本地AI驱动的图片标记工具
在本文中,我将介绍如何构建 AI 图像标记器/管理器,包括设置和运行本地视觉语言模型和用于语义搜索的矢量数据库。
是否曾经花 20 分钟浏览文件夹以找到脑海中的一张特定图像或屏幕截图?你并不孤单。
作为工作中的产品经理,我总是淹没在竞争对手产品的屏幕截图、UI 灵感以及白板会议或草图的照片中。在我的个人生活中,我总是拍下生活中遇到的东西,比如我的晚餐、我可爱的猫咪,或者秋天里一片美丽的树叶。我太了解这种挣扎了。有时很难找到你知道自己保存在某个地方的特定图像。
随着开源视觉语言模型 Llama 3.2 Vision 的最近发布,我想到了一个解决这个问题的方法:一个本地运行的 AI 工具,它可以自动描述和标记图像,以便于进行语义搜索,同时将照片和标签完全保持在本地(并且没有 API 费用)
在本文中,我将介绍如何构建 AI 图像标记器/管理器,包括设置和运行本地视觉语言模型和用于语义搜索的矢量数据库。无论你是对运行本地视觉语言模型感兴趣的 AI 爱好者,还是厌倦了在图像文件夹中进行痛苦搜索的人,这对你来说都是一个有趣且有用的项目。让我们开始吧!
该项目在 GitHub上开源。请随意克隆并试用!
1、查看实际操作
前端用于管理图像集合相对简单。它使用 Vue3 构建以实现交互性,使用 TailwindCSS 构建以实现样式。它通过 FastAPI 服务器与后端通信,该服务器在视觉模型、矢量数据库和文件系统之间进行协调。让我们看看它是如何工作的。
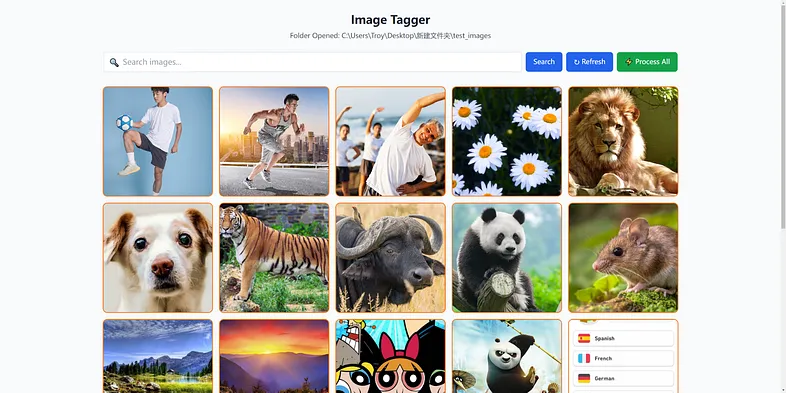
当它启动时,它会要求你提供包含图像的文件夹。只需复制并粘贴文件夹路径,它就会开始扫描文件夹和子文件夹中的图像。第一次打开文件夹时,它还会初始化用于存储数据的矢量数据库,这可能需要一段时间。
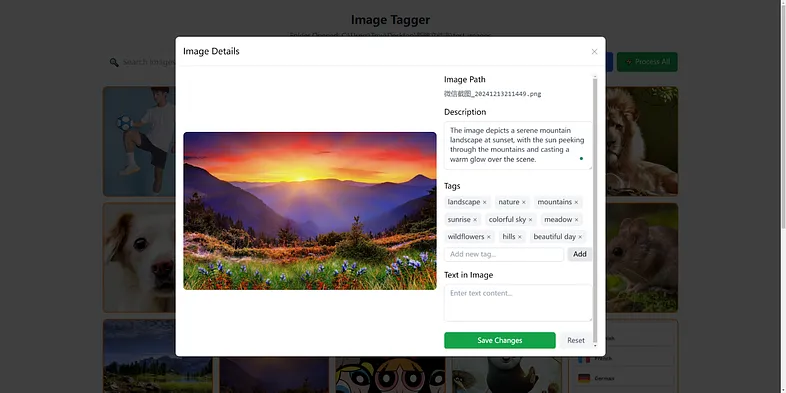
图像加载后,你可以单击单个图像开始标记。它将向本地后端服务器发送请求并为图像生成标签。如果你对结果不满意,也可以手动编辑结果。所有生成/编辑的标签都将同步到矢量数据库
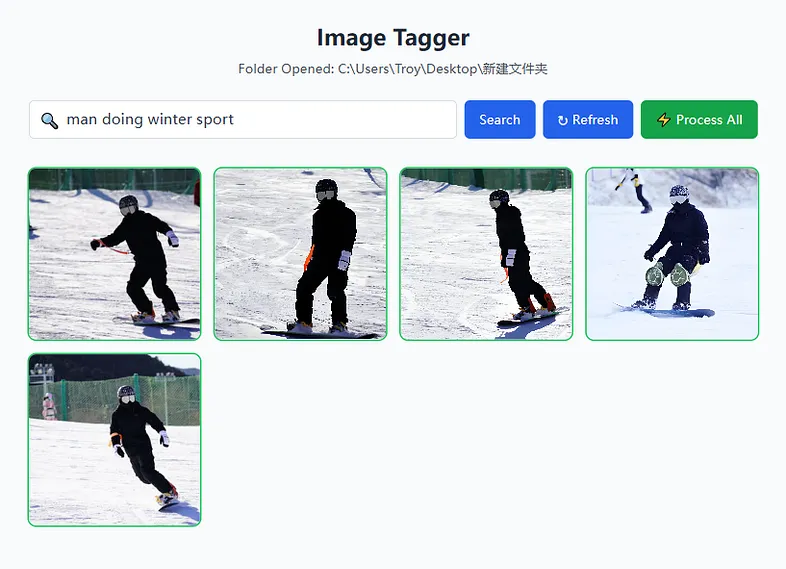
对于批处理,你只需按下此“全部处理”按钮,它将发送所有图像进行处理。速度取决于您的计算机。如果你的 GPU 具有足够的 VRAM 来运行模型,它将比在带有 RAM 的 CPU 上运行模型快得多。已处理的图像将具有绿色轮廓,尚未处理的图像将显示为橙色。
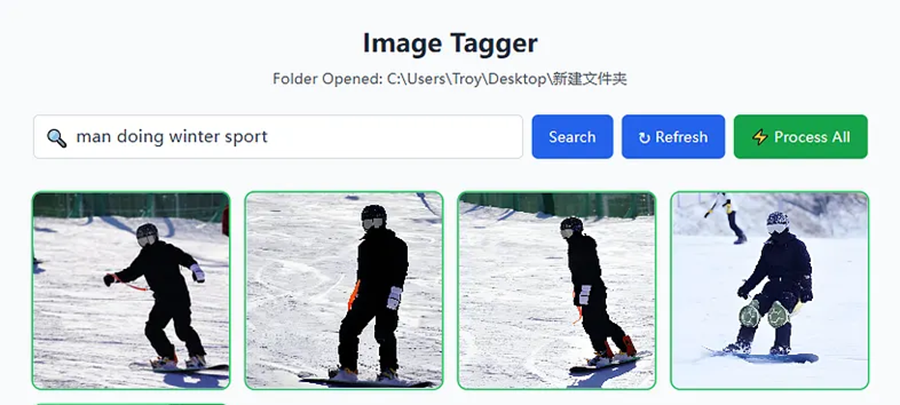
图像处理和标记后,你只需在搜索栏中输入要搜索的内容即可。它将执行全文搜索和向量相似性搜索的混合搜索。在这里,我们可以搜索带有“男子从事冬季运动”模糊描述的滑雪板图像。
2、了解技术栈
对于这个项目,我们使用 Llama 3.2 Vision、Ollama 和 ChromaDB。对于那些还不熟悉它们的人,让我快速概述一下。
Llama 3.2 Vision 是 Meta 几个月前于 2024 年 9 月发布的视觉语言模型 (VLM)。它有两种不同的尺寸,11B 和 90B。11B 版本可以在消费级计算机上本地运行。作为 VLM,它不仅可以像大型语言模型 (LLM) 一样理解文本,还可以理解上下文中的图像。它可以描述场景,理解对象之间的关系,并根据您的指示根据图像生成文本。借助这个模型,我们可以生成丰富的语义标签,而不仅仅是简单的对象检测。
Ollama 是一个开源项目,它允许我们在本地机器上轻松运行语言模型。它适用于 Windows、MacOS 和 Linux,支持几乎所有 GGUF 格式的本地语言模型,这使其成为在您自己的计算机上运行本地模型最方便的选择。它还提供 Python 和 JavaScript 绑定,以便您可以在代码中以编程方式调用模型。更棒的是,它最近增加了对生成 JSON 等结构化输出的支持,使文本生成变得更加容易。
