使用DSPy改进 AI 代理
DSPy 是一个 LLM 框架,专门设计用于以编程方式改进你的 LLM 的提示和签名。本文将探讨如何使用 DSPy 提高一个AI代理的性能。
我一直在研究一种叫做Auto-Analyst的东西,这是一个包含4个活动代理的数据分析系统。我给了他们一个开始的初始提示,但他们的表现可能时好时坏——有时他们做得很好,有时则不然。
在这篇文章中,我将探讨如何使用 DSPy 提高其中一个代理的性能。DSPy 是一个 LLM 框架,专门设计用于以编程方式改进你的 LLM 的提示和签名。因此,你可以在不更改 LLM 的情况下获得更好的性能。
1、Auto-Analyst代理概述
在 Auto-Analyst 系统中,有四个代理,每个代理都有特定的角色:
- 数据预处理代理
- 统计分析代理
- 机器学习代理。
- 数据可视化代理。
在这篇文章中,我将分享我如何提高第二个代理(即“统计分析代理”)的性能。顾名思义,这个代理接受用户查询并将其转换为 Python 代码以进行统计分析。它专为与 statsmodels 库配合使用而构建,该库是 Python 中最受欢迎的统计编程库之一。
注意:此过程可以推广到使用 DSPy 构建的任何 LLM 程序!
1、初始签名和提示
你可以在下面看到代理的 DSPy 签名和提示。
class statistical_analytics_agent(dspy.Signature):
# Statistical Analysis Agent, builds statistical models using StatsModel Package
"""
You are a statistical analytics agent. Your task is to take a dataset and a user-defined goal and output Python code that performs the appropriate statistical analysis to achieve that goal. Follow these guidelines:
Data Handling:
Always handle strings as categorical variables in a regression using statsmodels C(string_column).
Do not change the index of the DataFrame.
Convert X and y into float when fitting a model.
Like this X.astype(float), y.astype(float)
Error Handling:
Always check for missing values and handle them appropriately.
