LLM推理提供商选型指南
每一个LLM推理提供商都有其优缺点。没有一个普遍的“最佳”选择——只是不同优化于不同任务的工具。

我一直在生产环境中使用LLM构建,从gpt-3的测试版发布以来已经五年了。从“只使用OpenAI”到如今众多的提供商,每个提供商都有自己的权衡。这是我关于为你的用例选择合适提供商的一些经验。
LLM提供商的简单真相
每一个提供商都有其优缺点。没有一个普遍的“最佳”选择——只是不同优化于不同任务的工具。经过多年的构建,我发展出了一些实际有效的启发式方法。
要选择合适的提供商,以你的约束条件为优先。可能是延迟、成本、可靠性或模型质量。选择一两个。你不能同时拥有四个。
好消息是:供应商锁定已死。现在每个人都支持OpenAI兼容的API,因此切换提供商通常只是更改基础URL。
1、OpenAI:显而易见的起点
OpenAI仍然是他们GPT模型的唯一提供商,而且他们让入门变得非常容易。他们的免费层级相当慷慨——大约每月500美元(如果你愿意让他们使用你的数据进行训练)(许多原型可以接受)。
开发人员体验无与伦比。良好的文档、稳定的API,每个教程都假设你使用它们。你支付溢价,但后来切换出去很简单,因为API兼容性。
2、Anthropic:程序员的选择
Claude已成为编码任务的首选模型。这些模型的训练方式似乎特别擅长理解并生成代码。如果你不构建编码功能,通常可以在其他地方找到更便宜的选项。
他们的Opus模型在复杂推理任务中确实处于最先进水平。当你需要在复杂问题上获得最佳性能时,Claude Opus和OpenAI的最新模型是你的唯一真正选择。
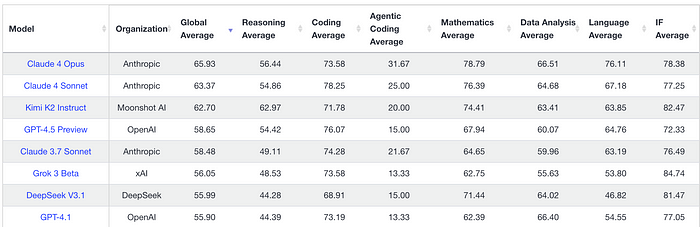
这是Livebench的基准测试结果,显示Anthropic模型位居榜首(如果排除推理模型的话)。
对于编码的主导地位无法忽视,开发者不仅因为一般编码能力而偏好这些模型,还因为前端风格和品味。
3、Inference.net:价格低廉且有微调专家

Inference.net有一个更巧妙的角度:他们利用计算价格差异,在价格低的时候购买未使用的容量。GPU农场和云并不总是有计算资源,当利用率不足时,Inference会迅速介入并使用它进行LLM推理。
这使他们能够提供极其低廉的推理价格。Inference真正的优势在于对时间不敏感的请求。如果一个请求不需要立即响应,Inference可以等到廉价计算可用时再返回响应,通过webhook或最可扩展的批量API返回。
对于互联网规模的大批量分类,他们是明确的胜者。他们会帮助你训练更小的任务特定模型来降低成本,或者在足够时运行默认的小模型。
他们还有内部团队负责训练自定义模型,这使他们与众不同。如果你注意到开放模型对于你的用例来说太昂贵或太慢,可以联系他们,他们会为你训练更好的模型并为你托管。
4、Groq、Cerebras和SambaNova:性能怪兽
这些提供商使用定制芯片(Groq的LPUs,Cerebras的晶圆级芯片)实现真正的惊人延迟。一致的子200毫秒首次标记时间和顶级每秒标记数,其他任何东西都无法比拟。
但现实是:他们托管的大型模型很少。是的,你可以在他们身上运行DeepSeek或Kimi,但他们受到容量问题的困扰,而且他们的定价使他们在成本优化时完全不合适。我的做法是:使用他们的免费层级用于延迟关键路径(语音接口、实时功能),然后回退到传统提供商。他们是突发提供商,不是批量提供商。
Groq的whisper(转录)模型很好。非常快且价格合理。
5、Google:非常、非常优秀
Google的地位很有趣。他们在小型和大型推理模型方面都很有竞争力,具有出色的延迟和激进的定价。Gemini Flash和Flash-Lite确实快速且便宜。他们的免费层级很慷慨,如果你是初创公司或企业,你可能会协商到信用额度。他们快速、便宜且可扩展。
权衡点:闭源模型。许多企业更喜欢可以审计和部署在本地的开源权重。只想得到工作的推理的团队越来越多地转向Google。