至于我们的语义搜索,我们将使用 ChromaDB。这是一个开源矢量数据库,允许您保存文本嵌入数据并以闪电般的速度使用自然语言查询它们。例如,您不必使用“游泳”等精确的关键字进行搜索,而是可以使用“水上运动”、“水上运动”或“浮潜”。像 ChromaDB 这样的矢量数据库通过将我们的图像描述转换为捕获语义含义的高维向量并计算嵌入之间的相似性来实现这一点。
现在我们已经了解了这个项目的组件,在下一节中,我们将深入研究这些组件如何协同工作以创建我们的图像标记和搜索系统。
3、深入研究代码
让我们分解一下这些组件如何协同工作以创建我们的图像管理系统。由于在浏览器中访问文件系统的限制,我将应用程序分为前端和后端。前端用于查看和管理图像,后端主要包含两个管道:图像标记管道和图像查询管道。
3.1 使用 Ollama 和 Llama3.2 Vision 的图像标记管道
当选择一个文件夹时,我们将扫描该文件夹以查找文件夹中的所有图像。然后用户可以选择一个图像进行标记或标记所有图像。它本质上是具有结构化输出的简单提示工程。让我们向你介绍如何在您自己的本地计算机上使用 Ollama 运行 Llama 3.2 Vision 模型。
首先,需要在你的机器上安装 Ollama。感谢伟大的 Ollama 团队,他们为 Windows、MacOS 和 Linux 提供了简单的下载,只需下载并安装可执行文件,你就可以使用 Ollama 命令行。然后,可以使用以下命令下载 Llama3.2 Vision:
ollama run llama3.2-vision
// if you have a really powerful machine, you can use ollama run llama3.2-vision:90b to get the bigger version一旦提取了模型,就可以通过命令行或通过 Python 库使用它。在我们的项目中,我们将使用 ollama-python 库,可以使用以下命令安装它:
pip install ollama安装后,我们可以使用 Python 与模型进行交互。 Ollama 最近添加了对结构化输出 (JSON) 的支持,因此我们可以使用 Pydantic 定义 JSON 模式并将其传递给模型以进行类型安全和验证:
import ollama
from pydantic import BaseModel
from pathlib import Path
from typing import List, Dict
class ImageTags(BaseModel):
tags: List[str]
def process_image(image_path: Path) -> Dict:
try:
# Ensure image path exists
if not image_path.exists():
raise FileNotFoundError(f"Image not found: {image_path}")
# Convert image path to string for Ollama
image_path_str = str(image_path)
# Get tags
tags_response = get_tags(image_path_str)
return {
"tags": tags_response.tags
}
except Exception as e:
raise
def get_tags(image_path: str) -> ImageTags:
"""Get structured tags for the image."""
response = query_ollama(
"List 5-10 relevant tags for this image. Include both objects, artistic style, type of image, color, etc.",
image_path,
ImageTags.model_json_schema()
)
