LayoutLM文档提取指南
LayoutLM 是一种革命性的模型,结合了文本识别和布局理解的强大功能,可以准确地从结构化文档中提取实体。

在当今数据驱动的世界中,手动从结构化文档中提取有价值的信息可能是一项艰巨的任务。然而,得益于自然语言处理 (NLP) 和计算机视觉领域的突破性进步,我们现在拥有了强大的工具。
LayoutLM 就是这样一种工具,它是一种革命性的模型,结合了文本识别和布局理解的强大功能,可以准确地从结构化文档中提取实体。在本文中,我们将深入研究使用 LayoutLM 进行实体提取的迷人过程,并探索如何利用其功能从文档中解锁有价值的见解。
1、了解 LayoutLM
LayoutLM 建立在流行的 Transformers 架构之上,彻底改变了文档理解领域。它结合了光学字符识别 (OCR) 和视觉布局分析的优势,可以理解各种类型文档的结构和内容。凭借其理解文本和视觉元素的能力,LayoutLM 已成为高效提取结构化信息的首选模型。
有关 LayoutLM 架构的更多信息,请参阅HF说明文档。
本文将重点介绍 Hugging Face 实现命名实体识别(也称为 Token 分类)的 LayoutLM 模型。Hugging Face 文档中的实现请参考我的Colab笔记本 。
2、准备数据
在深入实体提取过程之前,必须准备好一个数据集。首先收集一组与您的目标域相符的多样化结构化文档。这些文档可能包括发票、简历、法律合同或你希望从中提取实体的任何其他文档类型。确保文档正确标记,并带有标注以指示感兴趣的实体。高质量、准确标记的数据对于有效训练 LayoutLM 至关重要。
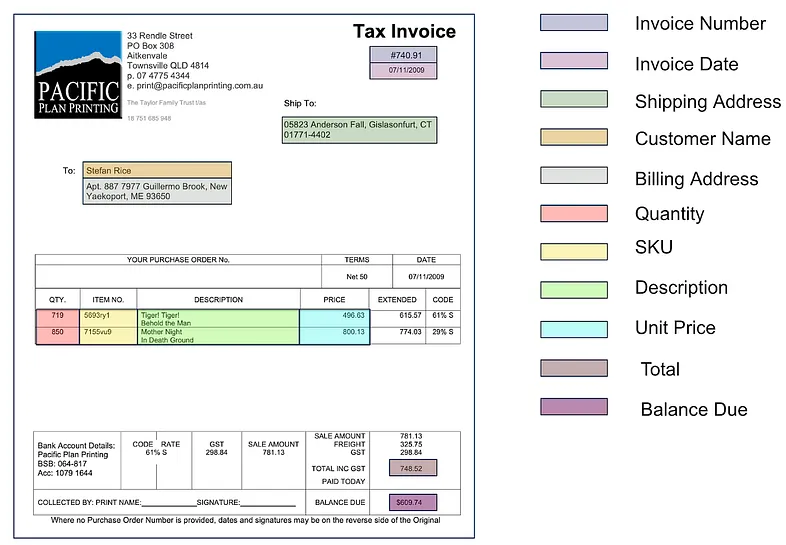
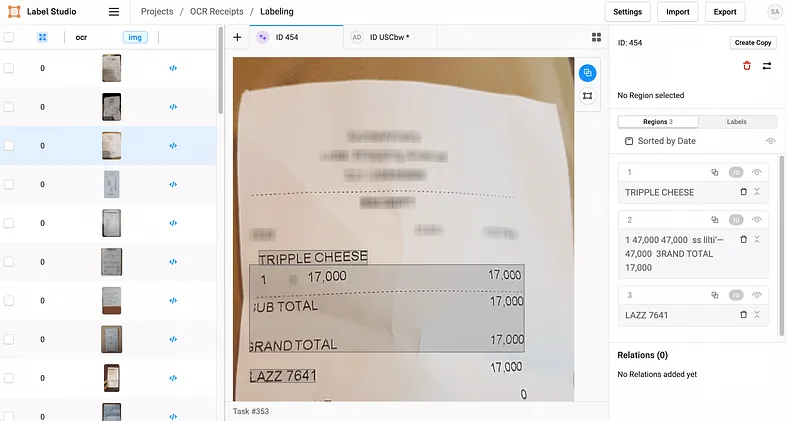
例如,让我们考虑一个发票数据集。每张发票都标有“供应商名称”、“发票编号”和“总金额”等实体。Label-Studio 是一个出色的工具,你可以使用光学字符识别 (OCR) 标签模板。
3、微调 LayoutLM
准备好数据集后,下一步就是在特定数据集上微调预先训练的 LayoutLM 模型。微调允许模型学习与你的文档相关的特定模式和实体,使其更准确地提取信息。为此,请按照所引用的笔记本中概述的步骤进行操作。它涉及加载预先训练的 LayoutLM 模型,调整架构和参数,并在标注的数据集上对其进行训练。
微调可能需要大量计算资源,因此请确保你可以使用 GPU 或其他加速器进行高效训练。利用 Hugging Face Transformers 库加载预先训练的 LayoutLM 模型并使用标记的数据集对其进行微调。例如,以下代码片段演示了微调过程:
# Importing necessary libraries
from transformers import LayoutLMForTokenClassification, LayoutLMTokenizerFast
from transformers import TrainingArguments, Trainer
# Loading the pre-trained LayoutLM model and tokenizer
model = LayoutLMForTokenClassification.from_pretrained("microsoft/layoutlm-base-uncased")
tokenizer = LayoutLMTokenizerFast.from_pretrained("microsoft/layoutlm-base-uncased")
# Setting up the training arguments for the Trainer
training_args = TrainingArguments(
output_dir="./results", # Directory to save the training results
num_train_epochs=3, # Number of training epochs
per_device_train_batch_size=8, # Batch size for training
per_device_eval_batch_size=16, # Batch size for evaluation
warmup_steps=500, # Number of warmup steps
weight_decay=0.01, # Weight decay coefficient
logging_dir="./logs", # Directory to save logs
)
# Creating the Trainer object
trainer = Trainer(
model=model, # The LayoutLM model
args=training_args, # Training arguments
train_dataset=your_train_dataset, # Training dataset
eval_dataset=your_eval_dataset, # Evaluation dataset
data_collator=data_collator, # Data collator
)
# Training the model
trainer.train()4、文档处理