很难想到关于Google作为LLM提供商有什么负面的东西,除了偶尔OS模型在性能上超过Google的模型。仍然,大实验室、Google和OS之间不断竞争,Google一直是一个主要参与者。
关于Google的一件事是,他们的产品非常令人困惑,包括Vertex AI和Gemini。
这是我使用Google的方式:
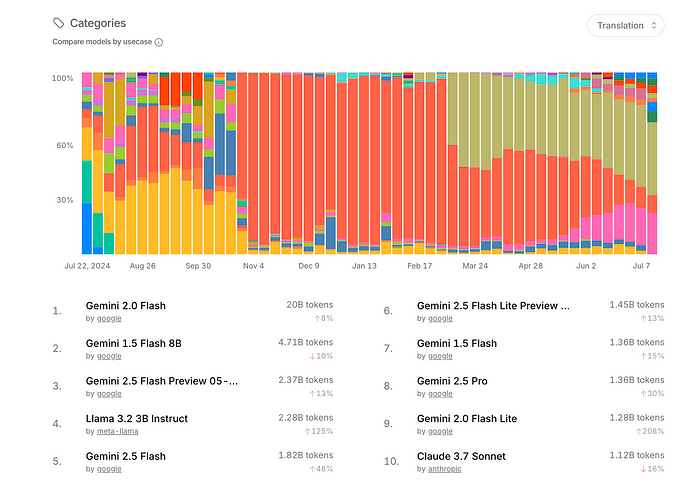
- 你对价格非常敏感。Google的Flash也是当前小型模型使用案例(如翻译和分类)的市场领导者。
6、Together和Fireworks:GPU仓库
Together建立了一个相当于巨大的GPU集群,可以运行各种开源模型。他们可靠、企业级,并且价格反映了这一点——相比Inference、Novita和Deepinfra,他们的价格一直在上涨。这是因为他们是最早的企业级推理提供商之一。Fireworks最初是推理优化专家,但同样进入了高端市场。仍然以其非常快速、可靠的推理而闻名。街上的传言是Fireworks通过使用TensorWave的超级便宜的AMD GPU保持低价。
当您需要大规模运行特定的开源模型并有真实的SLA时,这两个都是不错的选择。选择哪个取决于您的特定模型的速度/价格。
7、DeepInfra和Novita:竞速到底
DeepInfra和Novita由超级疯狂的工程师运营,他们是最优秀的模型服务优化者之一。他们存在的目的是赢得OpenRouter价格排行榜,并不惜一切代价尽可能便宜地提供模型。有趣的是,Novita最近转向了企业风格,类似于Together和Fireworks,同时保持了最低的价格。DeepInfra走得更远,将模型服务的价格定为大约电费的价格。
8、Mistral:企业策略
Mistral已经掌握了企业销售。他们是法国人,有开源模型,并且在处理采购部门方面非常出色。如果你是一家需要本地部署或特定合规保证的企业,Mistral会与你合作。如果你是一家欧洲公司,想要确保自己符合法规,Mistral是一个很好的选择。
个人开发者很少会选择Mistral。他们的文档解析API存在,但并不具有竞争力——专门的提供商如Reducto和Chunkr在这方面做得更好。这是一家专门为向大公司销售而优化的公司,目标客户并不是独立开发者。
9、LLM提供商速查表(2025版)
如果你不想阅读以上所有内容,这里是我的简单速查表。
- 需要原型速度?→ OpenAI
- 编码?→ Anthropic Claude
- 实时语音?→ Groq(直到配额用完)
- 批量/异步任务?→ Inference.net, Google
- 复杂PDF?→ Reducto, Chunkr(我会避免使用纯LLM提供商,它们在文档解析方面表现不佳)
- 合规要求高的企业?→ Mistral, Azure
- 开放模型多样性规模?→ DeepInfra, Fireworks
- 极其便宜的推理:Inference.net, DeepInfra
- 没有经验的模型蒸馏/微调:Inference.net
10、我的实际做法
我只使用OpenRouter。每个提供商都有可靠性问题,而OpenRouter处理这个问题。但如果你需要企业级SLA或想节省他们的5.5%费用,使用OpenRouter并不是一个好选择。许多用户从OpenRouter开始,然后迁移到能满足他们需求的单一提供商。供应商锁定不再是问题,我通常只是选择最便宜的选项。
11、“最佳”提供商
“最佳”提供商每月都在变化。新模型推出,价格波动,免费层级消失。唯一获胜的策略是保持松耦合并使切换变得便宜。
由于处处都是OpenAI兼容的API,可移植性非常容易。从一开始就考虑这一点,或者直接使用OpenRouter,你可以随着市场的变化追逐最佳性价比。
原文链接:How to choose an LLM inference provider in 2025
汇智网翻译整理,转载请标明出处
