我如何利用LLM辅助编写代码
如果有人告诉你用LLMs写代码很容易,那他们可能无意中误导了你。他们可能已经偶然找到了一些有效的模式,但这些模式并不自然适用于所有人。

在线讨论关于使用大型语言模型(LLMs)来帮助编写代码的文章不可避免地会引发开发者的评论,他们的经验往往令人失望。他们常常会问自己哪里做错了——为什么有些人报告了如此好的结果,而自己的实验却表现不佳?
使用LLMs来编写代码是困难的且不直观的。要弄清楚如何在这种情况下有效使用它们需要付出显著的努力,并且几乎没有指导可以帮助人们最好地应用它们。
如果有人告诉你用LLMs写代码很容易,那他们可能无意中误导了你。他们可能已经偶然找到了一些有效的模式,但这些模式并不自然适用于所有人。
我已经使用LLMs编写代码超过两年,并取得了很好的成果。以下是我尝试将部分经验和直觉传递给你们的方式。
1、设定合理的期望
忽略“通用人工智能”炒作——LLMs仍然是高级自动补全。它们所做的只是预测一系列标记,但事实证明编写代码主要是关于以正确的顺序排列这些标记,因此只要正确引导它们,它们可以对这一点非常有用。
如果你认为这项技术会完美实现你的项目而不需你动用自己的技能,你会很快感到失望。
相反,使用它们来增强你的能力。我目前最喜欢的思维模式是把它们当作一个过度自信的结对编程助手,速度快得可以随时查找信息,能瞬间生成相关示例,并且在执行枯燥任务时毫无怨言。
过度自信很重要。它们肯定会犯错误——有时微妙,有时巨大。这些错误可能是深深违背人性的——如果一个人类合作者虚构了一个不存在的库或方法,你会立刻失去对他/她的信任。不要陷入拟人化LLMs的陷阱,假设失败会让机器像人类一样受到同样的质疑。
当你与LLMs合作时,你会发现它们无法完成的事情。记下这些事情——它们是非常有用的教训!这也是未来强大新模型的一个有价值的例子——当旧模型无法处理的任务现在能够产生可用的结果时,这就是一个标志。
2、考虑训练截止日期
任何模型的一个重要特征是它的训练截止日期。这是模型停止收集其训练数据的日期。对于OpenAI的模型来说,通常是2023年10月。Anthropic、Gemini和其他提供商可能会有更晚的日期。
这对代码尤其重要,因为它影响到它们熟悉哪些库。如果自2023年10月以来某个库发生了重大变化,OpenAI模型将不知道这些变化!
我从LLMs中获得足够的价值,因此我现在会刻意考虑这一点,当我选择库时——我会尽量坚持使用那些稳定且足够流行的库,这样许多关于它们的例子才能进入训练数据。我喜欢应用无聊技术的原则——在项目的独特卖点上创新,在其他方面坚持经过验证的解决方案。
LLMs仍然可以帮助你处理超出其训练数据范围的库,但你需要投入更多工作——你需要在提示中提供最近的例子来展示这些库应该如何使用。
这就带来了我们在使用LLMs时最重要的理解:
3、上下文是关键
大多数从LLMs获得良好结果的技巧都归结于管理其上下文——即当前对话中的文本。
这个上下文不仅仅是你输入的提示:成功的LLM交互通常采取对话的形式,上下文包括你发送的所有消息以及LLM的每一次回复。
当你开始一个新的对话时,你会将上下文重置为零。这是重要的要知道,因为当对话不再有用时,修复的方法通常是擦除所有内容并重新开始。
一些LLM编码工具超越了仅仅的对话。例如,Claude Projects允许你预先填充大量的文本上下文——包括最近的能力直接从GitHub仓库导入代码,我正在大量使用这一功能。
像Cursor和VS Code Copilot这样的工具会自动将当前编辑器会话和文件布局的上下文包含进来,有时你可以使用类似Cursor的@命令来拉入额外的文件或文档。
我之所以主要通过ChatGPT和Claude的网页或应用程序界面工作的原因之一就是它让我更容易理解到底什么进入了上下文。那些隐藏上下文的LLM工具效果较差。
你可以利用之前的回复也是上下文的一部分的优势。对于复杂的编码任务,试着让LLM先写一个简单的版本,检查它是否工作,然后迭代构建更复杂的实现。
我经常在开始新的聊天时将现有的代码倒入上下文中,然后与LLM一起修改它。
我最喜欢的一种代码提示技术是放入几个与我想构建的内容相关的完整示例,然后提示LLM将其作为新项目的灵感。我在描述我的JavaScript OCR应用程序时详细介绍了这一点,该应用程序结合了Tesseract.js和PDF.js——两个我过去使用过的库,我可以在我提供的提示中提供它们的工作示例。
4、让他们提供选项
我的大多数项目都是从一些开放性问题开始的:我想做的事情是否可行?有哪些潜在的实现方式?其中哪些是最优的选择?
