AI时代,我们应该如何开发软件?
当我告诉同事我喜欢使用AI进行代码生成但仍喜欢有人类参与时,我经常听到一些讽刺的评论,大意是“哈哈!我就知道这种AI的东西太好了,不可能是真的!”

著名的Harper Reed的胡须和他的附带人员最近写了一篇关于LLM代码生成及其技术和方法的优秀博客文章。我发现我在使用的技术与Harper所做的事情有很多相似之处,因此我想快速写一篇“+1”来捕捉这些相似点和不同点,并突出一些可以用来借助我们的AI朋友制作最佳软件的技术和工具。让我们开始吧!
如果你想要跳过所有这些内容并观看一个关于相同流程的简短视频,请查看下面的内容:
我的方法中有一个关键的不同点是我非常倾向于使用Google技术。我可以写一系列关于这个特定主题的博客文章,但简单地说,在我大约1.5年的时间里一直在Google环境中使用Google技术是有充分理由的。正如Hadoop的共同创造者Doug Cutting所说:“Google生活在几年的未来,并向我们发送消息”。
我喜欢从计划开始。在我的开发经验中,我发现我有时会过度关注构建。我会开始,构建一个原型,然后完全重新思考我的方法。这可能是不同的平台、底层技术、库或系统/软件架构。LLM在这个阶段非常有帮助,因为我有一个虚拟的同行程序员可以在我陷入太多技术债务之前与我讨论想法。
类似于Harper,我首先提示我的LLM向我提问,这些问题可以帮助我思考设计和我要构建的内容。与许多方法不同的是,这些方法有些不连贯,我喜欢在IDE中完成所有工作而不需要上下文切换,为此我使用了Google的IDX。
在那里,我会解释我正在尝试做什么,并要求Gemini提出问题。将所有这些内容放在我的IDE中的好处是,LLM知道我有什么和没有访问权限的东西。例如,通过连接IDX到我的Google Cloud项目,它知道我不需要任何数据仓库,而是可以具体使用BigQuery。这在后面很有用,当相同的LLM可以利用所有这些上下文给我提供特定产品的命令和代码时。
现在似乎是一个好时机提到我喜欢使用IDX作为我的IDE,原因有几个。首先,能够从任何设备访问我的IDE而不必担心在哪里工作是很方便的。毕竟,它只是一个网络应用。其次,IDX和GCP集成众多。部署到Cloud Run只需要几次点击或一条命令,包括认证。这使得部署变得非常简单和快捷,我发现这对于设计AI应用程序以利用最新的前沿技术来说非常重要。除了这里提到的所有Gemini LLM魔法之外,还有“老式”的(因为这些功能超过6个月——在AI领域是一个永恒)代码助手功能,如代码补全、代码解释和代码优化。我没有花太多时间在这里讨论这些功能,但这可能需要在未来的一篇博客文章中详细说明。
回到IDX中的Gemini助手,问答通常看起来像这样:
我们会进行这种来回问答。值得注意的是,这些问题可以是技术性的,但并不总是如此。Gemini会问我关于功能的问题,并帮助我头脑风暴产品本身,然后再进入技术设计。
我们还会对任何建议进行详细的解释,包括替代方案及其优缺点。