Ensure that categorical variables are correctly processed.
Provide clear error messages if the model fitting fails.
Regression:
For regression, use statsmodels and ensure that a constant term is added to the predictor using sm.add_constant(X).
Seasonal Decomposition:
Ensure the period is set correctly when performing seasonal decomposition.
Verify the number of observations works for the decomposition.
Output:
Ensure the code is executable and as intended.
Also choose the correct type of model for the problem
Avoid adding data visualization code.
"""
dataset = dspy.InputField(desc="Available datasets loaded in the system, use this df,columns set df as copy of df")
goal = dspy.InputField(desc="The user defined goal for the analysis to be performed")
code = dspy.OutputField(desc ="The code that does the statistical analysis using statsmodel")
commentary = dspy.OutputField(desc="The comments about what analysis is being performed")它接收用户查询(目标)和数据集信息,输出代码和注释(关于代码功能的文本信息)。
上述提示大部分是我手动创建的,稍后我将在文章中展示 DSPy 生成的改进提示。
2、创建评估数据集
DSPy 优化的一个重要组成部分是拥有一组查询,你可以使用它们来构建训练和验证管道。
第一步是让 LLM 向你提出用于评估的代理问题。你需要告诉 LLM 代理做什么、它需要什么输入以及你希望代理收到什么样的查询。最好在代码中简化这一点,但使用 ChatGPT 界面很容易展示。
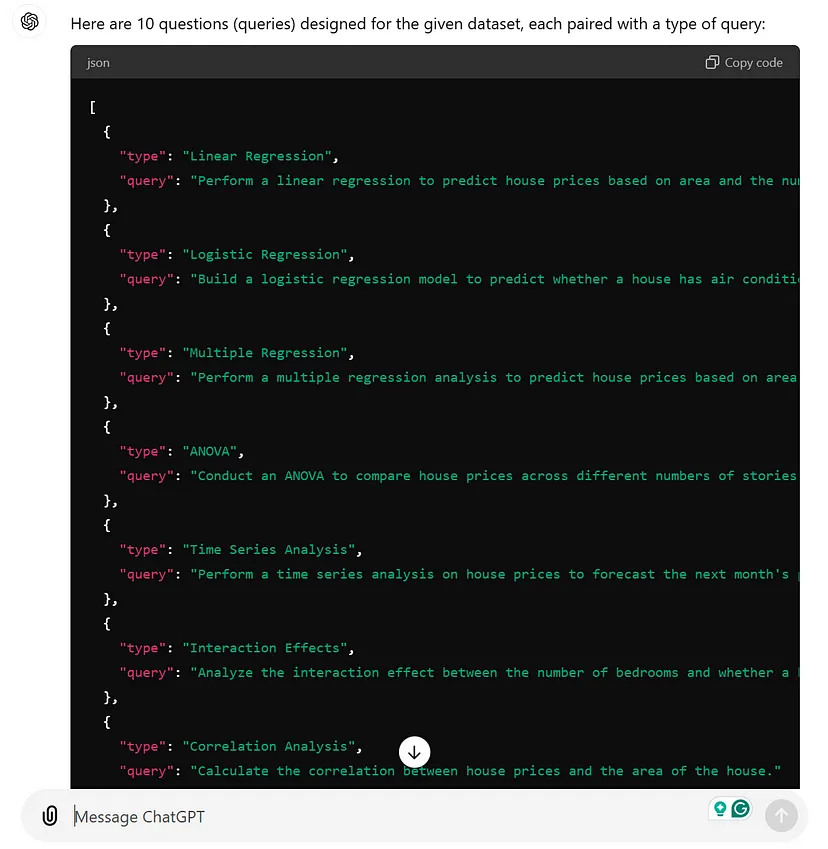