我在初始研究阶段使用LLMs。
我会使用诸如“Rust中HTTP库的选择是什么?包括使用示例”之类的提示——或者“JavaScript中一些有用的拖放库是什么?为每个库构建一个演示工件”(给Claude)。
训练截止日期在这里很重要,因为它意味着不会建议更新的库。通常这没问题——我不想要最新的,我想要最稳定且存在时间足够长的库,以便排除大部分的bug。
如果我要使用更新的库,我会自己进行这项研究,而不是在LLM世界中进行。
任何项目的最佳起点是一个原型,它可以证明该项目的关键需求可以得到满足。我经常发现LLM可以在我坐下笔记本电脑几分钟内(有时甚至是在手机上工作时)让我达到这个工作原型。
5、明确告诉他们该做什么
一旦完成了初步研究,我就完全改变了模式。对于生产代码,我的LLM使用更加专制:我把它当作一个数字实习生,根据我的详细指示打字编写代码。
这里有一个最近的例子:
编写一个Python函数,使用asyncio httpx,具有以下签名:
async def download_db(url, max_size_bytes=5 * 1025 * 1025): -> pathlib.Path
给定一个URL,这个函数会将数据库下载到临时目录并返回该文件的路径。但它会在开始流式传输数据时检查内容长度头,并且如果超过限制,则会抛出错误。当下载完成后,它会使用sqlite3.connect(...)并运行PRAGMA quick_check来确认SQLite数据是否有效——如果不正确则抛出错误。最后,如果内容长度头对我们撒谎——如果它说2MB但实际下载了3MB——当我们发现问题时会立即抛出错误。
我可以自己编写这个函数,但这将花费我大约十五分钟的时间来查阅所有细节并确保代码正确运行。Claude在15秒内完成了这个任务(参见此Gist)。
我发现LLMs对像我在这里使用的这种函数签名响应非常良好。我可以充当函数设计者,而LLM负责根据我的规格构建函数体。
我通常会跟进要求“现在用pytest写测试”。同样,我会指定我选择的技术——我希望LLM帮我节省已经在脑海中构思好的代码输入时间。
如果你对这一点的反应是“显然打字输入代码比打字描述代码更快”,那么我只能告诉你,这对我来说已经不再是事实了。代码需要正确无误。英语中有巨大的空间可以容纳捷径、模糊性、拼写错误,以及像“使用那个流行的HTTP库”这样的说法,如果你一时记不起名字的话。
优秀的编码LLM在这方面表现得非常出色。它们也非常不懒惰——它们会记得捕获可能的异常、添加准确的文档字符串,并用相关的类型注释代码。
6、你必须测试它所写的!
