LLM微调综合指南
训练和微调模型是一项昂贵的苦差事,如果可以的话,你真的应该避免它,把省下的钱花在去阿鲁巴岛或任何你喜欢的度假胜地的旅行上。

在与 LLM 合作时,我们收到的最常见问题之一就是关于微调。每隔一个客户就会问他们是否应该对他们的模型进行额外的训练。
在大多数情况下,答案是否定的,他们不需要它。现代 LLM 无需微调就足以用于许多商业应用,例如帮助客户从花店订购鲜花的机器人。此外,他们没有数据来做到这一点,而且他们拥有的 20 个对话样本不算数(200 个也不算)。
训练和微调模型是一项昂贵的苦差事,如果可以的话,你真的应该避免它,把省下的钱花在去阿鲁巴岛或任何你喜欢的度假胜地的旅行上。
但是,有些情况下你确实需要它。例如,如果你希望 LLM 遵循非常特定的聊天格式或在非常特定的领域拥有知识,或者你想通过训练一个小模型来执行非常专业的任务来削减成本,而不是使用具有数千亿个参数的大型 LLM。这些都是通过微调创建定制模式的有效案例。
让我们来看看如何做到这一点。
1、何时进行微调
如上所述,只有在必要时才应进行微调。 尝试首先通过提示工程解决任务或构建 RAG 系统。 如果失败 — 考虑微调。
微调具有以下缺点:
- 需要花钱和时间
- 需要良好的训练数据,否则它将不起作用
- 即使做得正确,也会导致更频繁的幻觉,因为我们正在向最初并非为此量身定制的模型添加新行为。 如果你对模型进行定期更新,在某个时候几乎可以保证会出现这种情况,这被称为漂移,因此必须为此评估你的模式。
考虑以上所有因素后,如果仍然认为一般的 LLM 不够好 — 那么你需要进行微调。
2、数据
要进行微调,你将需要特定格式的数据,称为指令数据集。
2.1 在哪里获取数据
你可以使用许多开放数据集,例如,用于模型对齐的 Anthropic HH-RLHF 数据集、用于医疗保健的 MIMIC-III 和用于编码的 CodeSearchNet。有:
- 特定领域的数据集:医学、法律、编码等
- 特定任务的数据集可用于训练模型执行一项特定任务并制作 RPA
- 具有通用知识的通用数据集,通常由从互联网爬取的数据创建
- 对齐数据集:用于格式、样式和安全对齐
Hugging Face Hub 有很多可用于不同领域的指令数据集,我建议从那里开始。
但是既然你决定进行微调,可能已经拥有数据,因此你需要创建数据集。否则,你为什么要这样做?
如果你没有足够的样本,可以使用大型 LLM(如 ChatGTP)通过从你拥有的数据推断来生成合成数据。我稍后会谈到它。
2.2 数据要求
数据集大小取决于模型大小、任务复杂度和训练方法。OpenAI 等公司正在使用包含数百万个项目的庞大数据集,由于成本原因,这对于大多数公司来说是不可行的,因此实际上我们将有数千个样本。
对于沟通风格调整等简单变化,你不需要大量样本,几百个就足够了,对于特定领域的知识训练,你将需要几千到几十万个样本,具体取决于领域。一般来说,越多越好,最好至少有几千个样本。
数据质量意味着不低于数量,甚至可能高于数量。你需要确保数据正确反映了你想要建模以学习的行为,包括含义和格式。我想强调格式—你希望模型以用户能够理解的方式输出信息,无论是清晰度还是风格。除非你想创建一个 Eminem 双胞胎,否则在说唱诗句中说出真相的模型是没用的。
2.3 数据准备
数据准备是一个关键步骤,因为数据的质量直接影响模型的性能和准确性。准备数据涉及几个过程,以确保数据干净、相关且适合训练:
重复数据删除
重复的数据点会增加训练成本、引入不必要的噪音,并导致模型过度拟合或出现偏差。以下是常见的方法:
文本规范化:
- 将文本转换为小写。
- 删除特殊字符、多余的空格和标点符号以标准化内容。
基于哈希的重复数据删除:
- 生成规范化文本的哈希值。一种常用的技术是 MinHash,它捕获项目的本质或“语义指纹”,而不是其确切的文本。这样即使格式或小细节不同,也可以识别重复项。你可以使用 datasketch 等库来执行此操作
- 比较哈希并删除匹配的条目
基于向量的重复数据删除:
- 将项目转换为向量表示(嵌入)以测量它们的语义相似性。
- 使用 Quadrant、Pinecone 或Weaviate 可以高效地找到相似的项目。
- 在检索到的项目上应用交叉编码器,以更准确地计算它们的相似度得分。此步骤可帮助你自信地识别和消除近似重复项。
