LLM驱动的新闻分类和趋势检测
为了在这个高度竞争的环境中不仅保持竞争力,而且找到新的竞争优势机会,公司强烈激励尽早发现相关的新兴主题和趋势,以制定适当的未来应对策略。

本文档记录了 MAPEGY在其资助的 KI4BoardNET 研究项目中所做的部分贡献。该项目由* 联邦教育与研究部(德国)资助。
为了在这个高度竞争的环境中不仅保持竞争力,而且找到新的竞争优势机会,公司强烈激励尽早发现相关的新兴主题和趋势,以制定适当的未来应对策略。[Muhlroth & Grottke 2022]
1、新闻分类和自然语言处理介绍
在商业智能的应用中,新闻文章是获取相关和及时信息的重要来源。自然语言处理(NLP)和文本挖掘方法可以用来分析这些数据并提取相关信息。例如,新闻文章可以用来衡量公众情绪——参见我的前一篇博客文章。
NLP方法还可以帮助分析师更有效地探索大量新闻文章,通过检测事件和趋势[Panagiotou et al. 2022],或总结关键点[Ma et al. 2022]。
去除无关结果如假新闻[Capuano et al. 2023]也可以减少数据洪流。相反,如果有一个系统能够帮助他们专注于最相关的新闻,分析师将从中受益匪浅。
一种识别最有可能包含相关信息的文章的方法是自动新闻分类。特别是那些希望收集信息来制定创新战略的技术和趋势侦察员,对属于以下一个或多个类别的新闻特别感兴趣,我们也可以把这些类别称为类型:
- 市场研究报告提供对特定行业或市场环境的深入分析,包括竞争动态评估、趋势预测和机会。示例:《全球插电式混合动力电动汽车市场报告2023:电动汽车的快速采用预示着持续且显著的增长》
- 初创企业新闻涵盖新技术公司、风险投资资金、初创企业的新产品和服务、初创加速器和孵化器以及初创成功和失败的故事。示例:《Figure筹集7000万美元以商业化人形机器人》
- 业务关系、合作伙伴关系和并购新闻关注公司之间的战略联盟、合资企业和公司收购。这些故事提供了关于竞争格局可能如何变化以及可能出现哪些新协同作用或能力的见解。示例:《Mullen Automotive Inc.(纳斯达克:MULN)宣布与Amerit Fleet Solutions的战略合作》
- 消费者和产品新闻包括对新技术产品的评论和公告、主要产品展会和展览的报道以及客户最感兴趣的特性和设计的见解。示例:《2023年比亚迪Atto 3评测》
- 法律新闻报道影响技术和业务的新立法、法规、政府政策、诉讼和知识产权问题。示例:《法国禁止国内短途航班以减少排放》
一种简单的自动化新闻分类技术是关键词搜索。例如,我们可以预期一篇包含关键词“初创企业”、“风险资本”或“天使投资者”的新闻文章是一篇属于初创企业新闻类别的文章。
本报告的目标是比较传统关键词搜索在新闻分类方面的性能(准确性及运行时间)与最先进的机器学习方法。
2、趋势信号检测
除了上一节列出的新闻类别外,我们还希望检测趋势信号,我们将这些理解为描述事件、声明事实或反映意见的新闻文章,这些都指向潜在的重大变化,即创新和技术领域的变革。换句话说,趋势信号可以理解为新兴趋势的先兆。
趋势信号的新闻类别非常广泛,可能涉及以下任何子类别。其中一些子类别可能与其他定义的新闻类别有较大的重叠。
1. 科学与技术
1a. 新材料或方法。 讨论新型制造技术的发展和发布以及能改善产品、服务或技术的新材料的新闻文章。示例:《“智能塑料”材料是软性机器人和电子设备向前迈出的一大步》
1b. 效率或效果的进步。 涵盖现有产品或技术在功能、适应性、性能或可用性方面成功改进的文章。示例:《新型电池技术使电动车续航里程提高20%》
