LiteLLM:统一的大模型访问层
LiteLLM通过一致的 API 解决了更换各种 LLM 提供商的挑战,更灵活、更易于维护的 genAI 应用程序。
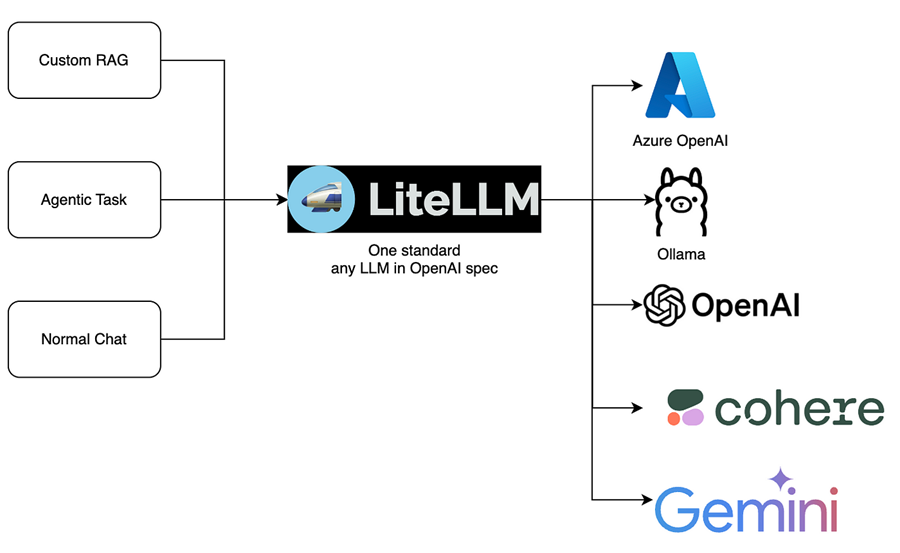
在这篇文章中,你将了解为什么应该考虑在下一个 genAI 构建中利用 LiteLLM 代理层。我将探讨 LiteLLM 如何使更改模型变得简单,即使在 Amazon Bedrock 中也是如此,无需更改任何代码。我还将描述如何使用 LiteLLM 通过前置本地或云模型(如 Amazon Bedrock)来支持你最喜欢的基于桌面的 genAI 应用程序。
1、模型锁定的挑战
我喜欢与客户谈论 AIML,尤其是当我与工程师一起开展项目时。过去几年中,我与之交谈过的每个工程团队都有一个迫切的问题:“我应该使用什么模型?”
这不会让你感到惊讶,但答案是“视情况而定!”似乎每天都会发布新模型,每个模型都有优点和缺点。
虽然我经常在 Amazon Bedrock 中求助于 Claude 或 Llama 来完成大部分工作,但我也想看看其他模型的表现如何。虽然 Claude 提供了出色的结果,但较小的模型通常可以更便宜或更快地提供可接受的结果。
许多团队花费了大量前期时间来找出一种可以适用于所有未来用例的模型。许多领导者和工程师也成为新发布的炫酷模型的牺牲品,并感到有必要在前进之前尝试每一次新的迭代。这是团队最常见的阻碍;这是分析瘫痪的最新形式。
