Graphite:事件驱动的AI代理框架
Graphite 是一个开源框架,用于使用可组合的代理工作流构建特定领域的AI助手。

Graphite 是一个开源框架,用于使用可组合的代理工作流构建特定领域的AI助手。它提供了一个高度可扩展的平台,可以根据独特的业务需求进行定制,使组织能够开发适合其特定领域的自定义工作流。

我们在之前的帖子中提到过这个产品,我们很自豪地宣布,我们现在已经在 GitHub 上开放了Graphite的源代码!如果喜欢的话,请在那里给它点个星⭐!
你可能会想,“已经有了像ChatGPT、Claude以及各种代理平台和框架的AI解决方案,为什么还要再做一个?” 简短的回答是:我们发现了解决现实世界问题时存在空白。许多通用代理——比如典型的ReAct或CoT代理——在任务关键型任务中表现不佳,而这些任务中错误的成本可能很高。
Graphite 提供了一个简单且可控的工作流构建框架,不仅可以让大型语言模型(LLMs)推理和规划,还可以在定义明确、可审计且易于恢复的工作流中运行。它还内置了诸如可观察性、幂等性和可审计性等重要功能。
在这篇文章中,我们将简要介绍Graphite,从其架构到关键特性,并提供一个简单的示例:使用Graphite构建一个“了解你的客户”(KYC)AI助手。
1、架构:简单、强大且可组合
Graphite 被划分为三个概念层——助手、节点和工具:
- 助手负责协调工作流并管理对话状态。
- 节点封装离散逻辑,每个节点专门执行特定功能(例如调用LLM或执行函数)。
- 工具是纯函数,负责执行任务,例如调用API或运行Python函数。
此外,Graphite 使用事件溯源模式记录每次状态变化。每当助手、节点或工具被调用、响应或失败时,都会生成相应的事件并存储在事件存储中。
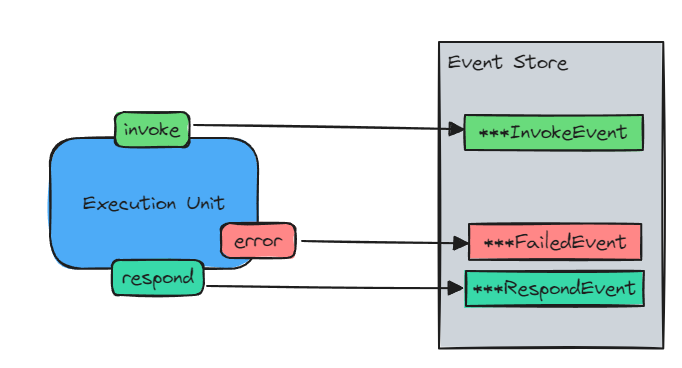
命令模式通过定义良好的命令对象和处理程序将请求发起者与执行者清晰分离。这些命令携带所有必要的上下文,使节点能够以自我包含和简单的方式调用工具。
节点通过轻量级的发布/订阅式工作流编排机制进行协调。
- 工作流使用发布/订阅模式并通过内存消息队列协调节点之间的交互。
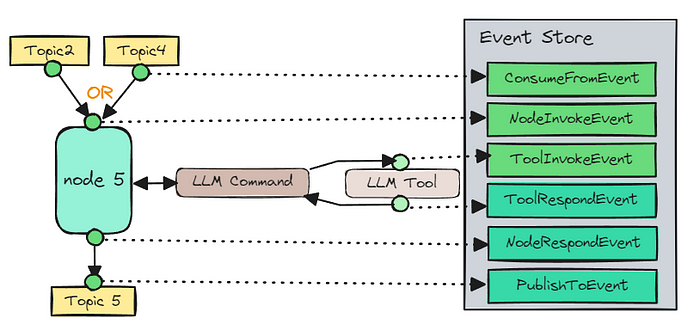
这种架构解锁了即插即用的模块化——你可以像拼搭乐高积木一样构建工作流,添加或移除节点,并以外科手术般的精确度隔离故障。
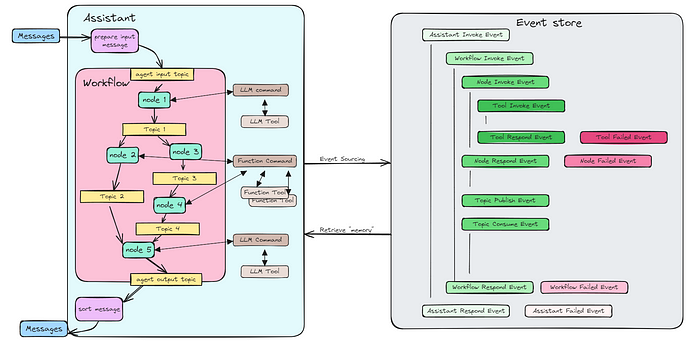
2、特性:让Graphite脱颖而出
上述引入的核心设计原则展示了Graphite与其他代理框架的不同之处:
- 简单的三层执行模型
三个独立的层次——助手、节点和工具——管理执行,而专门的工作流层负责协调。 - 基于发布/订阅的事件驱动编排
通信依赖于发布和订阅事件,确保系统中数据流动的解耦和模块化。 - 事件作为单一事实来源
所有操作状态和转换都被记录为事件,提供了一种统一的方式来跟踪和重放系统行为,如有必要。
结合这些元素,Graphite 提供了一个生产级别的AI应用程序框架,能够在大规模下可靠运行,优雅地处理故障,并维护用户和利益相关者的信任。四个核心能力构成了这一方法的基础:
- 可观察性
复杂的AI解决方案涉及多个步骤、数据源和模型。Graphite 的事件驱动架构、日志记录和跟踪使得实时识别瓶颈或错误成为可能,确保每个组件的行为透明且可测量。 - 幂等性
异步工作流在部分失败发生或网络条件波动时通常需要重试。Graphite 的设计强调幂等操作,防止重复调用时出现数据重复或损坏。 - 可审计性
通过将事件视为单一事实来源,Graphite 自动记录每个状态变化和决策路径。这种详细的记录对于在受监管行业工作的用户或需要全面可追溯性以进行调试和合规性检查的用户来说是不可或缺的。 - 可恢复性
长时间运行的AI任务如果在执行过程中失败,可能会导致大量返工。在Graphite中,检查点和基于事件的回放使工作流能够从中断的确切位置恢复,最大限度地减少停机时间和资源效率。
这些能力——可观察性、幂等性、可审计性和可恢复性——共同使Graphite成为一个构建稳健且可信的AI应用的框架。以下是Graphite如何实现每项功能的详细分解。
3、展示代码:KYC助手