个人信息删除
你需要对数据进行去标识化,因为你不希望模型学习(然后告诉所有人)人们的个人信息(除非这是你想要的)。这可能会产生严重的法律和道德影响,尤其是在 GDPR 等法规下。此外,通常,个人数据与领域知识无关。
去标识化:
- 使用正则表达式模式检测常见格式(例如电子邮件或电话号码)。
- 利用专为命名实体识别 (NER) 设计的预训练 NLP 模型来识别和编辑个人数据。
领域特定过滤:
- 可以根据数据的上下文创建过滤器。例如,医疗数据可能需要删除 HIPAA 定义的健康相关标识符。
净化
你的数据集可能包含会对模型行为产生负面影响的内容:
恶意内容:
- 检测并过滤掉针对大型语言模型(例如,提示注入)、脚本、XSS、SQL 注入代码等的嵌入式命令。
- 自动扫描工具或专门的基于 LLM 的分类器可以帮助识别此类模式。
不当语言:
- 过滤诅咒词、诽谤、攻击性内容、俚语。
基于规则的过滤
并非数据集中的所有数据都与你的域或任务相关。基于规则的过滤有助于消除不相关或有害的内容:
- 根据任务定义排除标准。例如,如果你正在训练财务模型,请排除非财务数据。
- 使用关键字搜索、短语或主题建模来识别不相关的内容。
我建议使用混合方法:
- 首先使用简单的工具:
- 使用正则表达式或基于关键字的模式搜索,例如识别电子邮件地址或电话号码。
- 对于剩余的项目,使用高级技术:
- LLM 作为评判者来评估数据的相关性或质量。例如,请 LLM 标记某个项目是否适合训练任务。
- 使用专门的 ML 模型执行复杂的清理任务,例如检测和过滤有毒语言。HuggingFace 上有很多预先训练好的模型。
2.4 数据评估
完成所有这些步骤后,我建议使用单独的管道来检查数据质量。这可以由人工完成,如果你只有几百个样本,可以这样做。但如果有数千个样本,那就不太可能了。因此,再次,你可以使用 LLM 作为评判者的方法,或使用更简单的分类器模型进行自动评估。例如,请参阅 HuggingFaceFW/fineweb-edu-classifier。
对于 LLM,你可以使用以下提示:
You are a data quality evaluator. Your goal is to assess the quality of an instruction and its corresponding answer. Determine how effectively the answer addresses the given task in a clear, accurate, and complete manner.翻译:你是数据质量评估员。你的目标是评估指令及其相应答案的质量。确定答案以清晰、准确和完整的方式解决给定任务的有效性。
评估标准:
- 相关性:答案是否直接解决了说明问题?
- 清晰度:答案是否清晰易懂?
- 完整性:答案是否提供了完成说明所需的所有必要信息?
- 准确性:答案中的信息是否符合事实?
指令:
- 仔细阅读提供的说明和答案。
- 为上述每个评估标准提供分数(1-5)。1 = 非常差;5 = 优秀
- 用每个标准的具体示例或观察结果证明你的分数。
评估示例:
Instruction: Explain the water cycle.
Answer: The water cycle involves evaporation, condensation, and precipitation, moving water between the Earth's surface and atmosphere.
Your Evaluation:
<Relevance>: 5 - The answer directly explains the water cycle.
<Clarity>: 4 - The answer is clear but could elaborate on each step.
<Completeness>: 3 - Missing details on processes like runoff or groundwater flow.
<Accuracy>: 5 - The provided information is correct.
