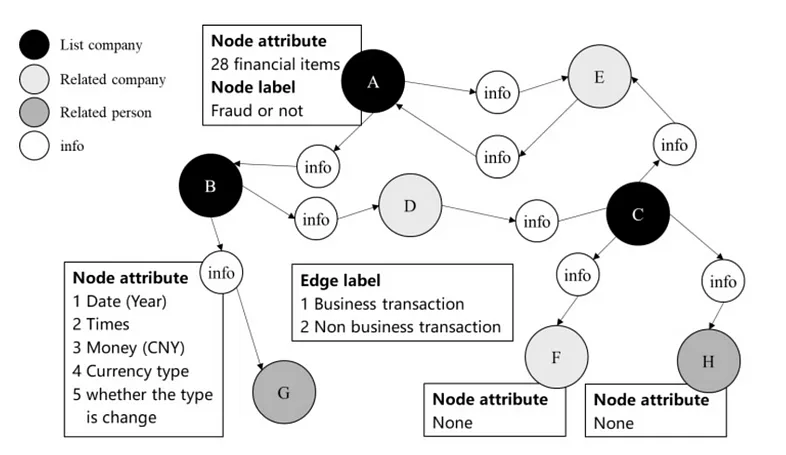
在金融网络中,节点是账户,边是交易。该图将由关联方交易 (RPT) 构建,并可通过属性(例如时间、金额、货币)进行丰富:
传统的基于规则和机器学习的方法通常针对单个交易或实体进行操作。这种限制无法解释交易如何连接到更广泛的网络。由于欺诈者通常跨多个交易或实体进行操作,因此欺诈行为可能无法被发现。
通过分析图表,我们可以捕获直接邻居和更远连接之间的依赖关系和模式。这对于检测洗钱至关重要,因为洗钱是通过多笔交易转移资金以掩盖其来源。 GNN 阐明了洗钱方法创建的密集子图:
2、消息传递框架
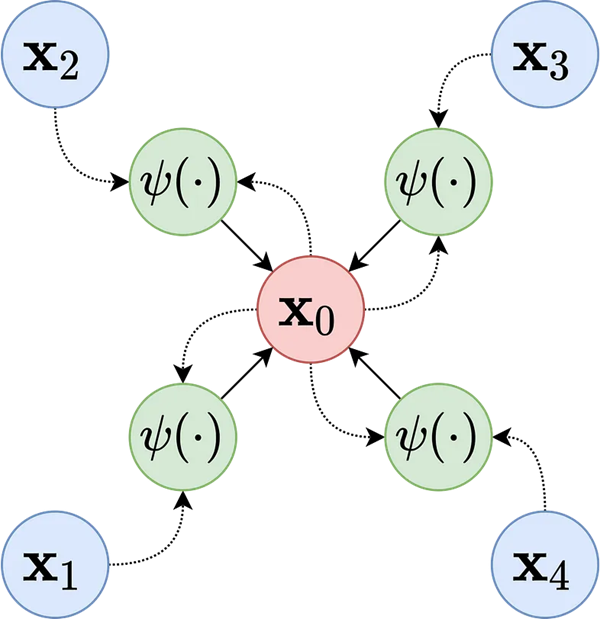
与其他深度学习方法一样,目标是从数据集创建表示或嵌入。 在 GNN 中,这些节点嵌入是使用消息传递框架创建的。 消息在节点之间迭代传递,使模型能够学习图的局部和全局结构。 每个节点嵌入都根据其邻居特征的聚合进行更新。
该框架的一般工作原理如下:
- 初始化:使用基于特征的节点嵌入、随机嵌入或预训练嵌入(例如帐户名称的单词嵌入)初始化嵌入 hv(0)。
- 消息传递:在每一层 t,节点与其邻居交换消息。消息被定义为发送方节点的特征、接收方节点的特征以及连接它们的边的特征,它们被组合在一个函数中。组合函数可以是一个简单的连接,使用固定权重方案(由图卷积网络,GCN 使用)或注意力加权,其中权重是根据发送方和接收方的特征(以及可选的边缘特征)学习的(由图注意力网络,GAT 使用)。
- 聚合:在消息传递步骤之后,每个节点都会聚合收到的消息(简单到平均值、最大值、总和)。
- 更新:然后,聚合的消息通过更新函数(可能是 MLP(多层感知器)如 ReLU、GRU(门控循环单元)或注意力机制)更新节点的嵌入。
- 最终确定:与其他深度学习方法一样,当表示稳定或达到最大迭代次数时,嵌入就会最终确定。
在学习节点嵌入后,可以通过几种不同的方式计算欺诈分数:
- 分类:将最终嵌入传递到多层感知器等分类器中,这需要全面的标记历史训练集。
- 异常检测:根据嵌入与其他嵌入的不同程度,将其归类为异常。基于距离的分数或重构误差可以在此处用于无监督方法。
- 图级评分:将嵌入汇集到子图中,然后输入分类器以检测欺诈团伙。(再次需要标签历史数据集)
- 标签传播:一种半监督方法,其中标签信息基于边缘权重或图连通性传播,对未标记的节点进行预测。
现在,我们对 GNN 解决熟悉问题有了基础了解,我们可以转向 GNN 的另一个应用:预测蛋白质的功能。
3、蛋白质功能预测
我们已经看到通过 AlphaFold 2 和 3 进行蛋白质折叠预测以及通过 RFDiffusion 进行蛋白质设计方面取得了巨大进展。然而,蛋白质功能预测仍然具有挑战性。功能预测出于多种原因而至关重要,但在生物安全中尤其重要,因为它可以在测序前预测 DNA 是否会孤雌生殖。像 BLAST 这样的传统方法依赖于序列相似性搜索,不包含任何结构数据。
