用Vertex AI RAG索引代码库
本文演示了如何利用Vertex AI RAG引擎来索引公共GitHub存储库中的代码,并创建一个对话界面,使用强大的生成模型如Gemini来探索其内容。

简单的事实是,软件开发涉及导航大型复杂的代码库。理解功能、查找特定实现或让新成员入职可能会耗费大量时间。大型语言模型(LLMs)在理解和生成文本方面具有令人难以置信的能力,但它们如何提供针对你独特、私有或不断变化的代码的具体见解呢?
这就是检索增强生成或RAG发挥作用的地方。RAG是一种强大的AI技术,通过将其与外部知识源结合,增强了LLMs的准确性和可靠性。它不仅仅依赖于其内部训练数据,而是首先从您指定的文档(如代码文件)中检索相关信息,然后使用这些检索到的上下文与其内部知识一起生成更明智和具体的答案。可以把它想象成给AI一本“开放的书”——你的代码库——让它在回答问题之前查阅。
这种方法对于理解复杂的信息来源特别有效,尤其是软件代码库。如果你能简单地用自然语言询问代码并根据源文件直接获得答案,那会怎么样?
本文演示了如何利用Vertex AI RAG引擎来索引公共GitHub存储库中的代码,并创建一个对话界面,使用强大的生成模型如Gemini来探索其内容。我们将逐步介绍设置此代码感知查询系统的步骤。
你可以在GitHub上的这个 Jupyter Notebook中找到本文使用的完整代码和分步说明。
1、挑战:大规模理解代码
随着代码库的增长,搜索特定信息变得越来越困难。传统的关键词搜索往往无法捕捉代码背后的语义意义或上下文。开发人员可能需要花费数小时手动跟踪依赖关系或解码逻辑,这会减缓开发周期并增加新成员的入门门槛。
2、解决方案:为代码而设的RAG
RAG弥合了大型语言模型庞大知识库与特定、私有或实时数据源之间的鸿沟。在代码背景下,RAG允许生成模型访问并“读取”特定代码库的内容在生成答案之前。这使模型的回答基于实际源代码,与仅依赖模型的通用训练数据相比,这会导致更准确、相关且上下文感知的答案。
Vertex AI RAG引擎提供了一个托管平台来简化这一过程,处理数据摄取、向量化、索引和检索的复杂性。
3、构建代码感知查询系统的工作流程
为你的代码库设置RAG系统涉及几个关键步骤:
3.1 准备数据
- 克隆存储库: 首先,将目标公共GitHub存储库克隆到您的本地环境。
- 筛选和上传: 使用预定义的扩展名和文件名列表识别相关文件(源代码、配置、文档如.py、.java、.md、Dockerfile)。遍历克隆的存储库,可选地筛选超出大小限制的文件,并将选定的文件上传到指定的Google Cloud Storage存储桶,保留目录结构。这些上传的文件是GCS对象(blob),并作为暂存区域。
3.2 创建RAG语料库
主要组件是Vertex AI RAG语料库,这是一个用于您的文档的托管容器。创建时,指定显示名称和用于向量化代码以进行语义搜索的Vertex AI文本嵌入模型(例如text-embedding-005)。通过定义其配置来创建语料库:
from vertexai import rag
EMBEDDING_MODEL = "publishers/google/models/text-embedding-005"
GITHUB_URL = "https://github.com/google/example-repo"
rag_corpus = rag.create_corpus(
display_name="my-codebase-corpus",
description=f"Codebase files from {GITHUB_URL}",
backend_config=rag.RagVectorDbConfig(
rag_embedding_model_config=rag.RagEmbeddingModelConfig(