Now, evaluate the following instruction-answer pair:
Instruction: [Insert instruction here]
Answer: [Insert answer here]指令:解释水循环。
答案:水循环涉及蒸发、凝结和降水,在地球表面和大气之间移动水。
你的评估:
<相关性>:5 - 答案直接解释了水循环。
<清晰度>:4 - 答案清晰,但可以详细说明每个步骤。
<完整性>:3 - 缺少径流或地下水流等过程的详细信息。
<准确度>:5 - 提供的信息正确。
现在,评估以下指令-答案对:
指令:[在此处插入指令]
答案:[在此处插入答案]
这里可接受的阈值由你决定,一般我会从 80-90% 开始。
还要注意你为此使用的 LLM,以及 LLM 具有某些偏见(几乎像人类一样):
- 他们更喜欢冗长、冗长和论证的答案,而不是简洁的答案,即使较短的答案更正确
- 列表中的第一个项目通常比其他项目更受模型的青睐。这也称为 Baby Duck Syndrom。如果你正在创建偏好数据集(稍后会详细介绍),这一点很重要。
- 模型偏见 - 来自同一家族的 LLM 可能更喜欢由同一家族的模型生成的数据。如果你要生成用于训练的综合数据,这一点很重要。
3、数据集格式
有几种流行的格式,它们都很小并且使用 JSON,因此你可以使用其中任何一种。
3.1 OpenAI 格式
OpenAI 的微调过程利用 JSONL(JSON 行)格式,其中每行代表一个不同的训练样本:
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Can you explain the concept of photosynthesis?"},
{"role": "assistant", "content": "Photosynthesis is the process by which green plants convert sunlight into chemical energy."}
]
}3.2 Alpaca 数据集格式
由斯坦福基础模型研究中心开发。此数据集中的每个条目结构如下:
{
"instruction": "Describe the structure of an atom.",
"input": "",
"output": "An atom consists of a nucleus containing protons and neutrons, with electrons orbiting this nucleus."
}3.3 ShareGPT
ShareGPT 数据集格式旨在捕捉用户与 AI 助手之间的多轮对话,可容纳“人类”、“GPT”、“观察者”和“功能”等各种角色。此结构可以表示复杂的对话,包括工具交互和功能调用。
每个对话都表示为一个 JSON 对象,包含以下组件:
{
"conversations": [
{"from": "human", "value": "What is the capital of France?"},
{"from": "gpt", "value": "The capital of France is Paris."},
{"from": "human", "value": "Show me a map of Paris."},
{"from": "function_call", "value": "map_search('Paris')"},
{"from": "observation", "value": "<image of Paris map>"},
{"from": "gpt", "value": "Here is a map of Paris."}
],
"system": "You are a helpful assistant.",
"tools": "map_search"
}还有 OASST 和其他,你明白了。
4、微调技术
现在你有了训练数据,让我们看看我们可以用它做什么。主要技术有:
- 全面重新训练
- Lora
- QLoRA
- 直接偏好优化 (DPO)
4.1 全面重新训练
这是在特定数据集上训练整个模型(所有层)以针对特定任务或领域进行优化的过程。理论上最有效,但需要大量计算能力,因为它需要通过整个模型进行反向传播。
由于我们直接弄乱模型权重,因此会带来一定的风险:
- 过度拟合的风险:由于所有权重都已更新,因此对微调数据集的过度拟合风险更高,尤其是在数据集较小的情况下。
- 通用性丧失:微调模型可能会失去其通用能力和先前的知识
那么我们需要多少内存来进行全面重新训练?我们至少需要加载以下内容进行训练:
模型 参数+ 梯度 + 激活 + 优化器状态
a) 模型参数和梯度:
- 7B 模型:大约 70 亿个参数,
- 12B 模型:大约 120 亿个参数,12 10⁹4 = 48GB
每个参数通常需要 4 个字节(FP32 精度)或 2 个字节(FP16 精度)。假设为 2 个字节,因此:
- 对于 7B 模型 710⁹ * 2 = 14GB
- 对于 12B 模型 1210⁹ * 2 = 24G
梯度为每个参数添加另外 2 个字节,因此另外:
- 对于 7B 模型 710⁹ * 2 = 14GB
- 对于 12B 模型 1210⁹ * 2 = 24G
b) 激活:
更大的批次大小以及更高的序列长度会增加内存需求。对于典型的批次大小为 8-32 和序列长度为 512 个标记,激活内存可能会增加:
- 7B 模型:10-20 GB。
- 12B 模型:15-30 GB。
c) 优化器状态:
像 Adam 这样的优化器需要内存来存储其他状态(例如梯度和矩估计)。 Adam 需要两个额外的参数,每个参数有 3 个状态,因此:
- 7B 模型:14GB * 2 * 3 = 42GB
- 12B 模型:24GB * 2 * 3 = 72GB
还有一些其他东西会消耗内存,因此我们预计 7B 模型至少需要 14 + 14 + 10 + 42 = 80GB。
对于小型模型来说,这是很大的内存,你可以想象对于任何大型模型,你需要多少内存。因此,完全重新训练是不切实际的,也很少使用。那么有什么替代方案呢?