我的建议始终如一:尝试一些大牌,找到一个能提供可接受结果的,然后继续前进。选择不是单向的;模型可以重新评估并在以后更换。然而,直到最近,在无缝更换方面仍存在一些挑战。我确实花了一些时间编写垫片来转换参数、更改用户提示以及将系统/助手/用户条目调整为提示——所有这些都会随着模型或 API 的更新而崩溃。
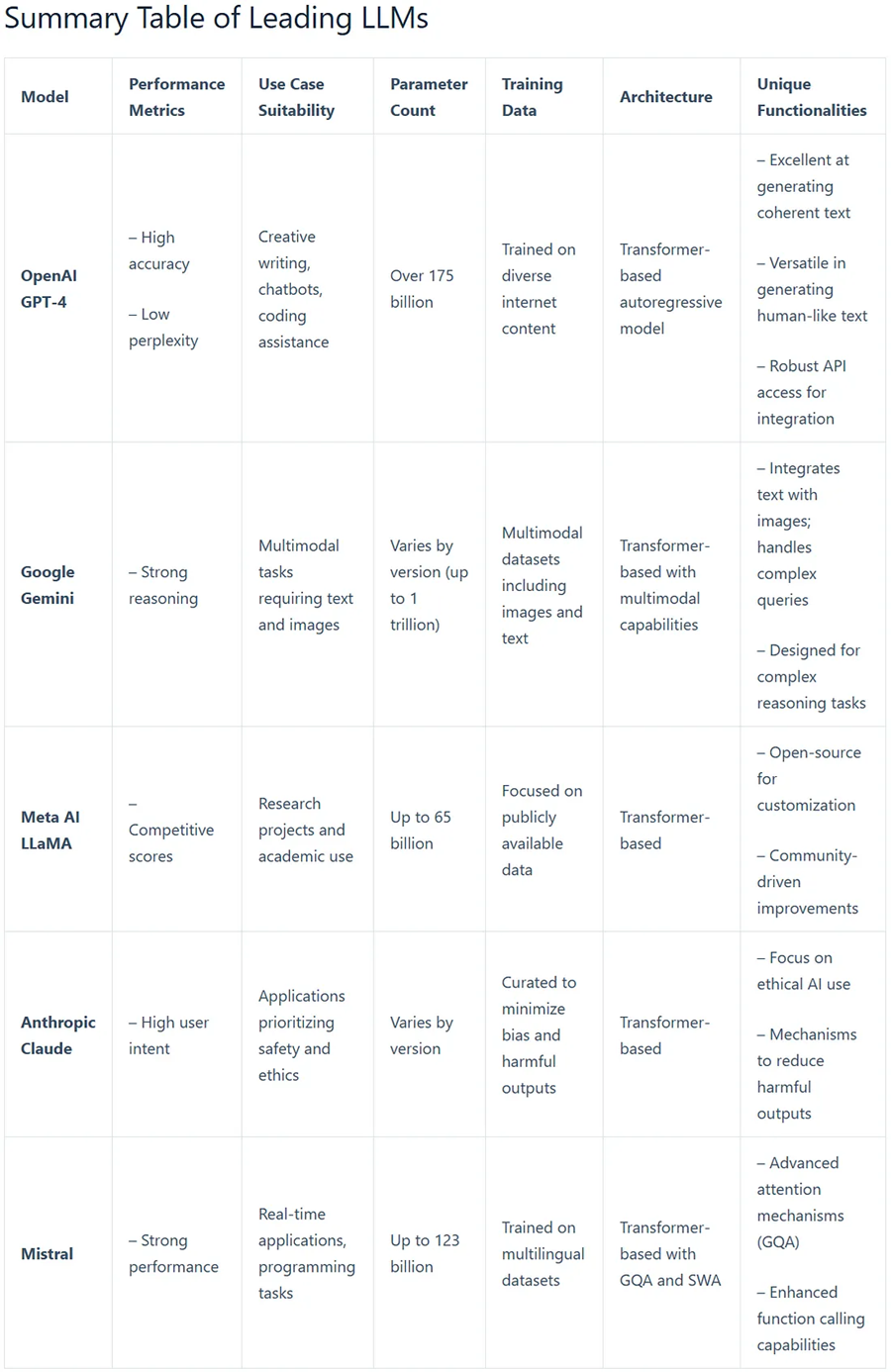
这个综合表格清晰地概述了领先的 LLM,总结了它们的性能指标、对各种应用程序的适用性、参数计数、训练数据源、架构和独特功能。对于希望有效比较这些模型的用户来说,它提供了宝贵的参考。
2、进入 LiteLLM
几个月前,我遇到了一个名为 LiteLLM 的项目。他们通过一致的 API 解决了更换各种 LLM 提供商的挑战。具体来说,它们在 OpenAI API 格式背后合并,并为你处理幕后的转换。这个抽象层使团队能够构建更灵活、更易于维护的 genAI 应用程序。他们可以花时间创建应用程序和设计提示,而不是专注于提供商或特定于模型的代码。
与更传统的软件开发工作一样,LiteLLM代理层或中间件可以帮助团队在不了解其使用细节的情况下使用后端资源。想象一下将 REST API 或其他微服务放在数据库前面;你不希望消费者单独访问你的数据库,因此你可以改用这个中间件。
这种类型的代理层对工程团队非常有益,而且开销相对较小。虽然代理确实意味着需要维护更多内容,并且请求的整体处理会稍微延迟,但 LiteLLM 允许很大的灵活性和扩展性。
我们已经介绍了团队可以轻松切换模型(甚至允许最终用户动态切换模型!)。那么,这种方法还有哪些其他好处呢?