1c. 现有技术的创新应用。报道当前技术或产品的创造性新用途的文章,赋予它们替代用途。这可能涉及到回收或重新利用副产品、材料、应用或系统。示例:《三种令人惊讶的电动汽车电池再利用方式》
1d. 科学发现和突破。报道重大科学研究成果、新发明、进步或发现的文章,这些解决了问题、降低了成本或开启了新的应用。示例:《科学家打破太阳能窗户材料的世界纪录》
2. 经济与政治
2a. 初创企业。报道具有自主技术、工艺、设计或材料的创新型初创企业的文章,这些初创企业解决行业挑战、重塑制造业或促进可持续发展。可能会详细说明初创企业的作品、合作伙伴关系或融资情况。
2b. 兼并与收购以及合作关系。报道公司投资初创企业、战略性合作、合并、被收购、上市或筹集资本以推动产品开发或发布的文章。
2c. 政策变化、新立法和资金机会。报道政府决策、政策、公共合同、资助计划、法律、法规或影响特定行业或市场的经济政策的文章。政策可能与政治领导层的变化有关。
2d. 新市场进入者。报道现有市场中出现的新竞争对手的文章,包括大型企业扩展到新领域或新企业进入成熟市场。示例:《特斯拉开放其电动汽车充电网络》
3. 社会与市场
3a. 技术或高科技产品的“炒作”或“热度”。讨论当代新兴技术或产品在研究人员、行业参与者、政策制定者或用户中暂时受到广泛关注的文章。示例:《五项将定义电动汽车未来的科技趋势》
3b. 影响公众对技术或企业看法的事件或声明。报道未预见的新闻或事件,这些新闻或事件正面或负面地影响了公众对特定技术、公司或行业领导者的看法。可能包括事故、诉讼、不当行为指控、产品质量缺陷或声誉建设公告。示例:《电动汽车的十个不为人知的秘密》
3c. 高科技产品的发布。报道新技术产品、系统、材料、技术、功能或设计发布的文章,这些提供了额外的功能、应用或好处。示例:《新款Abarth 500e:蝎子再次出击,现在全电动模式》
趋势信号可以是强信号,即关于广泛报道的事件。因此,许多趋势信号可能指向同一事件,而聚类分析可以帮助识别这些事件。
然而,趋势信号检测之所以是一个强大的概念:趋势信号不是由信号强度定义的,因此也可以是早期信号或弱信号。基于时间序列分析的传统趋势检测方法很难检测早期信号,因为还没有形成可识别的稳定趋势。同样,弱信号往往被噪声淹没,使得仅通过无监督的数据流分析难以检测。
3、设置和评估范围
对于新闻分类和趋势信号检测,既可以使用基于规则的方法(即关键词搜索),也可以使用机器学习。
任何给定的文章可能属于任意数量的类别,包括没有分配到任何类别的文章。这被称为多标签分类任务。我们将此任务视为一系列二元分类任务,旨在确定文章是否属于特定类别,这相当于分配一个正类标签。如果分类器分配了一个负类标签,则它已确定该文章不属于相应类别。
本报告的目标是比较以下方法的性能:
- 基于识别文章标题和简短摘要中关键词的规则进行的基于规则的分类,
- 零样本分类应用于标题和简短摘要,
- 在自定义数据集上微调的大规模语言模型(LLM),该数据集由MAPEGY标记。
在实践中,可以通过正则表达式最有效地实现关键词搜索。以下代码是一个正则表达式示例,如果匹配标题,将导致文档被归类为“初创企业新闻”:
(\yseed|\ycrowd) funding|\yventure capital\y|
\yangel invest|\yentrepr?eneur|silicon valley|
\ystart-?ups?\y|
((\ynew\y|\yinnovative\y|
\ynewly\y \y[[:alpha:]]*\y) (\ycompan(y|ies)\y|
\ycorporations?\y|\yorgani(z|s)ations?\y|
\yendeavou?r\y|\yventure\y|entrants?))