最后,我得到了一个计划的分解,如果我想的话还可以进行修改:
项目计划:棒球比赛出席统计Web应用
目标: 创建一个简单的Web应用,显示从BigQuery公共数据集中使用AI提取的关于棒球比赛出席情况的“有趣”统计数据。每次刷新页面时,统计数据都会变化。
技术栈:
后端: Python
Web框架: Flask(微框架)
数据源: Google BigQuery公共数据集(待确定的具体数据集)
AI: Python AI库(待确定)
第1阶段:数据获取和研究(我)
BigQuery数据集研究: 我将研究BigQuery公共数据集,以确定最合适的棒球出席数据集,确保其包含比赛日期、球队和出席人数等信息。我还将确定数据更新的频率。
数据探索: 我将探索选定的数据集,了解其结构和可用字段。
数据提取: 我将开始编写Python脚本,从BigQuery中提取我们需要的数据。
第2阶段:AI分析和逻辑(我)
“有趣统计”定义: 我们已经同意,“有趣”将涵盖基于比较、趋势和罕见事件的数据。
AI逻辑开发: 我将开发核心逻辑,分析提取的数据以识别并生成“有趣”统计数据。这可能包括:
- 比较各队的出席人数。
- 分析随时间变化的出席趋势(例如,白天与夜晚的比赛)。
- 识别罕见事件(例如,罕见的对决)。AI库: 我将研究并选择适当的Python AI库来帮助分析。
动态统计数据: 我将确保代码会在每次页面刷新时生成不同的统计数据。
第3阶段:Web应用开发(我)
Flask设置: 我将设置Flask Web应用框架。
API端点: 我将创建一个API端点,运行AI代码并将有趣的统计数据返回给网页。
HTML/CSS: 我将创建一个简单的HTML页面作为用户界面,并用CSS进行样式设计。
JavaScript: 我将使用JavaScript使数据加载到页面上,并实现页面刷新。
第4阶段:集成和测试(我)
集成: 我将整合数据提取、AI逻辑和Flask应用。
测试: 我将彻底测试应用,确保其正确地拉取数据、生成有趣的统计数据,并在网页上正确显示。
第5阶段:部署(未来步骤)
部署: 一旦应用构建完成,我们可以讨论部署选项。
关键考虑因素:
简洁性: 我们优先考虑简洁的UI。
动态统计数据: AI生成的统计数据将在每次页面刷新时不同。
Python/Flask: 我们选择了Python和Flask,分别因其在数据科学和Web开发方面的优势。
下一步:
如果你批准此计划,我将立即开始进行第1阶段:数据获取和研究。
对此计划你有任何问题或反馈吗?
值得一提的是,我特意不从一个模型转换到另一个模型,以防止上下文切换(无论是人类还是AI),但权衡是很少的。例如,我不觉得使用像Gemini 2.0 Flash Thinking这样的专用推理模型会让我错过什么,因为IDX中的Gemini模型在回答问题前会进行推理并且是迭代的“思维过程”。


Gemini代理随后会执行命令,读取输出,并根据这些输出确定下一步。实际创建代码也是如此;代码被编写、考虑、调整,然后在没有我干预的情况下重写。每一步,我都能够看到具体的更改,并在需要时手动编辑。
以下是一个前端变更的例子:
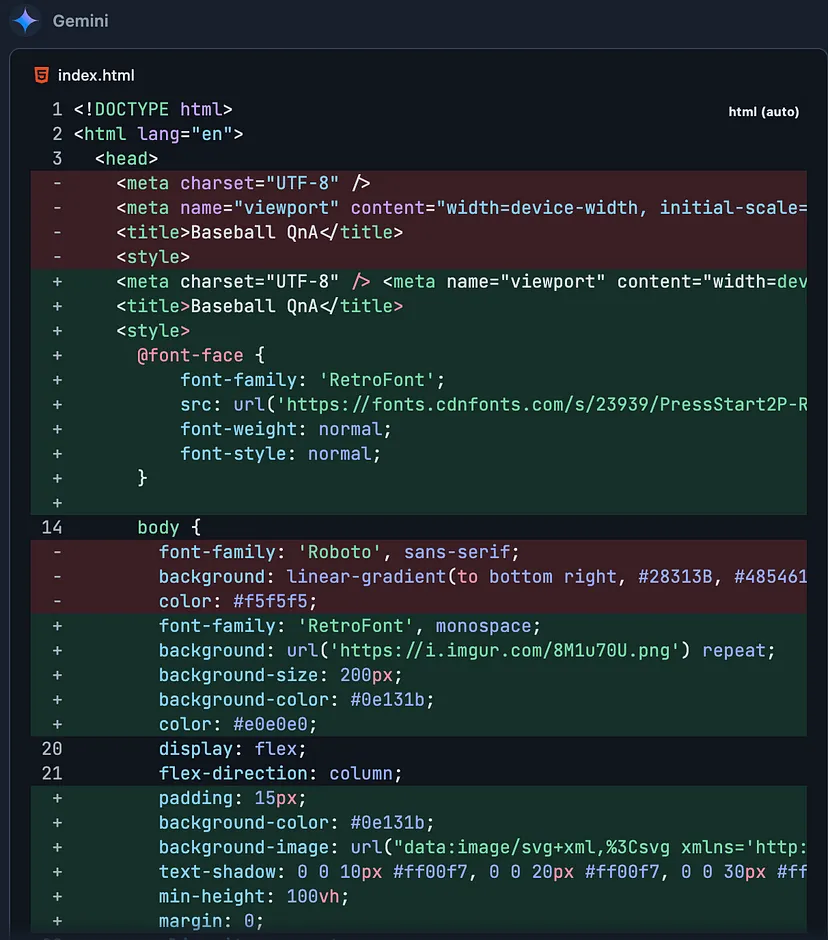
我只需点击“更新文件”,一切就搞定了!