4.2 LoRa
假设你想改变模型的行为,但不想改变整个模型。改变模型行为意味着改变它的权重,从而改变输出。这里有一个技巧——如果我们能以某种方式修改模型输出而不改变它们的权重……
当然有办法。在强力解决方案中,我们可以从技术上将模型输出输入到另一个模型中,以对其进行转换。这样可以……只是,我们现在有两个模型,并且增加了许多复杂性。
但是,如果我们可以在模型顶部添加一个过滤器,这将保持原始模型层完好无损并改变其输出,那会怎样?这有点像戴上 AR 眼镜。你以不同的方式看待世界,但世界并没有改变。
这基本上就是 LORA。我们冻结原始模型权重并通过添加称为 Lora 矩阵的额外权重矩阵来应用转换,因此它形成了一个更小的额外可训练层:
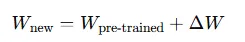
其中:
- Wnew — 新权重
- Wpre-trained — 原始模型权重
- ΔW — 可训练权重调整
我们如何计算这个 Lora 矩阵?我们在该附加矩阵上进行微调/训练,而不是原始模型的改进,使用标准方法,以便它学习如何预测期望结果和原始模型结果之间的差异。
而美妙之处在于 Lora 矩阵可以比原始模型权重矩阵小得多。这就是为什么它被称为低秩自适应,矩阵的秩低于原始矩阵。
假设你有一个大小为 d 的权重矩阵:
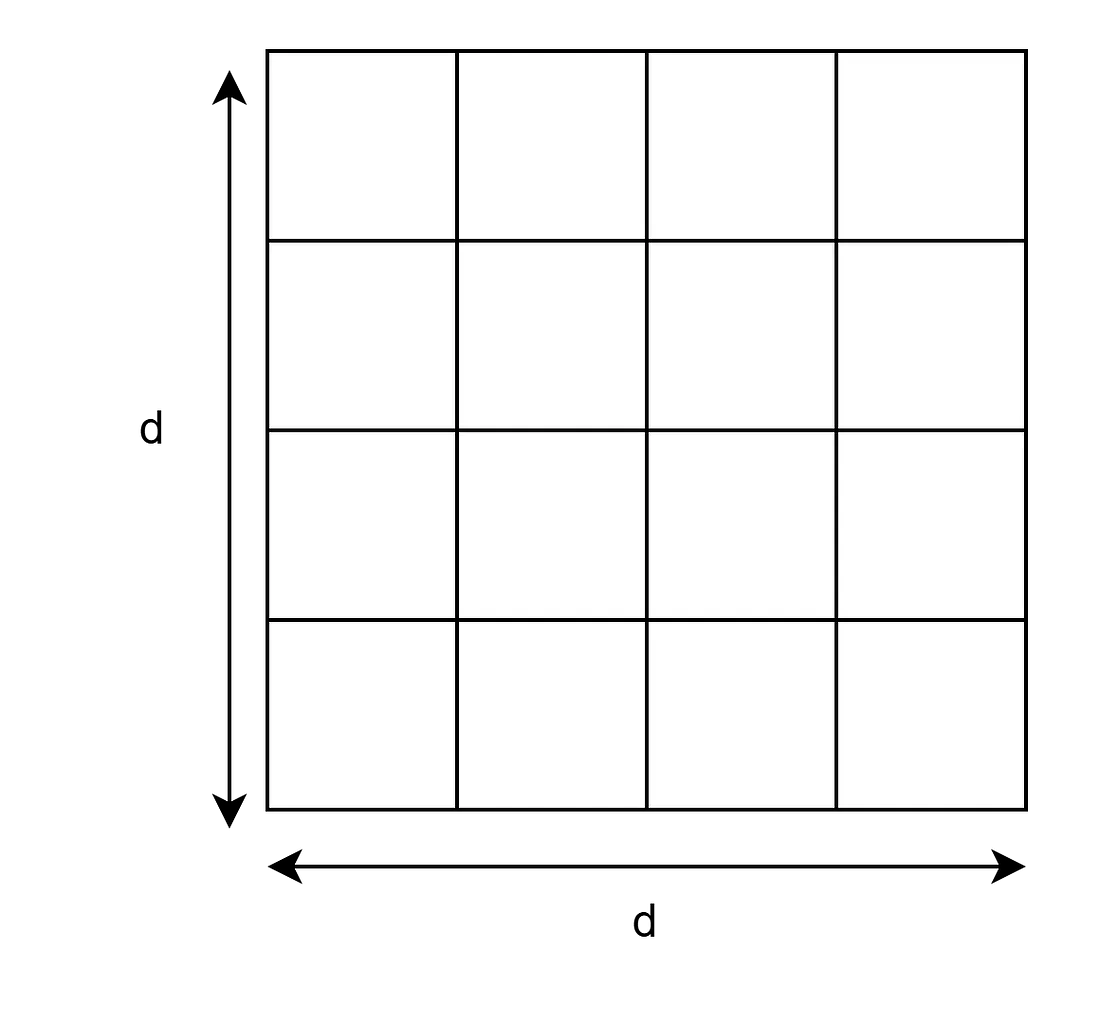
它将有 d*d 个元素。如果 d 是一百万,它将有一万亿个元素。
现在这是 LoRa 的矩阵:
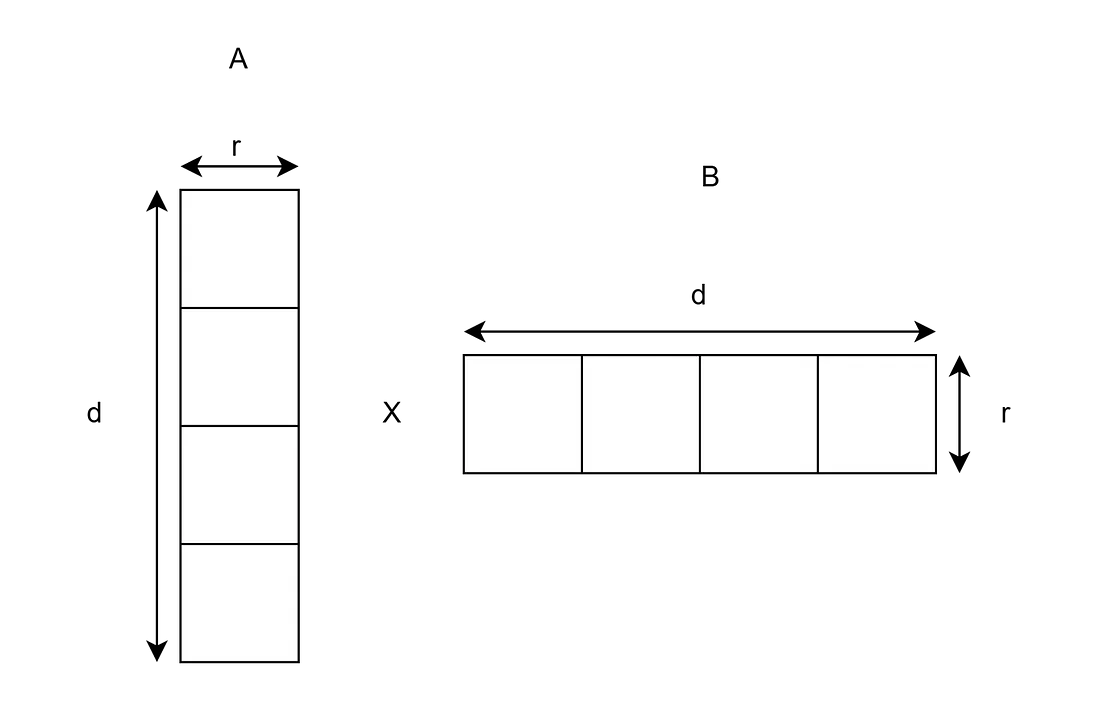
它将有 dr + rd 个元素。如果 d 是一百万,秩 (r) 是 8,它将有 1600 万个元素。
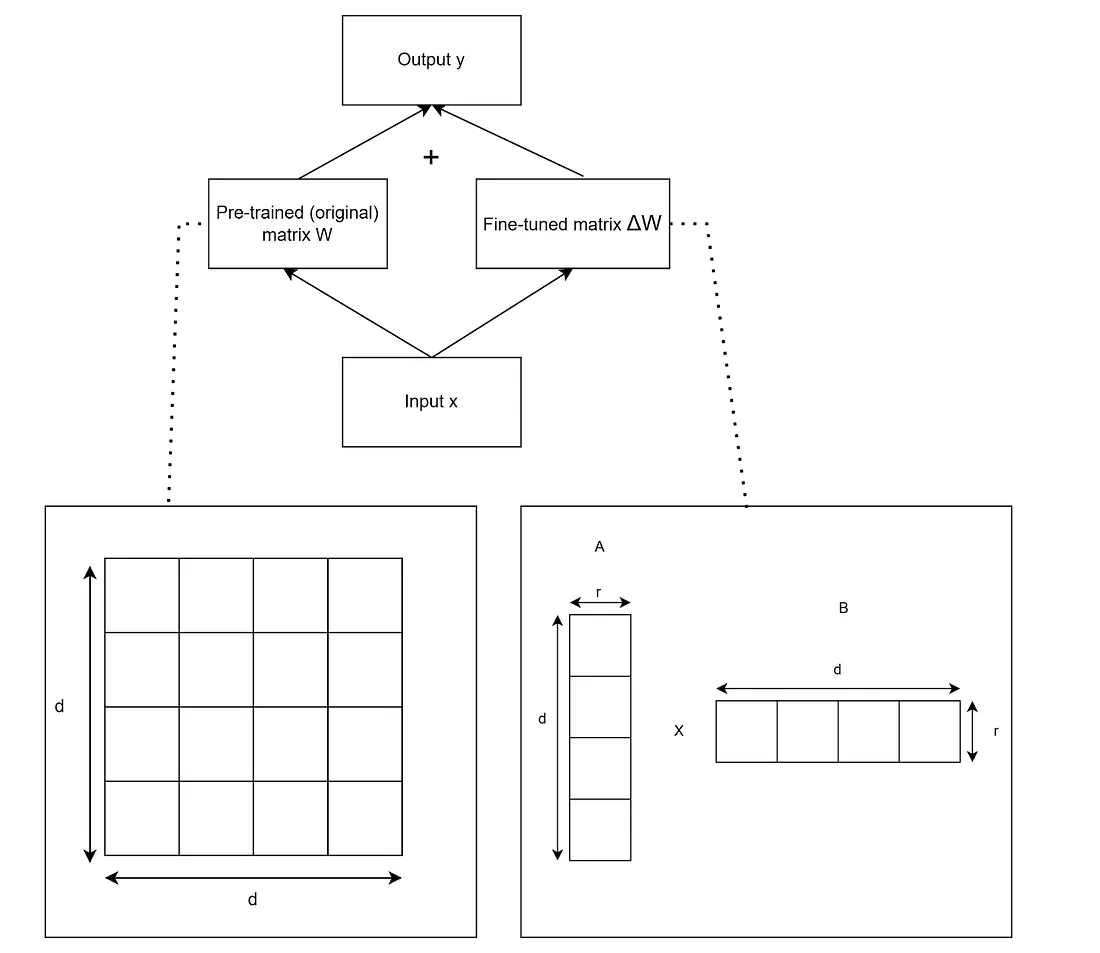
它的工作原理如下:
y = x * (W + ΔW) = x * W + x*(A*B)
- y:应用权重后的输出。
- x:层的输入
- ΔW=A * B
其中:
- A:形状为 dr 的矩阵,其中 r 是秩(为 LoRA 微调选择的小维数),d 与原始权重矩阵的维数相同
- B:形状为 rd 的矩阵
或者以可视形式表示:
秩的常见起点是 8。在某些情况下,使用高达 256 的值会获得良好的结果,但你需要进行实验才能知道哪种方法适合你。使用更大的秩可以提高某些任务的性能,特别是那些需要更强的表达能力来捕捉复杂模式的任务。然而,这也增加了过度拟合的风险,尤其是在较小的数据集上。当模型容量超过数据的复杂性时,这种风险在机器学习中是众所周知的。