return ImageTags.model_validate_json(response)这里我仅展示了 get_tags 函数以获取标签列表,但也可以添加其他数据,如描述、图像中的对象、图像上的 OCR 文本等。只需为每个提示编写一个不同的提示,然后调用 Ollama,类似于调用 OpenAI 的 API:
def query_ollama(prompt: str, image_path: str, format_schema: dict) -> str:
"""Send a query to Ollama with an image for structured output."""
try:
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': prompt,
'images': [image_path],
'options': {
'num_gpu': 41
}
}],
format=format_schema
)
return response['message']['content']
except Exception as e:
raise使用类似的设置,你可以在自己的计算机上使用 Ollama 轻松运行其他 LLM 或视觉语言模型。可以在 Ollama 模型库 中找到可用模型的列表。
3.2 使用向量数据库的语义查询管道
一旦我们标记了所有图像,我们就可以保存它以便于查询。对于全文搜索,我们可以简单地将数据保存到 JSON 或关系数据库中。但如果只有全文搜索,仍然很难找到相关的图像——有时你可能只是对你想要的图像有一个模糊的概念,而不是确切的标签,例如,你可能记得你有一张你吃着一顿丰盛晚餐的照片,但你记不起确切的菜。因此,我们将标签和描述保存到向量数据库中,并使用可以捕获语义含义的嵌入相似性搜索来检索它们。
ChromaDB 易于设置,可以完全离线运行它。我们的向量存储实现的核心是 VectorStore 类。它处理与 ChromaDB 的所有交互,包括添加新图像、更新现有的,并执行语义搜索。
设置和保存数据到 ChromaDB 非常简单:
def add_or_update_image(self, image_path: str, metadata: Dict) -> None:
# Combine all text fields for embedding
text_to_embed = f"{metadata.get('description', '')} {' '.join(metadata.get('tags', []))} {metadata.get('text_content', '')}"
# Prepare metadata dict - ChromaDB requires string values
meta_dict = {
"description": metadata.get("description", ""),
"tags": ",".join(metadata.get("tags", [])),
"text_content": metadata.get("text_content", ""),
"is_processed": str(metadata.get("is_processed", False))
}
# Check if document exists and update or add accordingly
results = self.collection.get(ids=[image_path])
if results and results['ids']:
self.collection.update(
ids=[image_path],
documents=[text_to_embed],
metadatas=[meta_dict]
)
else:
self.collection.add(
ids=[image_path],
documents=[text_to_embed],
metadatas=[meta_dict]
)在此函数中,我们做了一些重要的事情:
- 将所有文本字段(描述、标签、文本内容)组合成一个字符串以进行嵌入