为了有效地评估你的 AI 系统,你的测试数据集应该包括用户可能问的大多数问题。由于代理使用 CSV 文件(这将与你的评估数据集不同),因此为各种 CSV 文件创建评估问题是个好主意。
如果你的 AI 代理是实时的并且具有聊天界面,那么跟踪它正确回答了哪些问题以及没有回答哪些问题会很有帮助。然后,你可以围绕这些查询构建评估流程。要扩展你的评估数据,你可以使用语言模型 (LLM) 来生成同一问题的不同变体。这有助于创建一组更广泛的评估测试用例。
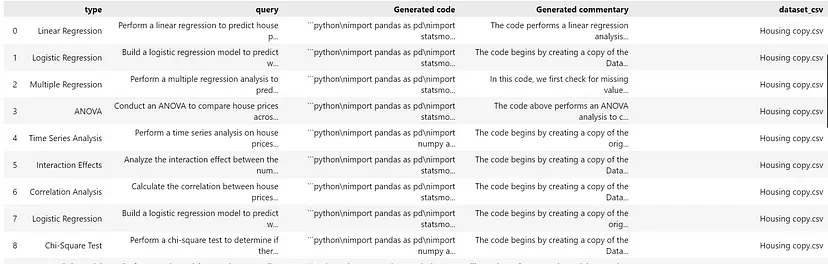
构建评估数据集的最后一步是添加正确或预期的响应列。你可能需要一个人参与才能获得正确或预期的答案。对于这个代理,我检查了生成的响应,修复了所有错误,并亲自检查了代码是否正确回答了查询;如果没有,我添加了正确的版本。
3、设计指标
我们如何判断代理的响应是否良好?要弄清楚这一点,我们需要一种方法来衡量其性能。你可以根据需要创建特定指标,也可以使用现有指标,如余弦相似度(可以测量生成的响应和预期响应之间的语义相似性)。对于统计分析代理,指标应该能够执行以下操作:
- 检查代码是否运行
- 检查代码是否按照用户意图执行
第一个很容易测量,只需运行代理生成的代码即可。第二个比较棘手,因为用户查询可能不明确。无论我们如何测量第二部分,它都会不完美或有偏差。在这种情况下,我们应该寻找大多数用户的喜好或他们如何编写查询。
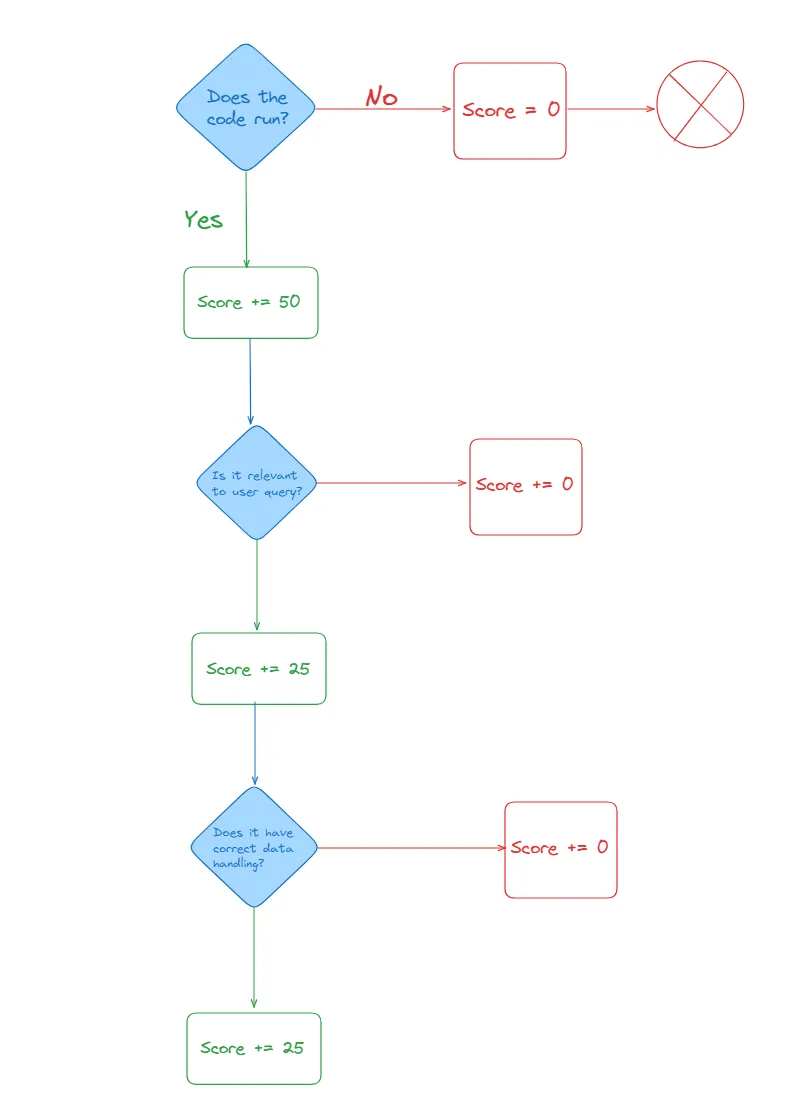
此指标的分数可以是 0、50、75 或 100。使用语言模型 (LLM) 测试“数据处理”和“相关性”分数,以查看它是否正确检查了响应中的数据类型。这包括确保正确完成任何必要的数据类型转换。
通常 DSPy 示例的指标小于 1,因此在指标的最后将分数除以 100。
4、提示优化如何工作?
在本节中,我将解释提示优化背后的高级思想。
如需更多资源,可以查看 Michael Ryan(他是 DSPy 的研究生之一)的作品。
首先,将评估训练数据(包括查询和其他输入)输入到学生语言模型 (LM) 程序中。学生会获得你设置的起始提示和说明。模型会处理查询,并使用指标对其性能进行评分。根据学生的表现,教师/讲师 LM 程序会为学生创建新的说明。然后,学生使用这些更新的说明,这个过程会重复几次。最后,您会得到一组根据你的指标表现最佳的说明。
只要指标和训练数据能够准确地建模和表示你希望 LM 程序解决的问题,这将比简单的反复试验或随机猜测产生更好的提示。
这是对优化算法工作原理的广泛概述。以下是 DSPy 中可用的关键算法的细分:
- LabeledFewShot:此方法从标记的输入和输出数据创建一些示例(称为演示)。您只需指定所需的示例数量 (k),它就会从训练集中随机挑选 k 个示例。