在训练期间,我们需要在内存中存储原始模型的权重 W 和微调模型的 ΔW,同时仅计算“新”小矩阵 A 和 B 的梯度。这大大减少了所需的内存和计算能力。训练将更快,并且可以使用台式机 GPU 在 PC 上轻松微调 7b 模型。
不仅如此,我们可以拥有几个不同的“镜头”,就像这个一样,我们可以将它们放在基础模型上,而无需更改它。
LoRA 微调通常可以实现与完全微调相当的性能,特别是当低秩近似非常适合任务并且可以测试或应用 LoRA 适配器而不会冒基础模型降级的风险时。
4.3 QLoRA
与 LoRa 相同,但为了降低内存占用,我们将基础模型量化为自定义数据类型,通常为 NF4(4 位普通浮点数)。常规模型使用 32 位或 16 位浮点作为存储权重的基本数据类型。
NF4 使 QLoRA 能够保留基本模型的大部分精度,同时显著减少内存使用量和计算需求。
量化的理念是:
- 网络中的大多数权重无论如何都是 0
- NF4 根据实际数据统计优化值的分布,而不是使用浮点值的线性分布
对于 LoRa 传递,我们仍将使用常规模型,使用 32 位或 16 位浮点,以便有更大的学习范围。
使用 QLoRa 可以将 GPU 内存使用量减少 40-70%。 然而,它也有代价——QLoRA 在训练中比 LoRA 慢约 30%,并且略微降低了量化模型的质量。