vertex_prediction_endpoint=rag.VertexPredictionEndpoint(
publisher_model=EMBEDDING_MODEL
)
)
)
)
3.3 将文件导入语料库
使用rag.import_files异步启动从GCS将已准备好的代码文件导入RAG语料库的过程。这里的关键步骤是分块:配置如何将文件分割成较小的部分(例如500个标记)并带有重叠(例如100个标记),以适应模型的上下文窗口并提高检索的相关性。开始导入作业时进行分块:
GCS_IMPORT_URI = "gs://your-bucket-name/rag-code-data/"
import_response = rag.import_files(
corpus_name=rag_corpus.name,
paths=[GCS_IMPORT_URI],
transformation_config=rag.TransformationConfig(
chunking_config=rag.ChunkingConfig(
chunk_size=500,
chunk_overlap=100
)
),
)
3.4 设置检索工具
为Gemini模型定义一个Tool。该工具使用Retrieval,并配置一个 VertexRagStore指向您的RAG语料库。您可以指定检索参数,如片段数量(similarity_top_k)和相似度阈值。为模型配置工具:
from google.genai.types import Tool, Retrieval, VertexRagStore
rag_retrieval_tool = Tool(
retrieval=Retrieval(
vertex_rag_store=VertexRagStore(
rag_corpora=[rag_corpus.name], # 引用创建的语料库
similarity_top_k=10, # 检索前10个片段
vector_distance_threshold=0.5, # 可选的相似度过滤器
)
)
)
3.5 查询代码库
现在,通过SDK客户端使用配置好的Gemini模型,传递您的自然语言查询和rag_retrieval_tool。模型利用该工具从您的语料库中提取相关的代码片段并综合出一个知情的答案。使用RAG工具提问:
from google.genai.types import GenerateContentConfig
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="What is the primary purpose or main functionality of this codebase?",
config=GenerateContentConfig(tools=[rag_retrieval_tool]),
)
4、测试你的代码
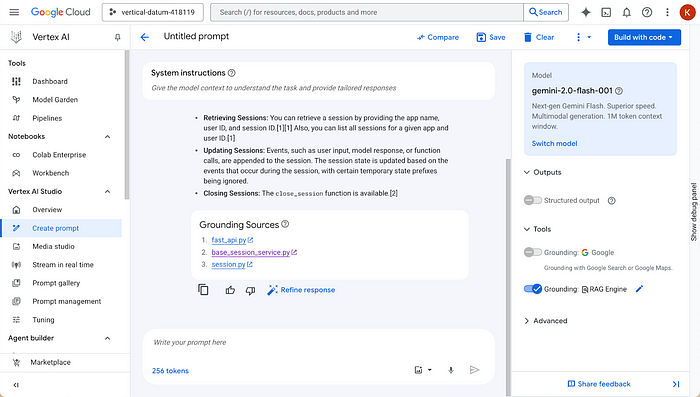
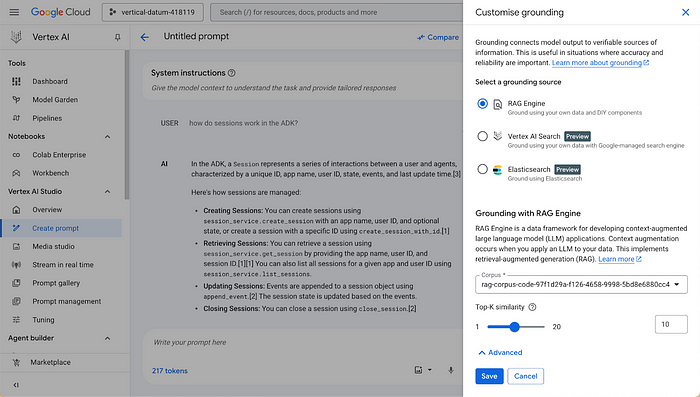
设置完成后,你可以通过Vertex AI Studio在Google Cloud控制台中轻松交互式测试您的RAG语料库。选择接地,然后选择RAG引擎作为接地源,最后选择你的RAG语料库。现在,你能够看到检索和生成过程的实际操作!
5、结束语
Vertex AI RAG引擎改变了开发人员与代码互动的方式。通过索引存储库并启用基于实际源文件的自然语言查询,它显著加速了代码理解,简化了入职流程,并赋予开发人员更高效地查找信息的能力。这种方法超越了简单的关键词搜索,提供了对复杂软件系统的更深层次、上下文感知的理解。
原文链接:Build a RAG system for your codebase in 5 easy steps
汇智网翻译整理,转载请标明出处