有了经过微调的 LayoutLM 模型,现在是时候将其投入使用并从结构化文档中提取实体了。该模型的独特优势在于它能够分析文本和视觉元素。它了解文档的布局,从而能够准确识别关键实体,例如姓名、地址、日期等。你所遵循的笔记本演示了如何将图像嵌入到 LayoutLM 中,从而进一步增强模型的性能。此步骤涉及将文档输入到他训练模型并从模型的输出中提取预测实体。
例如,考虑以下代码片段,该代码片段处理文档并使用经过训练的模型提取实体:
import torch
# Assuming `document` contains the content of a structured document
# Tokenize the document and convert it to tensors
inputs = tokenizer(document, return_tensors="pt", padding="max_length", truncation=True)
# Pass the inputs through the model to get the predicted labels
outputs = model(**inputs)
# Retrieve the predicted labels by taking the argmax along the token dimension
predicted_labels = torch.argmax(outputs.logits, dim=2)[0]
# Convert the predicted label IDs to token representations
predicted_entities = [tokenizer.convert_ids_to_tokens(token_id) for token_id in predicted_labels]5、后处理和验证
实体提取并不总是一步到位的过程。应用后处理技术来细化提取的实体并确保其正确性至关重要。后处理可能涉及过滤掉不相关或嘈杂的实体、解决不一致或歧义,以及根据基本事实或外部知识库验证提取的信息。通过利用其他 NLP 工具和技术(例如命名实体识别 (NER) 或实体链接),你可以进一步提高提取信息的准确性和可靠性。

6、采用面向对象的方法
虽然提供的笔记本使用 LayoutLM 提供了实体提取过程的简洁实现,但您可能会发现使用面向对象的方法构造代码会很有帮助。这种方法促进了模块化、代码可重用性和可维护性,使你的项目更容易扩展并与他人协作。通过将代码分解为单独的 Python 文件,每个文件由用于特定功能的单独类组成,你可以创建一个组织良好且可扩展的代码库。
以下是将代码分解为单独的 Python 文件的建议:
- data_processing.py:
此文件可以包含一个负责加载和预处理数据集的类。它包括用于读取结构化文档、应用任何必要的转换以及将数据拆分为训练和评估集的函数。
- pytorch_dataset.py:
在此文件中,你可以定义一个实现 PyTorch Dataset 接口的类。此类应处理数据的标记化、编码和批处理,使其准备好训练 LayoutLM 模型。
- model_training.py:
在这里,你可以定义一个负责训练 LayoutLM 模型的类。它包括用于在数据集上微调预训练模型、指定训练参数和监控训练过程的函数。为了方便起见,此类可以利用 PyTorch Lightning 库或其他训练框架。
- document_processing.py:
此文件可以包含一个封装文档处理功能的类。它包括加载微调的 LayoutLM 模型、标记文档、执行推理和提取预测实体的函数。
- main.py:
主 Python 文件用作代码的入口点。它从上述文件中导入类和函数,并协调整个实体提取过程。它处理对象的实例化、函数调用以及任何必要的后处理或验证步骤。
通过以这种方式组织代码库,您将实现清晰的关注点分离,使您能够修改或扩展特定组件而不影响整个管道。此外,面向对象的结构允许轻松集成其他功能或模型,从而方便尝试不同的技术或提高整体性能。
请记住遵守干净编码的原则,例如编写模块化函数、利用适当的设计模式和提供全面的文档。这些做法有助于提高代码的可维护性,并促进团队成员或未来贡献者之间的协作。
7、结束语
成功从结构化文档中提取实体后,许多可能性就会打开。你现在可以将提取的信息应用于各种下游任务,例如信息检索、数据分析甚至自动决策。例如,你可以使用提取的实体来填充结构化数据库、执行趋势分析或支持合规流程。通过利用 LayoutLM 的强大功能,你可以根据从文档中提取的结构化信息获得有价值的见解、提高运营效率并做出明智的业务决策
在当今数据驱动的世界中,从结构化文档中提取实体是一项具有挑战性但必不可少的任务。通过遵循本文概述的分步过程并利用提供的Colab笔记本,你可以利用 LayoutLM 的强大功能从结构化文档中提取有价值的信息。通过精心的数据准备、微调、文档处理和后处理技术,你可以提高提取实体的准确性和可靠性。通过将 LayoutLM 纳入你的文档处理流程,增强你的数据分析能力、简化你的工作流程并释放新的机会。
原文链接:LayoutLM: Extracting Entities from Structured Documents, a Practical Guide
汇智网翻译整理,转载请标明出处