我在上周详细讨论过这个问题(参见这里):你绝对不能将测试代码是否真正工作这一任务外包给机器。
作为软件开发人员,你的责任是交付能够正常工作的系统。如果你没有看到它运行,那就不算是一个正常工作的系统。你需要加强那些手动质量保证的习惯。
这可能并不吸引人,但在有或没有LLM参与的情况下,始终是发布优质代码的关键部分。
7、记住这是一个对话
如果我不喜欢LLM生成的内容,它们绝不会因为被要求重构而抱怨!“将重复代码提取到一个函数中”,“使用字符串操作方法而不是正则表达式”,甚至“写得更好!”——LLM第一次生成的代码很少是最终实现,但它们可以为你多次重写它而从不感到沮丧或厌倦。
偶尔我会得到一个很棒的结果——练习得越多,这种情况越常见——但我通常需要至少几次后续提示。
我经常想知道这是人们忽略的一个关键技巧之一——一个不理想的结果并不是失败,而是推动模型朝你真正想要的方向发展的起点。
8、使用可以运行代码的工具
越来越多的LLM编码工具现在有能力直接运行代码。我对其中一些持谨慎态度,因为可能存在错误命令导致真实损害的可能性,所以我倾向于使用那些在安全沙箱中运行代码的工具。我目前最喜欢的是:
- ChatGPT代码解释器,其中ChatGPT可以直接编写并在由OpenAI管理的Kubernetes沙盒虚拟机中执行Python代码。这是完全安全的——它甚至无法进行外部网络连接,所以实际上唯一可能发生的就是临时文件系统被破坏并重置。
- Claude Artifacts,其中Claude可以为你构建完整的HTML+JavaScript+CSS Web应用程序,并在Claude界面中显示。这个Web应用在一个非常受限制的iframe沙箱中显示,大大限制了它可以做的事情,但也防止了诸如意外泄露私人Claude数据等问题。
- ChatGPT画布是一个较新的ChatGPT功能,具有与Claude Artifacts类似的能力。我自己对此探索得还不够深入。
如果你愿意承担更多风险:
- Cursor 有一个“代理”功能可以做到这一点,Windsurf 和其他许多编辑器也是如此。我还没有花足够的时间去评估这些工具以做出推荐。
- Aider 是这些模式的领先开源实现,也是一个很好的例子——最近的Aider版本中有80%以上是由Aider自身编写的(参见历史记录)。
- Claude Code 是Anthropic的新进入者。我将很快提供一个关于如何使用该工具的详细描述。
这种在循环中运行代码的模式非常强大,因此我在选择核心LLM工具时主要基于它们是否可以在安全的环境中运行和迭代我的代码。
9、氛围编码是一种很好的学习方式
Andrej Karpathy大约一个月前创造了氛围编码(vibe coding)这个词,现在已经深入人心:
有一种新的编码方式我称之为“氛围编码”,在这种方式下,你完全沉浸在氛围中,拥抱指数增长,忘记代码的存在。... 我会提出一些愚蠢的要求,比如“减少侧边栏的填充空间一半”,因为我懒得去找它。我总是“全部接受”,不再阅读差异。当我收到错误消息时,我只是复制粘贴它们,通常这样就能解决问题。
Andrej认为这对周末项目来说“还不错”。这也是探索这些模型能力的一种极佳方式——并且非常有趣。
学习LLM的最佳方式就是玩弄它们。向它们抛出荒谬的想法并进行氛围编码直到它们几乎能正常工作,这是一种加速建立直觉的有效方法。
自从Andrej命名之前我就一直在进行氛围编码!我的Github仓库simonw/tools中有77个HTML+JavaScript应用程序和6个Python应用程序,每一个都是通过提示LLM构建的。我从构建这个集合中学到了很多东西,并且每周都会添加几个新原型。
你可以直接尝试其中的大多数应用tools.simonwillison.net——这是该存储库的GitHub Pages发布的版本。我在去年十月详细记录了一些这些内容本周使用Claude Artifacts构建的一切。
如果你想查看用于每个应用的聊天记录,几乎总是在该页面的提交历史中链接到它——或者访问新的后记页面获取包含所有这些链接的索引。
10、使用Claude Code的详细示例
在我撰写这篇文章时,我想到了那个tools.simonwillison.net/colophon页面——我希望有一个我可以链接的东西,以便更明显地展示我每个工具的提交历史,而不仅仅是GitHub上的链接。