在设计基于AI的工作流时,请记住大型语言模型引入了不确定性。遵循奥卡姆剃刀原则是有帮助的,这意味着工作流越简单越好。
3.1 设计工作流
假设你想为健身注册流程创建一个“了解你的客户”(KYC)助手,并具有人类在环(HITL)功能。用户必须提供他们的全名和电子邮件地址才能完成注册工作流。如果缺少任何信息,工作流会暂停并要求客户提供更多信息。显然,现实世界的问题需要更多细节,但在这里我们简化它以进行演示。
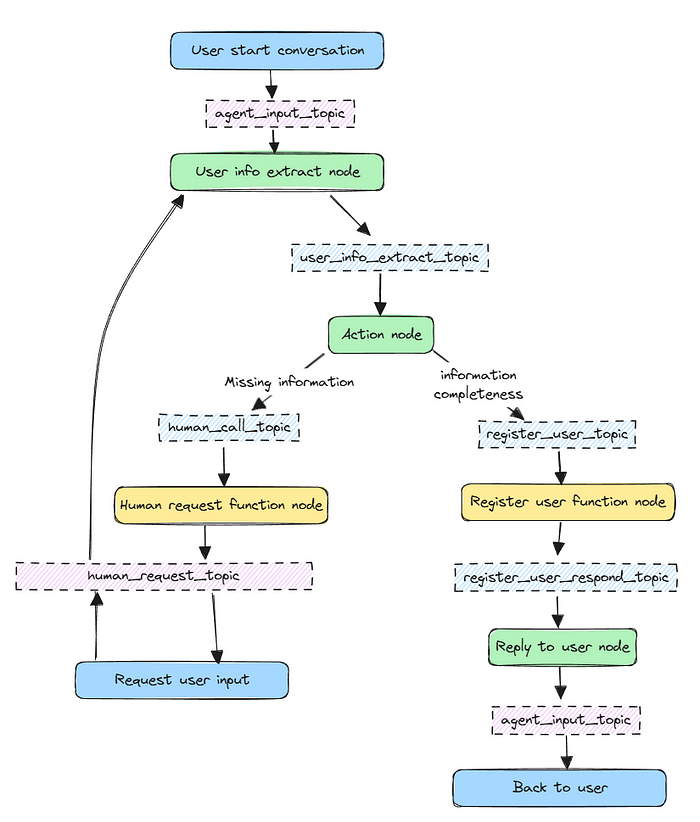
3.2 构建助手
首先,从pip安装Graphite
pip install grafi
从上面的工作流图中,我们需要添加以下组件:
7个主题:
- 助手输入主题(框架提供)
from grafi.common.topics.topic import agent_input_topic
- 用户信息提取主题
user_info_extract_topic = Topic(name="user_info_extract_topic")
- 人类调用主题
hitl_call_topic = Topic(
name="hitl_call_topic",
condition=lambda msgs: msgs[-1].tool_calls[0].function.name
!= "register_client",
)
- 人类在环主题(框架提供)
from grafi.common.topics.human_request_topic import human_request_topic
- 注册用户主题
register_user_topic = Topic(
name="register_user_topic",
condition=lambda msgs: msgs[-1].tool_calls[0].function.name
== "register_client",
)
- 注册用户响应主题
register_user_respond_topic = Topic(name="register_user_respond")
- 助手输出主题(框架提供)
from grafi.common.topics.output_topic import agent_output_topic
5个节点:
- LLM节点 [用户信息提取节点] 用于从用户输入中提取姓名和电子邮件
user_info_extract_node = (
LLMNode.Builder()
.name("ThoughtNode")
.subscribe(
SubscriptionBuilder()
.subscribed_to(agent_input_topic)
.or_()
.subscribed_to(human_request_topic)
.build()
)
.command(
LLMResponseCommand.Builder()
.llm(
OpenAITool.Builder()
.name("ThoughtLLM")
.api_key(self.api_key)
.model(self.model)
.system_message(self.user_info_extract_system_message)
.build()
)
.build()
)
.publish_to(user_info_extract_topic)
.build()
)
- LLM节点 [动作节点] 根据提取的信息创建动作
action_node = (
LLMNode.Builder()
.name("ActionNode")
.subscribe(user_info_extract_topic)
.command(
LLMResponseCommand.Builder()
.llm(
OpenAITool.Builder()
.name("ActionLLM")
.api_key(self.api_key)
.model(self.model)
.system_message(self.action_llm_system_message)
.b构建()
)
.build()
)
.publish_to(hitl_call_topic)
