Hello, ComfyUI
在本文结束时,你将拥有一个完全从头开始构建的 ComfyUI 中功能齐全的文本到图像工作流。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
ComfyUI 曾因其令人生畏的复杂性而处于劣势,但在 Stable Diffusion XL (SDXL) 公开发布后,其使用量激增。其原生模块化使其能够迅速支持 Stability 在 SDXL 的双模型生成中引入的根本性架构变化。虽然大多数其他界面的贡献者面临着重组整个平台以适应这一变化的挑战,但 ComfyUI 所需的修改要少得多,只需要在其样板事件链中增加几个新节点。Comfy 对 SDXL 模型的早期支持迫使最热切的 AI 图像创建者(包括我自己)进行转换。
即使是现在,一个庞大的社区仍然更喜欢 Stable Diffusion 的 1.5 版模型而不是 SDXL。对 SDXL 的批评包括更高的硬件要求和使用更严格的训练数据集。我怀疑,对于许多人来说,这些原则性立场掩盖了他们的主要不满:过渡到 ComfyUI 的时间和精力成本。 Stable Diffusion 的早期采用者从一开始就一直在跟踪兼容界面的开发,在开发过程中同步学习小而易消化的复杂内容。现在突然有压力要一头扎进 ComfyUI 完全成熟但完全陌生的生态系统。这真的很令人生畏。难怪这么多人坚持他们所知道的东西!即使在其他界面赶上来支持 SDXL 之后,与 ComfyUI 相比,它们更加臃肿、脆弱、拼凑和缓慢。
那么,如果我们再次从头开始学习,但为 ComfyUI 重新设计这种体验会怎样?如果我们从最简单的实现开始,并且只在明确看到需要时才添加复杂性,会怎样?没有庞大的工作流程,没有无限的参数架,没有自定义节点,没有节点意大利面条(希望如此)。让我们将工作流程定制视为一系列小而易处理的问题,每个问题都有一个小而易处理的解决方案。在这个工作流构建系列中,我们将学习以易于理解的方式添加自定义项,与工作流的开发同步,并一次更新。
文本到图像:构建你的第一个工作流
在本文结束时,你将拥有一个完全从头开始构建的 ComfyUI 中功能齐全的文本到图像工作流。在开始之前,我只会做以下假设:
- 你已安装 ComfyUI。这方面有丰富的指南和资源,所以我不会重新发明死马。官方文档很棒。
- 你已下载基本 SDXL 1.0 模型并将其放在 ComfyUI 的模型文件夹中。精炼器模型可获得加分,但我们还没有到那一步。假装它不存在。
1、ComfyUI
首先,启动并运行 ComfyUI。欣赏那个空的工作区。

这是“节点”的画布,它们是执行一项非常具体任务的小构建块。每个节点都可以链接到其他节点以创建更复杂的作业。
如果已加载非空的默认工作区,请单击右侧的清除按钮将其清空。我们从零开始构建英雄。
单击底部的文本并选择你下载的 SDXL 1.0 模型文件。如果没有看到它,请确保模型文件( .safetensors或 .ckpt)位于 ComfyUI 的模型文件夹中。
2、KSampler
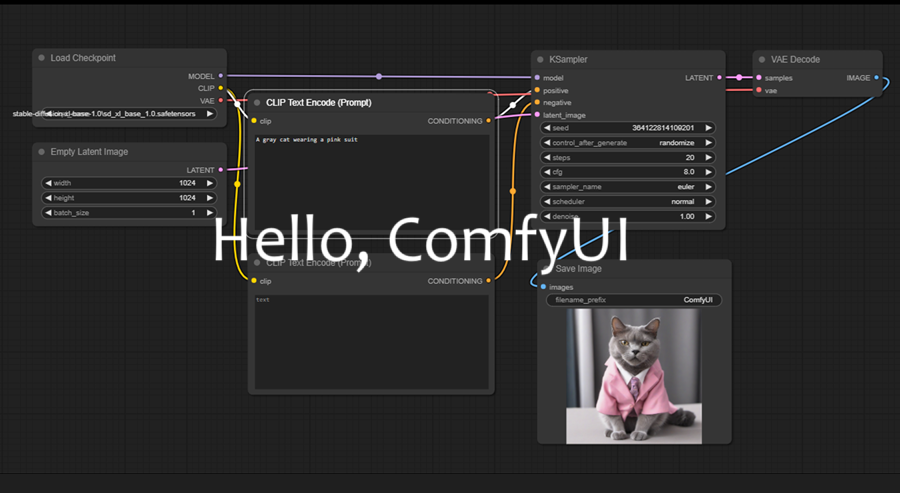
你需要的第一个节点是 KSampler。右键单击并导航到: Add Node > sampling > KSampler:

KSampler 是生成过程的主力。

它获取随机图像噪声,然后尝试在噪声中找到连贯的图像。这称为“采样”。它根据它认为看到的内容使该图像稍微不那么嘈杂,然后再次查看它。冲洗并重复您告诉它的次数。
这就像你试图想象一块随机切割的粘土的形状。然后,你对粘土的形状进行一点点雕刻,让它看起来更像你在粘土中看到的东西。你继续一点一点地雕刻,直到你能说服你的朋友看到与你相同的东西。
3、加载检查点
你无法想象一个你从未听说过的形状!KSampler 也一样。这就是模型文件的用途。把它想象成一本大字典。对于你当地的韦氏词典来说,在字典中的每个单词旁边放一张图片是一项不可能完成的任务(而且浪费了大量空间)。但是,比如说,“猫”的条目将包含大量关于什么使某物成为猫的其他信息。这些信息可能足以让你想象一只猫。
虽然模型不包含任何图像数据,但它包含大量关于可以用图像数据表示的事物类型的其他信息——足以让 KSampler 想象这些事物。
让我们将模型文件放入工作区。右键单击工作区并导航子菜单至:Add Node > loaders > Load Checkpoint :

你将在画布上看到此节点,其底部的文本略有不同:

4、节点连接
每个节点的右侧是该节点的输出。每个节点的左侧是输入。让我们通过简单的鼠标拖动动作,将 Load Checkpoint 节点右侧的MODEL 输出点连接到 KSampler 节点上的模型输入点。

当节点完成其设计的工作时,它会将其结果发送到其输出连接到的所有后续节点。在这里,你只是告诉 Load Checkpoint 节点将其加载的模型文件发送到 KSampler。KSampler 现在可以访问模型的整个概念词典。
5、CLIP 文本编码(正提示)
在 KSampler 现在知道如何想象的所有事物中,你如何告诉它你希望它想象什么?这是文本提示的工作。
右键单击任何空白处并导航到:Add Node > Conditioning > CLIP Text Encode(Prompt)

CLIP 是另一种词典,它嵌入到我们的 SDXL 文件中,就像英语和 AI 理解的语言之间的翻译词典一样工作。 AI 不会用语言说话,而是用“token”或有意义的单词和数字包来说话,这些单词和数字包映射到模型文件的巨大词典中的概念。
从 Load Checkpoint 节点获取 CLIP 输出点并将其连接到clip输入点。然后将 CLIP 文本编码(提示)节点输出的条件点连接到 KSampler 节点的positive输入点

这会将 CLIP 发送到你的提示框中以消化单词,将它们转换为 token,然后为 KSampler 吐出“条件”。条件是当你哄骗 KSampler 在它开始的随机噪声中寻找特定事物时使用的术语。它使用你的英语到 token 翻译提示来引导它的想象力。
6、CLIP 文本编码(负提示)
条件是双向的。你可以告诉 KSampler 寻找特定的东西,同时告诉它避免某些特定的东西。这就是正提示和负提示之间的区别。
你需要第二个 CLIP 文本编码(提示)节点来处理负提示,因此右键单击空白处并再次导航到: Add Node > Conditioning > CLIP Text Encode(Prompt) :

再次连接来自加载检查点的 CLIP 输出点。将 CONDITIONING 输出点链接到 KSampler 上的negative输入点。
7、空白的隐图像
现在我们必须通过给 KSampler 一个“空白的隐图像”来明确地给它一个开始的地方。空潜像就像一张空白的绘图纸。我们给 KSampler 一张白纸,这样它就有地方画我们告诉它画的东西。
右键单击任何空白处并选择: Add Node > latent > Empty Latent Image :

将 LATENT 点连接到 KSampler 上的 latent_image 输入:

由于 SDXL 模型是在数据集上训练的,因此 KSampler 需要一张大纸。它可以绘制任意大小的图像,但最好在与用于构建模型概念词典的图像大小相同的纸张上绘制。
单击“Empty Latent Image”节点中的宽度和高度框,并将两个值都更改为 1024 像素。
8、VAE 解码
空白的隐图像包含如此多的数学层和维度,以至于我们人类无法像查看普通纸张或数字图像那样查看它。多面隐图像必须折叠成更简单的东西。我们必须将其“解码”为一个方形像素网格,以便在我们适中的二维屏幕上显示。这是由“VAE”(变分自动编码器)完成的,它也方便地嵌入到 SDXL 模型中。
通过右键单击并导航到以下位置添加 VAE 解码节点: Add Node > latent > VAE Decode :


为了让 VAE 解码节点完成将 KSampler 的图像折叠成人类可见的 PNG 的工作,它需要两样东西:KSampler 在空白隐图像上绘制的图形和 VAE 确切知道如何将该图形转换回像素。
将 KSampler 的 LATENT 输出连接到 VAE 解码节点上的样本输入。然后一路回头看加载检查点节点并将 VAE 输出连接到 vae 输入。

9、保存图像
我们只需要一个非常简单的节点就可以了。我们需要一个节点将图像保存到计算机!右键单击空白处并选择: Add Node > image > Save Image :

然后将 VAE 解码节点的输出连接到保存图像节点的输入:

10、工作流程
工作区中的每个节点都已连接其输入和输出。我们的工作流程已完成!除了尝试之外,没有什么可做的了。在 KSampler 上的“positive”输入所附加的 CLIP Text Encode 文本框中输入一些内容。

现在单击右侧的 Queue Prompt。
就是这样...这就是全部!每个文本到图像的工作流程都只是这七个节点的扩展或变体!

原文链接:Building a Workflow from Scratch: A ComfyUI Walkthrough for Beginners
汇智网翻译整理,转载请标明出处