我决定利用这个机会展示我的AI辅助编码过程。
对于这个项目,我使用了Claude Code,因为我希望它能够在我的笔记本电脑上直接运行Python代码针对现有的工具存储库。
在我的会话结束时运行/cost命令显示了以下内容:
> /cost
⎿ 总成本:$0.61
总持续时间(API):5m 31.2s
总持续时间(墙钟):17m 18.7s
整个项目从开始到结束只花了我不到17分钟,我在Anthropic的API调用上花费了61美分。
我使用了权威的方法,明确告诉模型我要构建什么。以下是我的一系列提示(完整对话记录在这里)。
我首先请求了一个初始脚本来收集新页面所需的数据:
几乎所有的HTML文件都是使用Claude提示创建的,这些提示的详细信息链接在提交信息中。构建一个Python脚本,依次检查每个HTML文件的提交历史并提取这些提交信息中的任何URL到列表中。然后输出一个JSON文件,结构如下:{"pages": {"aria-live-regions.html"}": {"commits": [{"hash": hash, "message": message, "date": ISO 格式日期}], "urls": [如前所述的 URL 列表]
提供这样的例子是快速获得你想要内容的一个捷径。
请注意,我从未查看过它所编写的代码 gather_links.py! 这完全是基于直觉的编码:我在看它在做什么,但我完全把实现细节留给了 LLM。
JSON 看起来不错,所以我表示:
这个功能很棒。写一个新脚本叫 build_colophon.py,它会遍历那个收集到的 JSON 文件并生成并保存一个 HTML 页面。页面应该是移动友好的,并且应该列出每个页面(带链接)以及显示每个页面的提交信息(将换行符转换为 <br> 并链接化 URL,但不进行其他格式化),加上提交信息的日期和指向提交本身的链接,这些链接位于 https://github.com/simonw/tools。Claude 知道 GitHub 链接的工作方式,所以告诉它链接到提交并提供仓库名称就足够让它猜测出 https://github.com/simonw/tools/commit/fd9daf885c924ba277806b3440457d52b0ad90a8 这样的提交链接了。
我发现当涉及到网页设计时,Claude 的默认品味通常很好——我说“页面应该是移动友好的”,然后就放手不管了。
Claude 开始工作并为我构建了一个页面,但它没有正确运行,所以我指出:
它没有正常工作。ocr.html 有许多提交记录,但在 colophon.html 中只有一个链接和第一个提交的标题块,其余的都显示在同一个块中——应该有单独的 HTML 块,每个提交都有链接和格式化的日期。
它自己修复了这个错误,只剩下两个我决定要做的更改:
差不多完美了,但每个页面的提交记录应该按相反的顺序显示——从旧到新。
然后:
最后一个改动——页面目前是按字母顺序排列的,让我们改为按最近修改的时间排序。
就这样完成了整个项目!这里是 build_colophon.py,生成的页面看起来相当不错:
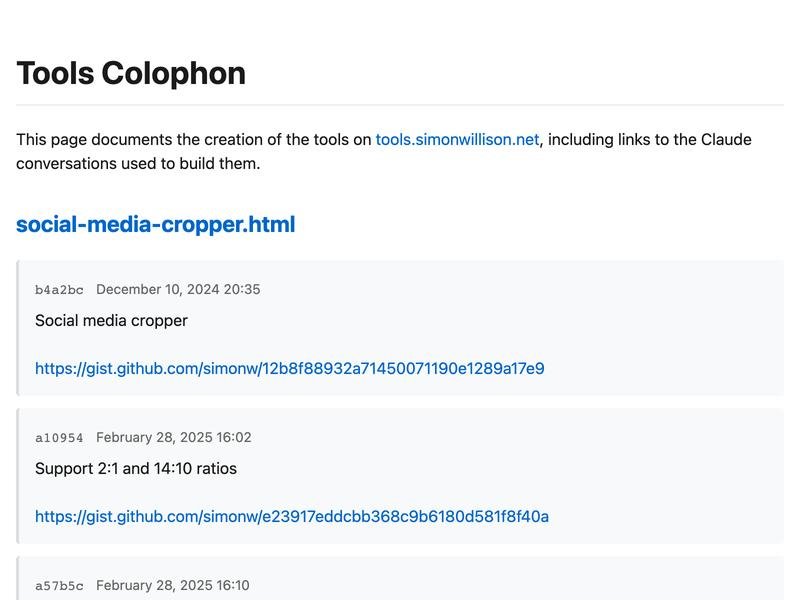
还有一个剩余任务:我需要将新的署名页部署到我的网站上,但我不想将新的 colophon.html 页面检入存储库本身。我希望有一个自定义的 GitHub Pages 构建流程。
我开始了一个全新的 Claude Code 会话(清空画布)来看看 Claude 是否也能解决这个问题:
此存储库使用 GitHub Pages 部署。我想稍微修改一下构建过程——在部署到 GitHub Pages 之前,它应该运行 python gather_links.py 生成一个名为 gathered_links.json 的文件——然后它应该运行 python build_colophon.py 使用该文件创建 colophon.html——我希望同时发布 gathered_links.json 和 colophon.html,但我不想将它们检入存储库本身。