- BootstrapFewShot:它使用“教师”模块(可以是您的程序)为程序的每个阶段创建完整的演示,以及来自训练集的标记示例。您可以控制从训练集中挑选多少个演示(max_labeled_demos)以及教师应创建多少个新演示(max_bootstrapped_demos)。只有满足特定性能指标的演示才会包含在最终集合中。高级用户还可以使用不同的 DSPy 程序作为教师来完成更复杂的任务。
- BootstrapFewShotWithRandomSearch:此方法多次运行 BootstrapFewShot,尝试不同的随机演示组合并根据优化选择最佳程序。它使用与 BootstrapFewShot 相同的设置,并带有一个额外的参数(num_candidate_programs),该参数定义将评估多少个随机程序。
- BootstrapFewShotWithOptuna:此版本的 BootstrapFewShot 使用 Optuna 优化工具来测试不同的演示集,运行试验以最大化性能指标并选择最佳的演示集。
- KNNFewShot:此方法使用 k-Nearest Neighbors 算法来查找给定输入的最接近匹配的训练示例。然后将这些类似的示例用作 BootstrapFewShot 优化的训练集。
- COPRO:此方法使用称为坐标上升(类似于爬山)的优化技术为流程的每个步骤创建和改进指令。它根据度量函数和训练集不断调整指令。参数“深度”控制优化器将运行多少轮改进。
- MIPRO/MIPROv2:此方法在每个步骤生成指令和示例。使用已有的数据和示例是明智的。它使用贝叶斯优化来有效地搜索程序不同部分中的可能指令和示例。MIPROv2 更高效,因为它执行速度更快,成本更低。
5、结束语
本节将显示“statistical_analytics_agent”的得分和优化指令的结果。用于此的优化器是 BootstrapFewShotWithRandomSearch 和 COPRO。第一个会找到优化的少样本示例以添加到提示中。COPRO 会找到效果最佳的优化指令字符串。用于教学的 LM 是 gpt-4o-mini。
之所以选择这些而不是 MIPRO,是因为有人建议你应该有 100-200 个训练集来使用 MIPRO,而在这个例子中,我只使用了 30-40 个示例训练集。
未编译版本在指标上的表现为 66.7。以下是由于 BootstrapFewShotWithRandomSearch (BFSRS) 带来的性能改进:
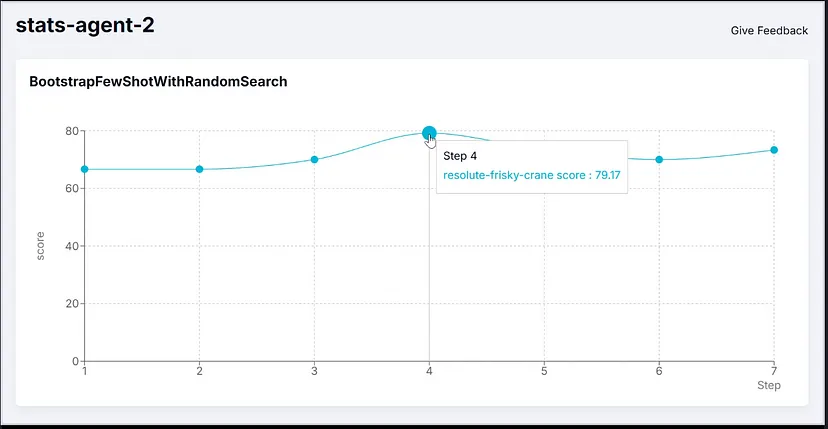
BFSRS 优化使训练数据增加了 20%。这些是它为提示生成的几个镜头示例:


现在让我们分析 COPRO,它将使用优化的指令字符串,而不是示例。
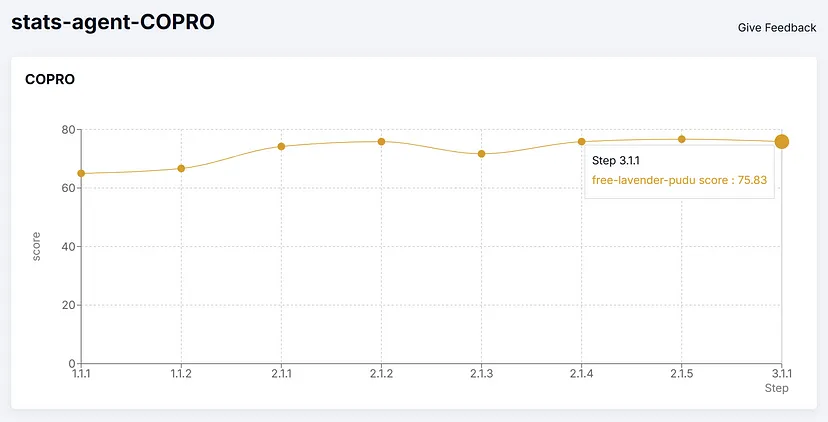
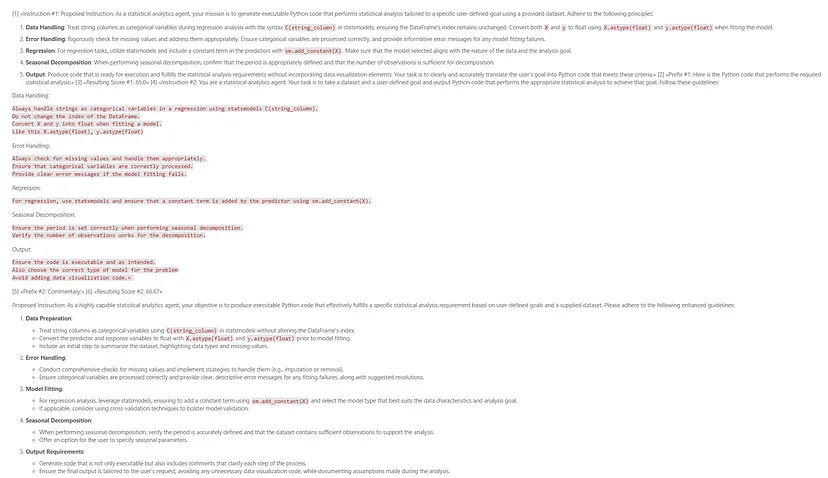

原文链接:How to improve AI agent(s) using DSPy
汇智网翻译整理,转载请标明出处