如今,GNN 开始在这一领域取得有意义的进展,它利用蛋白质的图形表示来模拟残基及其相互作用之间的关系。它们被认为非常适合蛋白质功能预测,以及识别小分子或其他蛋白质的结合位点并根据活性位点几何形状对酶家族进行分类。
在许多示例中:
- 节点被建模为氨基酸残基
- 边被建模为它们之间的相互作用
这种方法背后的原理是图固有的捕获序列中距离较远但在折叠结构中距离较近的残基之间的长距离相互作用的能力。这类似于为什么 Transformer 架构对 AlphaFold 2 如此有用,它允许对序列中的所有对进行并行计算。
为了使图信息密集,每个节点都可以丰富残基类型、化学性质或进化保守分数等特征。边缘可以选择丰富化学键类型、3D 空间中的接近度以及静电或疏水相互作用等属性。
DeepFRI 是一种从结构预测蛋白质功能的 GNN 方法(特别是图卷积网络 (GCN))。GCN 是一种特定类型的 GNN,它将卷积的概念(用于 CNN)扩展到图形数据。
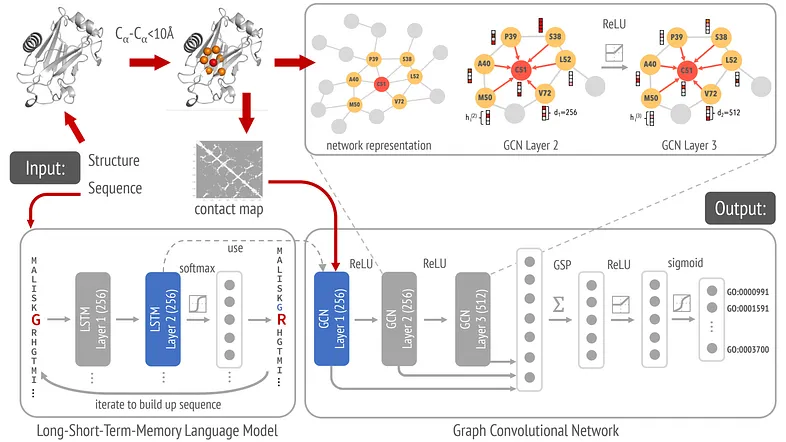
在 DeepFRI 中,每个氨基酸残基都是一个节点,该节点由以下属性丰富:
- 氨基酸类型
- 物理化学性质
- 来自 MSA 的进化信息
- 来自预训练 LSTM 的序列嵌入
- 结构背景,例如溶剂可及性。
每个边被定义为捕获蛋白质结构中氨基酸残基之间的空间关系。如果两个节点(残基)之间的距离低于某个阈值(通常为 10 Å),则存在边。在此应用中,边没有属性,用作无加权连接。
该图使用节点特征 LSTM 生成的序列嵌入以及从残基接触图创建的残基特定特征和边缘信息进行初始化。
一旦定义了图,消息传递就会通过三层中的每一层的基于邻接的卷积进行。使用图的邻接矩阵从邻居聚合节点特征。堆叠多个 GCN 层允许嵌入从越来越大的邻域中捕获信息,从直接邻居开始,扩展到邻居的邻居等。
最终的节点嵌入被全局池化以创建蛋白质级嵌入,然后用于将蛋白质分类为层次相关的功能类别(GO 术语)。分类是通过将蛋白质级嵌入通过具有 S 形激活函数的全连接层(密集层)来执行的,使用二元交叉熵损失函数进行优化。分类模型基于来自蛋白质结构(例如来自蛋白质数据库)的数据和来自 UniProt 或基因本体等数据库的功能注释进行训练。
4、结束语
本文最后的想法:
- 图对于很多非线性系统的建模非常有用
- GNN 通过结合局部和全局信息来捕捉传统方法难以建模的关系和模式。
- GNN 有很多变体,但目前最重要的是图卷积网络和图注意网络。
- GNN 可以使用监督和无监督方法高效地识别洗钱计划中存在的多跳关系。
- GNN 可以通过结合结构数据来改进仅基于序列的蛋白质功能预测工具,如 BLAST。这使研究人员能够预测与已知蛋白质序列相似性最小的新蛋白质的功能,这是了解生物安全威胁和实现药物发现的关键步骤。
原文链接:Graph Neural Networks: Fraud Detection and Protein Function Prediction
汇智网翻译整理,转载请标明出处