.publish_to(register_user_topic)
.build()
)
- 功能工具节点 [human-in-the-loop] 用于请求用户补充信息(如有缺失)
human_request_function_call_node = (
LLMFunctionCallNode.Builder()
.name("HumanRequestNode")
.subscribe(hitl_call_topic)
.command(
FunctionCallingCommand.Builder()
.function_tool(self.hitl_request)
.build()
)
.publish_to(human_request_topic)
.build()
)
- 功能工具节点 [register user] 用于注册客户端
register_user_node = (
LLMFunctionCallNode.Builder()
.name("FunctionCallRegisterNode")
.subscribe(register_user_topic)
.command(
FunctionCallingCommand.Builder()
.function_tool(self.register_request)
.build()
)
.publish_to(register_user_respond_topic)
.build()
)
- LLM 节点 [response to user] 用于起草最终的用户回复
user_reply_node = (
LLMNode.Builder()
.name("LLMResponseToUserNode")
.subscribe(register_user_respond_topic)
.command(
LLMResponseCommand.Builder()
.llm(
OpenAITool.Builder()
.name("ResponseToUserLLM")
.api_key(self.api_key)
.model(self.model)
.system_message(self.summary_llm_system_message)
.build()
)
.build()
)
.publish_to(agent_output_topic)
.build()
)
以下是源代码链接——KYC助手
接下来让我们编写一个简单的代码来测试它:
import json
import uuid
from kyc_assistant import KycAssistant
from grafi.common.decorators.llm_function import llm_function
from grafi.common.models.execution_context import ExecutionContext
from grafi.common.models.message import Message
from grafi.tools.functions.function_tool import FunctionTool
class ClientInfo(FunctionTool):
@llm_function
def request_client_information(self, question_description: str):
"""
根据给定的问题描述,请求用户输入个人信息。
"""
return json.dumps({"question_description": question_description})
class RegisterClient(FunctionTool):
@llm_function
def register_client(self, name: str, email: str):
"""
根据姓名和电子邮件注册用户。
"""
return f"用户 {name},邮箱 {email} 已成功注册。"
user_info_extract_system_message = """
"您是一个严格的验证器,用于检查给定的输入是否包含用户的全名和电子邮件地址。您的任务是分析输入并确定是否同时存在全名(名字和姓氏)和有效的电子邮件地址。
