Llama 3.3-70B简明教程
Meta 在其今年的最终版本中推出了 Llama3.3,这是一个 70B GenAI 模型,已经取得了一些出色的成果,并且已经在基准数据集上击败了一些 SOTA LLM。

Meta 在其今年的最终版本中推出了 Llama3.3,这是一个 70B GenAI 模型,已经取得了一些出色的成果,并且已经在基准数据集上击败了一些 SOTA LLM。正如 Meta 所承诺的那样,该模型是开源的,因此可以免费使用。
Llama3.3 是 Llama 家族中的第 3 个版本,早期的版本是 Llama3.1(8B、70B、405B)、Llama3.2(4 个变体,多模态)和现在的 Llama3.3(70B,仅限文本)。
1、模型架构
Llama 3.3 在自回归基础上运行,这意味着它通过根据前面的单词预测序列中的下一个单词来生成文本。这种方法可以生成连贯且与上下文相关的文本,使其适用于 NLP 中的各种任务。
Llama 3.3 的架构建立在针对性能进行了优化的转换器设计之上。
主要功能包括:
- 分组查询注意 (GQA):此机制允许模型同时处理多个查询,从而提高了模型在推理过程中的效率,这在处理较大的数据集和较长的序列时尤其有用。
- 具有 128K 词汇量的标记器:该模型使用可以处理大量词汇量的标记器,从而提高了其高效编码语言的能力。
2、训练方法
Llama 3.3 采用两种主要的训练方法来提高其性能:
- 监督微调 (SFT):此过程涉及在标注数据集上训练模型,其中使用人工反馈来指导学习过程。
- 带有人工反馈的强化学习 (RLHF):RLHF 通过在训练期间结合来自人工评估者的反馈来进一步完善模型的功能。
训练数据:
- 基于多种公开可用的在线资源。
- 上下文长度:可处理最多 128k 个 token 的输入。
- token 数量:在超过 15 万亿个 token 上进行训练。
- 知识截止:更新至 2023 年 12 月。
- 支持的语言:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
3、性能和指标
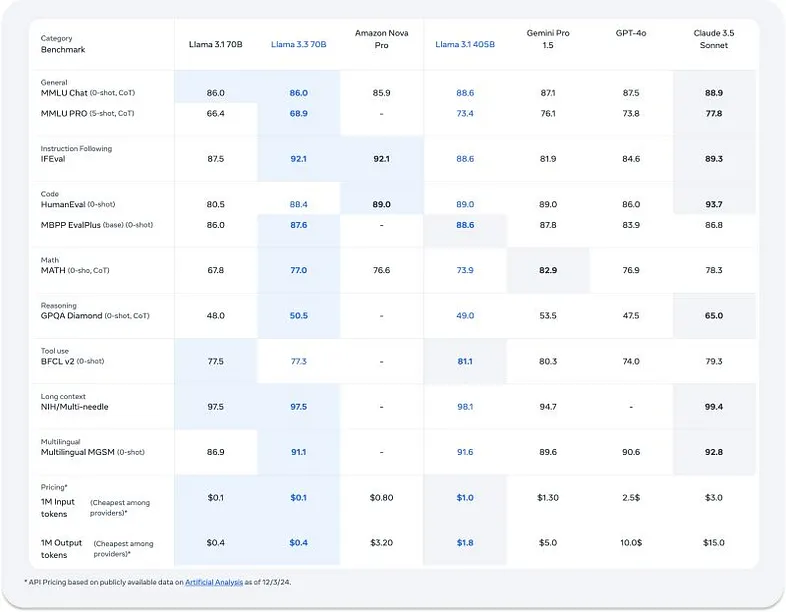
正如你可能在上表中观察到的那样,Llama3.3 在几乎所有基准测试中都优于 Llama3.1 70B,在某些指标(如 GPQA Diamond、MATH、IFEval 等)上击败了 Llama3.1 405B,即使成本仅为 Llama3.1 405B 的五分之一。
总体而言,指标看起来不错,考虑到模型大小,性能看起来很棒。
4、如何使用 Llama3.3?
该模型可在 HuggingFace 上使用。你首先需要访问受控存储库(通过填写简短的表格):
然后更新 transformers 库:
pip install --upgrade transformers接下来生成 HuggingFace READ 令牌(可免费创建),并按照以下代码操作:
import transformers
import torch
model_id = "meta-llama/Llama-3.3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])5、结束语
Llama 3.3 是 Llama 3.1 等大型模型的强大且经济高效的替代品405B,在关键基准测试中提供卓越性能,同时保持开源和可访问性。其优化的架构、先进的训练方法和对多种语言的支持使其成为各种 NLP 应用程序的理想选择。
无论你是在探索文本生成、推理任务还是编码挑战,Llama 3.3 都能以极低的成本提供强大的解决方案,使其成为开发人员和研究人员的宝贵工具。
原文链接:Meta Llama3.3 : 70B model alternate for Llama3.1 405B
汇智网翻译整理,转载请标明出处