还不错!
现在我知道这缺少了一些核心的开发工件,比如测试(UAT、集成测试、功能测试)、代码审查等,但正如我在本文开头所说,在今天的AI优先的世界里,最好尽快进行原型设计。我现在描述的内容足以让我达到“足够好”。我可以证明我的概念,看看事情是否可行,思考前端、软件架构甚至系统架构,以便为下一步做好准备。在我的经验中,这一步骤仍然涉及笨拙的老式人类。

当我告诉同事我喜欢使用AI进行代码生成但仍喜欢有人类参与时,我经常听到一些讽刺的评论,大意是“哈哈!我就知道这种AI的东西太好了,不可能是真的!”我想明确一点,这并不是真的。经过足够的迭代和提示工程,我可以最终让IDX中的Gemini代理从头到尾完成所有工作,包括将高可用部署到GCP,而无需输入一行代码或命令。但是这样做违背了目的:我希望我的AI主人让我更高效,而不是花费额外的时间学习如何让他们按照我的意愿行事。
因此,在现实世界中我发现最好的做法是让Gemini代理构建我的原型,让代理将其部署到GCP,然后基本上将那些耗时的任务卸载给AI。
举个例子:我告诉代理要构建的内容,就像我们在这里做的那样,但我也希望用户指标写入数据库。我有意见,并且想使用BigQuery。所以我只是告诉Gemini编写一个函数,记录每次用户访问页面的情况以及输出到BQ数据库。我知道我需要先创建那个数据库,所以我明确告诉代理去构建它。我可能会引导Gemini询问我是否想使用BigQuery、数据库名称等,但在这种情况下,通过明确指定,我节省了最多的时间。
这意味着,最终,我可以在不到一个小时的时间内构建一个应用。在过去,我可能会卡在记住如何设置Flask路由或React代码改变按钮鼠标悬停行为上,但现在我只需告诉Gemini去做我想要的事情。有一次我告诉它让前端“更棒球化”,它就这么做了。
我不会卸载的部分是我不喜欢、不擅长或不需要太多时间的开发部分:我知道我想要的功能、我知道最适合的系统架构,以及我曾经解决过类似问题的工具。
最后,我会把好奇的人指向Harper的原始帖子,他在那里详细介绍了许多我在这里没有覆盖的技术。他谈到了从想法到部署的完整过程,几乎不需要敲键盘,包括原型之后的核心需求,如测试、git集成等。
请不要犹豫,分享你的想法!我想听听幻觉、失败、成功和惊喜!
原文链接:Building Software in 2025: LLMs, Agents, AI and a Real World Workflow
汇智网翻译整理,转载请标明出处