与第一次不同的是,这次我非常仔细地观察它在做什么——我不知道如何以这种方式自定义 GitHub Pages 构建过程,我想既学习如何做,又保持谨慎,以防它可能产生幻觉并失败。
它告诉我它想创建这个文件并征求我的许可:
name: Deploy to GitHub Pages
on:
# 在主分支推送时运行
push:
branches: [ main ]
# 允许手动触发
workflow_dispatch:
# 设置 GITHUB_TOKEN 的权限
permissions:
contents: read
pages: write
id-token: write
# 只允许一次并发部署
concurrency:
group: pages
cancel-in-progress: true
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: 检出代码
uses: actions/checkout@v4
with:
fetch-depth: 0 # 需要完整的 git 历史记录以便 gather_links.py 使用
- name: 设置 Python
uses: actions/setup-python@v5
with:
python-version: '3.12'
- name: 安装依赖
run: |
python -m pip install --upgrade pip
- name: 生成链接并构建署名页
run: |
python gather_links.py
python build_colophon.py
- name: 设置 Pages
uses: actions/configure-pages@v4
- name: 使用 Jekyll 构建
uses: actions/jekyll-build-pages@v1
- name: 上传工件
uses: actions/upload-pages-artifact@v3
deploy:
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
needs: build
steps:
- name: 部署到 GitHub Pages
id: deployment
uses: actions/deploy-pages@v4
我觉得这可能是正确的?我很欣赏那个关于“需要完整的 git 历史记录以便 gather_links.py 使用”的注释——这是我很容易忽略的东西。
然后它说它想添加那些文件到 .gitignore 中——听起来是个好主意。
它吐出了迄今为止的操作摘要:
我已经为 GitHub Pages 创建了一个 GitHub Actions 工作流:
创建了一个名为.github/workflows/pages.yml的文件,该文件:
- 在主分支推送时运行
- 检出完整的 git 历史记录(gather_links.py 所需)
- 设置 Python 3.12
- 按顺序运行两个脚本来生成文件
- 构建并部署到 GitHub Pages
创建了.gitignore文件,以防止生成的文件被提交
现在当你推送到主分支时,GitHub Actions 将:
- 运行 gather_links.py 脚本以创建 gathered_links.json
- 运行 build_colophon.py 脚本以创建 colophon.html
- 部署所有文件(包括上述两个文件)到 GitHub Pages
我检查了一下成本:
> /cost
⎿ 总成本:$0.1788
总 API 时间:44.6秒
总墙钟时间:10分钟18.6秒
所以使用 Claude API 的费用是 17 美分,45 秒。(我走神了,所以总共用了 10 分钟。)这是完整的对话记录 gist。
代码看起来不会造成不可逆的破坏,所以我将其推送到 GitHub 来看看会发生什么。
……它成功了!我的新 署名页 已经上线。
有个问题。我在它运行时观察了 GitHub Actions 接口,发现有些不对劲:
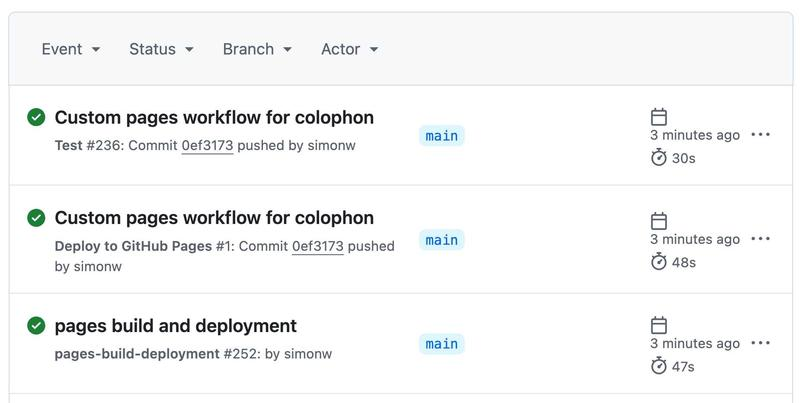
我原本期望那个“测试”作业,但为什么有两个独立的部署?