- 将元数据转换为 ChromaDB 可以存储的格式(所有值都必须是字符串)
- 如果数据库中没有图像数据,则添加图像数据;如果图像数据已存在,则更新图像数据
现在我们已经存储了数据,让我们看看如何搜索它。 ChromaDB 提供了查询数据库的简便方法:
def search_images(self, query: str, limit: int = 5) -> List[str]:
results = self.collection.query(
query_texts=[query],
n_results=limit,
include=['documents', 'metadatas', 'distances']
)
filtered_results = []
for image_id, distance in zip(results['ids'][0], results['distances'][0]):
if distance < 1.1: # Only include high-confidence matches
filtered_results.append(image_id)
return filtered_results[:limit]ChromaDB 使用相同的嵌入模型将你的搜索查询和存储的图像描述转换为高维向量。然后,它会根据相似性找到最接近的匹配项。这意味着搜索“海滩度假”可能会匹配标有“热带天堂”或“海滨度假胜地”的图片,即使这些确切的词不在您的查询中。我还添加了对最大距离的检查,以便过滤掉不相关的结果。
通过结合全文搜索和矢量搜索的混合搜索方法,我们可以确保在确定时使用全文搜索准确找到我们想要的内容,在不确定时找到相关图像。
这是后端处理图像标记和语义查询的两个主要组件。通过了解它们的工作原理,您还可以学习如何使用 Ollama 在本地计算机上运行多模态视觉语言模型(或任何 LLM),以及如何设置矢量数据库并使用 ChromaDB 等矢量数据库对文本进行语义查询。这些对于许多其他基于本地 LLM 的项目非常有用。
4、一些进一步的改进
当前版本只是初始版本,非常适合我个人查找屏幕截图和个人照片。有很多方法可以改进它:
- 图像相似性搜索:不仅仅是通过文本搜索,还允许用户选择图像并找到视觉上相似的图像。但不幸的是,Ollama 目前不支持多模态嵌入。我们可以使用其他嵌入模型(如 CLIP)并将嵌入保存到 ChromaDB。
- 可自定义标记:目前标记提示是硬编码在代码中的,但我们可以允许更灵活的方式来定义提示,以便不同的用户可以拥有符合他们需求的不同标记。例如,UI 设计师可能希望专门标记界面元素,而摄影师可能更关心构图和灯光。
- 更强大的视觉模型:我发现较小的 11B 版本的 llama 3.2 vision 有时会误解图像。幸运的是,模型公司不断推出新的开源模型,例如 Qwen 最近发布的 QvQ 模型。我们可以允许交换视觉模型,以便更准确、更详细地标记图像。
- 允许视觉模型 API。对于那些不太关心将图像发送给模型提供商的人,我们可以允许他们使用视觉语言模型的 API,以便标记过程可以更快(Gemini、Qwen、OpenAI 等)。
5、结束语:释放本地视觉模型的潜力
这个项目最让我兴奋的不仅仅是我自己解决了图像搜索问题,而是开源多模态 AI 模型变得如此容易访问。就像本地大型语言模型允许我们创建完全在本地机器上运行的有趣的基于文本的应用程序一样,视觉语言模型开辟了更多的可能性。
这只是可能性的一个例子使用本地视觉语言模型。相同的基本组件:使用 Ollama + 矢量数据库运行本地模型,可以适应更多用例。
如果你对构建 AI 驱动的应用程序感到好奇,但又担心复杂性、隐私或 API 成本,我希望这个项目能比您想象的更容易理解。请随意提取代码进行尝试,甚至更好地为该项目做出贡献。你还可以修改它,并将其作为自己项目的起点。
原文链接:Local AI vision for your photos: build AI image tagger with Llama vision and ChromaDB
汇智网翻译整理,转载请标明出处