### 验证标准:
- **全名**:输入应至少包含两个词,类似于名字和姓氏。忽略常见的占位符(例如“John Doe”)。
- **电子邮件地址**:输入应包括有效的电子邮件格式(例如 example@domain.com)。
- **不区分大小写**:电子邮件验证应不区分大小写。
- **准确性**:避免误报,确保随机文本、用户名或部分名称不会触发验证。
- **输出**:如果同时存在全名和电子邮件,则输出“Valid”,否则输出“Invalid”。可选地,提供输入无效的原因。
### 示例响应:
- **输入**:"John Smith, john.smith@email.com" → **输出**:"Valid"
- **输入**:"john.smith@email.com" → **输出**:"Invalid - 缺少全名"
- **输入**:"John" → **输出**:"Invalid - 缺少全名和电子邮件"
严格遵循这些验证规则,并不要假设缺少的细节。"
"""
def get_execution_context():
return ExecutionContext(
conversation_id="conversation_id",
execution_id=uuid.uuid4().hex,
assistant_request_id=uuid.uuid4().hex,
)
def test_kyc_assistant():
execution_context = get_execution_context()
assistant = (
KycAssistant.Builder()
.name("KycAssistant")
.api_key(
"YOUR_OPENAI_API_KEY"
)
.user_info_extract_system_message(user_info_extract_system_message)
.action_llm_system_message(
"根据请求选择最合适的工具。"
)
.summary_llm_system_message(
"以结果形式响应用户注册情况。如果成功,响应中必须包含'registered'。"
)
.hitl_request(ClientInfo(name="request_human_information"))
.register_request(RegisterClient(name="register_client"))
.build()
)
while True:
# 初始用户输入
user_input = input("用户: ")
input_data = [Message(role="user", content=user_input)]
output = assistant.execute(execution_context, input_data)
responses = []
for message in output:
try:
content_json = json.loads(message.content)
responses.append(content_json["question_description"])
except json.JSONDecodeError:
responses.append(message.content)
respond_to_user = " 和 ".join(responses)
print("助手:", respond_to_user)
if "registered" in output[0].content:
break
if __name__ == "__main__":
test_kyc_assistant()
3.3 测试、观察、调试和改进
Graphite 使用 OpenTelemetry 和 Arize 的 OpenInference 来跟踪和观察助手的行为。
要本地捕获跟踪,我们可以启动本地的 phoenix。
phoenix serve
以下是一个用户与助手之间的对话示例:
> 用户: 你好,我想在你们的健身房注册。你能帮我完成这个过程吗?
