Llama 3.2视觉模型OCR能力
传统的 OCR 工具在文本与视觉元素同时存在时,其性能会很差。但随着 Llama 3.2 视觉模型的发布,只需传递图像并提取文本或对图像提出问题即可。

传统的 OCR 工具在处理图像中的简单文本时效果很好,但当文本与视觉元素同时存在时,其性能会很差。因此,为了提高准确性,我们可以使用对象检测模型来识别/隔离图像中的文本区域,然后将该文本呈现给 OCR 工具。此外,您还可以添加一层 LLM,以更精细的格式呈现 OCR 工具的文本输出。因此整个流程看起来会像这样

但随着 Llama 3.2 视觉模型的发布,只需传递图像并提取文本或对图像提出问题,就可以简化流程。
Llama 3.2 Vision模型是一个 90 亿参数模型,它在大多数 OCR 任务中表现良好。我使用 Ollama 在 MacBook 上本地运行 Llama 3.2 视觉模型。要使用 Llama 3.3 视觉模型,需要 Ollama 0.40,现在可作为预发布版使用。
import ollama
image_path = '../atomichabbits.jpg' # Replace with your image path
base64_image = image_to_base64(image_path)
response = ollama.chat(
model="x/llama3.2-vision",
messages=[{
"role": "user",
"content": "The image is a book cover. Output should be in this format - <Name of the Book>: <Name of the Author>. Do not output anything else",
"images": [base64_image]
}],
)
# Extract cleaned text
cleaned_text = response['message']['content'].strip()
print(cleaned_text)传入的图像如下:

输出为:

我还尝试了另一张图像,这是一张来自餐厅的账单,结果相当不错。输入图像为:

输出如下:
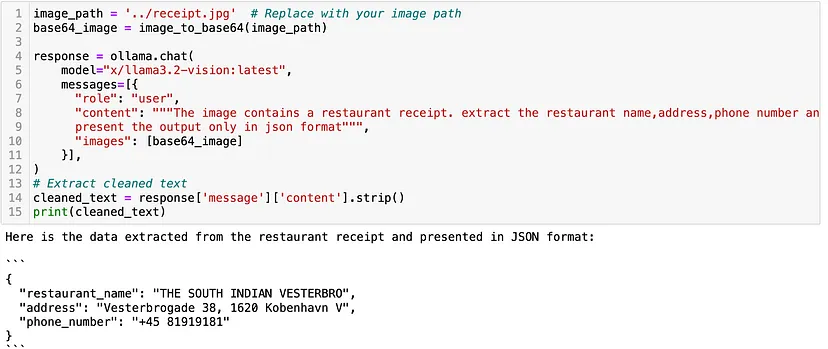
该模型甚至可以以结构化格式输出数据。这可以作为大量自动化的基础,我将在以后的帖子中介绍。
总之,视觉模型的进步可以帮助以简单的方式自动化大量计算机视觉任务。这个领域看起来很有前景。
原文链接:How to use Llama 3.2 vision model for better OCR
汇智网翻译整理,转载请标明出处