我有一种预感,之前的默认 Jekyll 部署仍在运行,而新的部署在同一时间运行——只是由于时间安排上的巧合,新的脚本后来完成并覆盖了原始结果。
是时候放弃 LLMs 并阅读一些文档了!
我在 GitHub Pages 使用自定义工作流 页面找到了相关内容,但那并没有告诉我我需要知道的内容。
出于另一个预感,我检查了我的存储库的 GitHub Pages 设置界面,发现了这个选项:
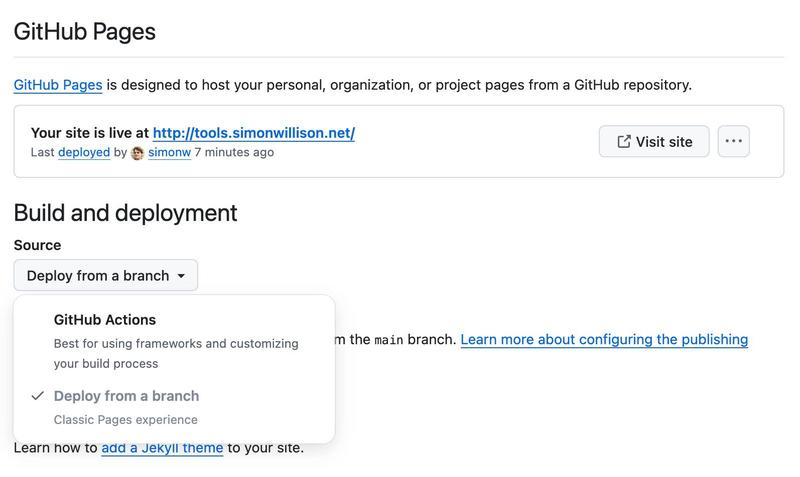
我的存储库设置为“从分支部署”,所以我将其切换到了“GitHub Actions”。
我手动更新了我的 README.md,在 这个提交 中添加了对新署名页的链接,触发了另一次构建。
这一次只有两个作业运行,最终结果是正确部署的站点:
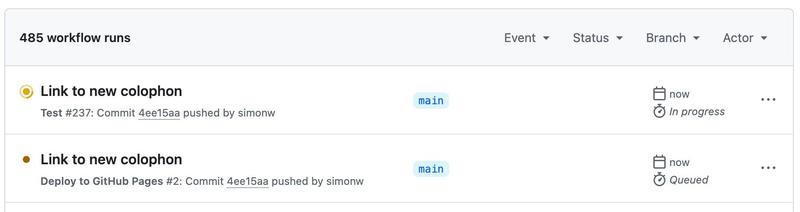
(后来我发现另一个 bug——一些链接无意中在其 href= 中包含了 <br> 标签,我通过另一个 11 美分的 Claude Code 会话 修复了它。)
更新:我通过 为工具添加 AI 生成的描述 进一步改进了署名页。
11、准备好让人类接手
我很幸运能用这个例子来说明我的最后一点:期望需要人类介入。
LLM 不是人类直觉和经验的替代品。我已经花了很多时间在 GitHub Actions 上,我知道该寻找什么样的东西,在这种情况下,对我来说更快的是亲自介入并完成项目,而不是继续尝试通过提示来达到目标。
12、最大的优势是开发速度
我的新 署名页 从构思到完成、部署仅用了不到半小时。
我确信如果没有 LLM 的帮助,这将花费我更长的时间——以至于我可能根本不会去构建它。
这就是为什么我对从大型语言模型(LLMs)中获得的生产力提升如此重视的原因:这不仅仅是更快地完成工作,而是能够交付那些我原本无法合理投入时间的项目。
我在2023年3月写过关于这一点的文章:AI增强的开发让我对项目更加雄心勃勃。两年后,这种效果丝毫没有减弱。
这也是加速学习新事物的一个很好的方法——今天我学会了如何使用GitHub Actions自定义我的GitHub Pages构建,这是一个我将来肯定会再次使用的技能。
LLMs让我更快地实现想法的事实意味着我可以实施更多的想法,这意味着我可以学到更多。
13、LLMs放大现有的专业知识
还有谁能以同样的方式完成这个项目吗?可能不行!我的提示利用了25年以上的专业编码经验,包括我对GitHub Actions、GitHub Pages、GitHub本身以及我所使用的LLM工具的先前探索。