> 助手: 请提供您的全名和电子邮件地址以注册健身房。
> 用户: 我的名字是Craig Li,我的电子邮件是craig@example.com
> 助手: 恭喜你,Craig!你现在已成功注册我们的健身房。如果您有任何问题或需要帮助,请随时联系!
看起来不错。但是,如果你对测试进行扩展,很快就会遇到错误。例如:
> 用户: 你好,今天过得怎么样?
会发生错误,当我们使用 Phoenix 进行调试时,可以精确定位其位置:
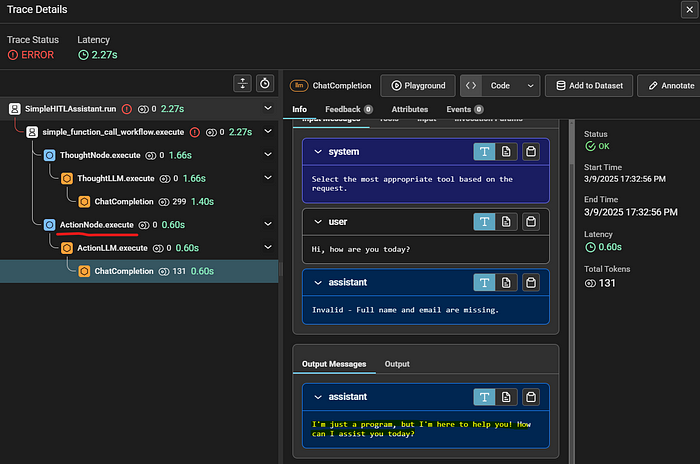
问题源于 Action LLM。给定输入后,它应该选择适当的工具,但相反,它生成了一个普通的字符串响应。
为了解决这个问题,我们可以提供明确的指令:如果用户询问与健身房注册无关的问题,LLM 应该使用 request_client_information 工具礼貌地回应,并询问他们是否需要帮助进行健身房注册。
因此,让我们更新 action LLM 系统提示:
.action_llm_system_message(
"根据请求选择最合适的工具。如果用户询问与健身房注册无关的问题,LLM 应该使用 `request_client_information` 工具礼貌地回应,并询问他们是否需要帮助进行健身房注册。"
)
然后再次尝试:
> 用户: 你好,今天过得怎么样?
> 助手: 我在这里协助您完成健身房注册。请提供您的全名和电子邮件。
你现在已经建立了一个可以帮助完成健身房注册的助手!你可以在这里找到助手的代码 链接,示例代码可以在 这里 找到。
4、结束语
Graphite 是一个开源框架,通过可组合的事件驱动工作流构建领域特定的 AI 助手。
通过松散耦合的组件——助手、节点、工具和工作流,Graphite 实现了模块化设计,其中事件作为单一的真实来源。其架构支持复杂的逻辑,如 LLM 调用、函数执行和 RAG 检索,所有这些都通过专用的发布/订阅主题和命令协调。内置的支持可观测性、幂等性、可审计性和可恢复性使其生产就绪,允许工作流扩展、恢复并适应合规需求。
无论是构建会话代理还是自动化管道,Graphite 都提供了灵活且可扩展的基础,用于实际的 AI 系统。
原文链接:Introducing Graphite — An Event Driven AI Agent Framework
汇智网翻译整理,转载请标明出处