即使在非常大的模型(例如 LLaMA 或基于 GPT 的架构)中,它也能很好地工作。
5、使用(人类)偏好对齐进行微调
微调非常适合训练模型执行特定任务,但不仅要了解模型的功能,还要了解模型如何与人类互动。如果我们想创建一个语言模型助手,就不能直接使用预先训练好的模型——即使它具备所需的知识,也无法智能地回答用户查询。
教模型与人类交流称为对齐。有多种定义方法,我将使用 Antropic 对 3H 的定义:
- 有帮助——响应应该解决用户的问题。
- 无害——响应不应该对用户造成伤害。
- 诚实——响应应该准确无误
传统方法在这里没有多大帮助,因此开发了一套新技术。
任何此类技术的想法都是拥有一个类似于我们上面讨论的数据集,其中还清楚地表明了人类的偏好或价值观。这可能包括对文本质量、语气、风格或事实正确性的反馈。通常,数据集项有多个响应选项,每个选项都按偏好排序。
我敢打赌,你一定见过 ChatGPT 在生成答案时为你提供多个选项——他们这样做是为了收集类似的数据集。问答网站通常有喜欢或赞成/反对系统,也可以用作训练数据。如果你从互联网上抓取数据——事后清理很重要,数据集可能包含大量垃圾。
例如:
用户:“我现在对工作和生活感到不知所措。很难继续下去。”
响应选项:
- 选项 A:“我很抱歉你有这种感觉。你有没有想过和你信任的人或专业顾问谈谈?”