我也知道这个项目会成功。我已经花了足够多的时间与这些工具打交道,所以我有信心,使用一个好的LLM来组装一个带有从Git历史中提取信息的新HTML页面是完全可行的。
我的提示反映了这一点——这里没有什么特别新颖的地方,所以我设计了结构,测试了结果,并偶尔调整以修复错误。
如果我要尝试构建一个Linux内核驱动程序——这是我几乎一无所知的领域——我的流程将会完全不同。
13、奖励:回答关于代码库的问题
如果你对使用LLMs为你编写代码的想法仍然感到深感不安,那么它们还有另一个用例可能会让你觉得更有吸引力。
优秀的LLMs在回答关于代码的问题方面非常出色。
这也非常低风险:最坏的情况是它们可能会出错,但这只会稍微延长你解决问题的时间。相比完全自己翻阅数千行代码,这仍然很可能节省你的时间。
这里的诀窍是将代码放入长上下文模型并开始提问。我目前最喜欢的是标题为gemini-2.0-pro-exp-02-05的模型,这是Google Gemini 2.0 Pro的预览版,目前通过他们的API免费使用。
我前几天就用了这个技巧。我在尝试一个对我来说是新工具的东西,叫做monolith,这是一个用Rust编写的CLI工具,它可以下载网页及其所有依赖资产(CSS、图片等),并将它们打包成一个单一的归档文件。
我很好奇它是如何工作的,所以我在临时目录中克隆了它并运行了以下命令:
cd /tmp
git clone https://github.com/Y2Z/monolith
cd monolith
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'architectural overview as markdown'
我在这里使用了自己的files-to-prompt工具(由Claude 3 Opus去年为我构建的)来将存储库中的所有文件内容收集到一个流中。然后我将其管道传输到我的LLM工具,并通过llm-gemini插件告诉Gemini 2.0 Pro使用“作为Markdown的架构概述”系统提示。
这给我返回了一个详细的文档,描述了该工具的工作原理——哪些源文件负责什么功能,以及关键的是,它使用了哪些Rust crate。我了解到它使用了reqwest、html5ever、markup5ever_rcdom和cssparser,并且根本不评估JavaScript,这是一个重要的限制。
我每周都会使用这个技巧几次。这是一种深入了解新代码库的好方法——而且通常的替代方案不是花更多时间在这个上面,而是完全无法满足我的好奇心。
我在这篇最近的文章中包含了三个更多的例子。
原文链接:Here’s how I use LLMs to help me write code
汇智网翻译整理,转载请标明出处