- 缓存
我听到了很多关于快速(和响应)缓存的请求。缓存提示和响应不仅可以加快你的 genAI 应用程序的速度,还可以通过绕过 LLM 来节省资金。虽然大多数团队都想要这种功能,但这往往是以自己实现它为代价的。LiteLLM 内置了一些缓存功能,而拥有集中式代理层可以让想要创建自己的缓存技术的团队更轻松地实现这一点。
- 后备模型和重试
LiteLLM 具有内置支持,可在发生故障时指定后备模型、自动重试和一些负载平衡,方法是能够在配置中定义具有不同端点的相同模型
- 成本管理和日志记录
该框架还包括对成本管理、令牌限制、成本跟踪和底层 LLM 使用情况的集中日志记录的内置支持。
- SDK 或独立代理
该项目有两种风格。你可以将 SDK 集成到你的项目中以获得更多的扩展和灵活性,或者启动一个可以开箱即用的独立代理实例。
让我们继续运行LiteLLM代理的独立实例。
3、LiteLLM安装与配置
首先在你的 AWS 环境中创建一个新的 EC2 实例
- 确保授予它 Amazon Bedrock的权限 — 我们将使用 EC2 IAM 角色而不是 IAM 密钥/令牌
- 打开 SG/NACL 以允许访问端口 4000(LiteLLM 的默认端口)
- 我建议使用 Linux 发行版,我将使用 Ubuntu
- 确保它已安装 Python 3.8–3.12
3.1 环境配置
我们将创建一个新的 VENV 来运行代理。如果你想在机器上将其作为唯一服务运行,这就是你设置环境的方式。如果你想在项目中使用 SDK,你将为该项目创建一个 VENV 并将 LiteLLM 作为依赖项包含在内。
mkdir litellm-proxy
cd litellm-proxy
python -m venv venv
source venv/bin/activate
pip install litellm
touch config.yaml3.2 LiteLLM代理配置
要运行LiteLLM代理(proxy),我们将创建一个配置文件来定义服务的运行方式。首先是配置,然后是解释
model_list:
- model_name: bedrock-claude
litellm_params:
model: us.anthropic.claude-3-5-sonnet-20241022-v2:0
aws_region_name: us-east-1
- model_name: gpt-3.5-turbo
litellm_params:
model: us.anthropic.claude-3-5-sonnet-20241022-v2:0
aws_region_name: us-east-1
litellm_settings:
set_verbose: True
drop_params: true
modify_params: true配置分为 2 个部分:模型列表和 LiteLLM 设置。
模型列表:
- model_name — 你希望如何引用要使用的模型。在大多数情况下,它可以是你想要使用的任何内容。但是,如果你尝试覆盖允许自定义 OpenAI 端点的桌面应用程序,则必须使用 OpenAI 模型名称,例如“gpt4o”。这不会影响正在使用的内容;它只是一个标签。
- model — 这是你要使用的模型的实际名称。在此示例中,我想在 Amazon Bedrock 中使用 Claude3.5 Sonnet 模型(实际上是跨区域推理)。
- aws_region_name — 我通常在“us-east-1”中为我的 POC 和小型项目工作。使用你设置的任何区域。
我在这里定义了两个模型,有两个名称,但它们都指向 Amazon Bedrock Claude3.5 Sonnet。我们将在下面的一些示例中看到原因。
LiteLLM:
- set_verbose — 我想查看 Bedrock 中的每个请求、响应和错误,因为我在使用此代理时正在调试一些代码。
- drop_params — 在模型之间切换时,它们并不总是具有相同的参数,例如“存在惩罚”或“topK”。LiteLLM 将确保在转换调用时删除任何参数。
- modify_params — Llama 和 Claude 对“用户”角色在提示中出现的位置非常挑剔。LiteLLM 将清理您的消息并确保已为它们分配了正确的角色。
这些绝不是详尽无遗的;我建议你仔细阅读LiteLLM的文档,看看还有哪些其他旋钮适合您的特定用例。
4、运行LiteLLM代理
回到终端,是时候运行代理了。默认情况下,它绑定到 0.0.0.0 并使用端口 4000,因此可以立即进行外部访问:
litellm --config ./liteLLM.config.yaml 让我们确保它正常工作:
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "bedrock-claude",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}
'5、在代码中使用LiteLLM代理
现在,让我们看几个如何在代码中使用它的不同示例。
首先,我们将了解如何使用它,就好像它只是一个 OpenAI 调用一样。这将调用我们的 LLM 代理并将模型名称传递为“gpt-3.5-turbo”。从我们的配置文件中,我们定义了一个模型名称“gpt-3.5-turbo”,但将其代理到 Claude。
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
]
)
print(response)接下来,如何在 Langchain 中将其用作 OpenAI 端点:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
import os
os.environ["OPENAI_API_KEY"] = "anything"
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-3.5-turbo",
temperature=0.1
)最后,在最初仅支持 OpenAI 的 Microsoft AutoGen 框架中:
import autogen
critic = autogen.AssistantAgent(
name="Critic",
description="Double check plan, claims, and blog post from other agents and provide feedback.",
system_message="""Critic. Double check plan, claims, nd blog post from other agents and provide feedback.
If you have no feedback that needs to be considered, and the work seems finished, give Admin several attempts to weigh in.
However, if Admin has repeatedly said they have nothing to add, and the work is finished,
respond with one word 'terminate' to end the conversation.
""",
llm_config={
"config_list": [
{
"model": "gpt-3.5-turbo", # Loaded with LiteLLM command
"api_key": "NotRequired", # Not needed
"base_url": "http://0.0.0.0:4000", # Your LiteLLM URL
}
],
"cache_seed": None, # Turns off caching, useful for testing different models
"max_retries": 100, # Number of retries for rate limit errors
},
default_auto_reply = "Nothing to add",
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
is_termination_msg=lambda msg: "terminate" in msg["content"].lower(),
)6、在应用中使用LiteLLM代理
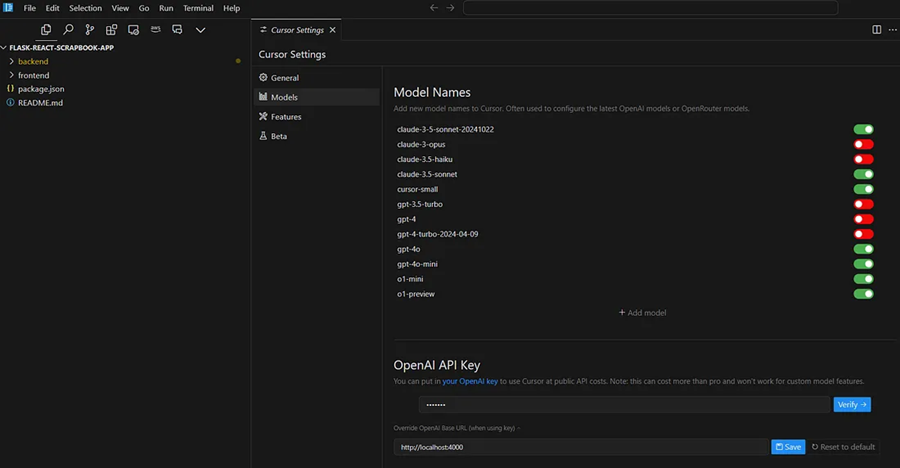
在桌面应用程序中如何使用LiteLLM代理呢?让我们看看 Cursor IDE示例。
4、结束语
我们已经了解了如何利用 LiteLLM 代理将我们的应用程序与底层 LLM 分离,以及在我们的项目中使用代理层的整体好处。
从用户的角度来看,我们还了解了如何利用 LiteLLM 代理在我们自己的软件上交换模型。如果你可以访问 Amazon Bedrock 或正在运行本地 LLM,这会很方便。
希望这有助于快速启动有关如何将此软件与 Amazon Bedrock 结合使用的想法,以加速你的软件开发和你自己对 genAI 应用程序的实验。
原文链接:Building Model-Agnostic GenAI Applications
汇智网翻译整理,转载请标明出处