- 选项 B:“你是什么样的人,抱怨就像那样?喝点伏特加就行了——你会没事的。”
人类提供的偏好:
- 首选答案:选项 A(同情心和清晰度最高)。
- 排名:选项 A > 选项 B。
理由:
- 选项 A 表现出同情心,承认用户的感受,并提供可行的建议。
- 选项 B 忽视了用户的感受,没有提供任何建设性的帮助。
或者 JSON 格式:
{
"context": "I'm feeling overwhelmed with work and life right now. It's hard to keep going.",
"responses": [
{
"text": "I'm sorry you're feeling this way. Have you thought about talking to someone you trust or a professional counselor? It might help to share your feelings.",
"rank": 1
},
{
"text": "What kind of man are you, complaining like that? Just drink some vodka - you’ll be fine.",
"rank": 2
}
]
}获得这些数据后,你可以使用以下技术:
6、带有人类反馈的强化学习 (RLHF)
这是偏好对齐的基石。这个想法与训练狗非常相似,在多次迭代中,你会奖励狗做正确的事情,并惩罚做错的事情。在这种情况下,你扮演奖励模型角色,而狗扮演基础模型角色。
因此,有一个单独的奖励模型,该模型经过训练可以使用成对比较来预测人类偏好(例如,“响应 A 优于响应 B”)。基本上,我们训练一个奖励模型来预测响应的排名。
这样做是为了在我们有奖励模型后不必使用人类——它在进一步的训练过程中充当人类反馈的代理。
然后使用强化学习进一步微调主模型,其中奖励信号来自使用强化学习训练的奖励模型,通常经过多次迭代。基础模型不会在此过程中获得新知识,而是学会使用和传达它已经拥有的知识。研究表明,使用小型高质量数据集比使用质量差的大型数据集要好得多(参见 LIMA 研究:少即是多,便于对齐)。
这种方法允许来自奖励模型的复杂奖励信号,包括正确性、相关性、安全性以及各种政治审查废话。它还允许我们使用我们的奖励模型来训练多个基础模型以进行偏好对齐。
缺点也很明显。现在我们必须训练两个模型而不是一个,然后对基础模型进行多次迭代微调。这在计算上很昂贵、复杂且耗时。
此外,奖励模型存在过度拟合的风险,会降低基础模型的性能。
因此,为了避免复杂化,提出了另一种方法:
7、直接偏好优化 (DPO)
这可能是鱼与熊掌兼得的最佳方式。
它是在 Rafael Rafailov 和其他一些人撰写的论文“直接偏好优化:你的语言模型实际上是一个奖励模型”中引入的。他们有一个天才的想法:如果我们跳过中间奖励模型输出,直接使用标准监督学习将模型与人类偏好对齐,会怎么样?
所以这里的区别在于,我们没有单独的奖励模型,也不使用强化学习,而是直接用标准监督学习方法更新基础模型。如果你想知道有什么区别,可以在这里阅读。
监督学习通常使用基于梯度的优化(例如,随机梯度下降)来直接根据标记数据调整基础模型权重。DPO 在时间和成本方面比 RLFH 好得多,因为它不需要多次迭代和单独的模型,但在许多情况下,尽管在某些条件下,它也能提供与基础模型类似的性能和对齐。
这种方法需要高质量的细粒度数据,它对质量的敏感度比 RLHF 更高。数据集中的偏好数据必须充足且直接。如果你有这样的数据集或能够创建一个数据集 — DPO 可能是最好的选择。
8、用于微调实验和托管的内容
当然,如果你有硬件,您可以自行托管并在本地进行训练/部署。你的设置将取决于使用的硬件、模型和虚拟化类型,因此我不会深入讨论。
8.1 编排
一般来说,我建议使用 ZenML 等编排器部署模型,这样你就可以切换基础设施提供商,并避免供应商锁定。然后,你可以先使用一个提供商的免费套餐来构建原型,然后根据需要切换到可扩展的云版本或本地版本。
对于实验,我建议坚持使用云平台的免费套餐,具体来说:
8.2 微调基础设施
AWS SageMaker:一种完全托管的服务,用于在 AWS 上构建、训练和部署机器学习模型。非常方便,因此你不必构建自己的基础设施并购买 GPU。他们有免费套餐可以开始实验。
替代方案:
- Google Vertex AI
- Azure 机器学习
- Databricks ML
- MLflow — 这是一个开源的,可以自行托管
8.3 模型托管
对于实验和协作,最好的选择是 HuggingFace — 用于共享和发现机器学习模型、数据集和演示的协作平台。它就像模型的 github。他们也有免费套餐。
替代方案:我认为没有好的替代方案,这就是它们如此受欢迎的原因。所有主要参与者(Google、Azure AI Playground)都有类似的东西,但不那么好。
对于生产,你可以使用
- AWS SageMaker
- Google Vertex AI
- Microsoft Azure 机器学习
- MLflow(可以本地部署)
原文链接:Llm Fine Tuning Guide: Do You Need It and How to Do It
汇智网翻译整理,转载请标明出处