4、训练和测试数据准备
截至2023年6月,MAPEGY创新图谱包括自2016年以来从超过10,000个新闻源中收集的超过7000万篇新闻文章。MAPEGY的数据团队精心策划这些新闻源,确保它们包括高度相关的创新和技术领域的新闻源:
- 技术新闻,如麻省理工科技评论、The Verge、Techcrunch,
- 来自自然等科学新闻机构或聚合器如Phys.org、ScienceDaily的科学新闻,
- 一般商业新闻,如福布斯、金融时报,
- 专门针对最新技术、经济和社会趋势的高技术公司警报,
- 关注各种行业的关键信息来源,从3D打印到白色家电的创新服务和制造产品。
这些来源还包括国际新闻机构和国家新闻媒体设置的新闻源,如路透社、BBC、CNN、半岛电视台和南华早报。
为训练和测试新闻分类算法准备手动标注数据集的一个特别挑战是,我们大多数新闻类别的标签分布严重不平衡。例如,MAPEGY数据库中只有大约1%的新闻是初创企业新闻。鉴于资源有限且只有少数人工数据标注员,这使得简单地检索随机样本新闻文章并手动标注它们变得不切实际:我们需要标注太多文件才能创建包含足够数量正例的训练和测试数据集。
相反,呈现给数据标注员的数据集是通过启发式方法提取的,这些方法根据用于基于规则分类的正则表达式添加文档。这些规则经过修改,以便产生大量正例,同时仍然代表语料库。例如,在文章的简短摘要中搜索“收购”一词而不是仅仅在标题中搜索会产生可能与业务关系相关的文档,但也产生其他事件或事实的无关文章。
以这种方式提取的文档被汇总,并成对呈现供标注,即给定三个数据集中的一种,数据标注员必须决定每篇文章是否属于以下类别之一:
- 市场研究报告、法律新闻、两者或两者都不是,
- 初创企业新闻、业务关系、两者或两者都不是,
- 产品新闻、趋势信号、两者或两者都不是。
下表显示了标注后的数据集,包括正类标签的百分比,以及语料库中正类标签的估计百分比:
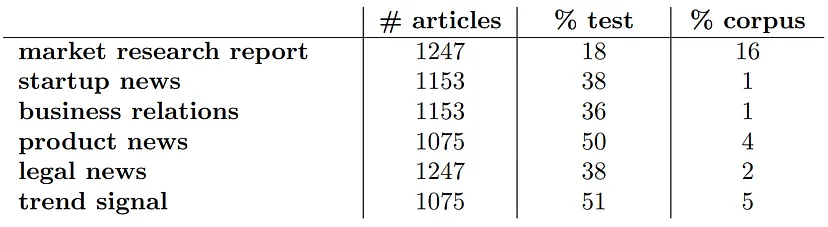
语料库中正类标签的百分比是基于大量示例的基于规则的标签估算的。
这些正则表达式可以用作弱监督学习的标签函数——这是一个值得注意的选择,但我们在本文中不进一步探讨,详见[Lison 2021]。
从每个数据集中随机选择300篇文章作为测试数据集。
5、实现和使用的工具
评估是在Google Colab中进行的,训练和测试数据存储在Google Sheets中。Python包已经在前一篇文章中列出。
对于基于规则的分类,使用了手动通过试错创建的正则表达式。
对于零样本分类,使用了Hugging Face模型仓库中流行的bart-large-mnli模型:一个BART模型[Lewis et al. 2019],训练于MultiNLI数据集[Williams et al. 2018]。
零样本模型的任务是确定新闻更适合通用提示“普通新闻”,还是以下之一:“市场研究”、“初创企业新闻”、“业务关系”、“消费者新闻,产品”、“法律、诉讼和政策”、“炒作、热潮、趋势”。
需要注意的是,二元分类可以被视为零样本分类的超范围使用。其次,没有认真尝试优化提示。因此,关于零样本分类的评估结果仅作为另一个基线,不应视为该技术的一般代表性。
微调的基础是distilroberta-base模型。
6、评估结果
由于生产数据集在比例上比用于评估的测试数据集更加不平衡,我们需要使用不受正类与负类标签比例变化影响的性能指标。一个选项是平衡准确度,如下所示:
平衡准确度 = 0.5 × (特异度 + 敏感度)
敏感度也称为召回率。Youden指数[Youden 1950]是对平衡准确度的简单重新缩放,范围在-1到+1之间:
Youden指数 = 2 × 平衡准确度 - 1
Youden指数为1表示分类器做出的所有预测都是正确的,而等于-1则意味着分类器对每个测试样本都分配了相反的真实标签。消失的Youden指数对应于将所有测试样本都分配为正标签或负标签的基线。另一种具有类似属性的性能指标是Matthews相关系数[Baldi et al. 2000]。
比较不同方法在不同新闻类别下的Youden指数,得到以下结果:
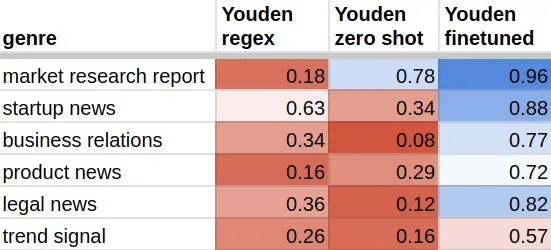
基于规则的方法平均每秒可以确定6000篇文档是否属于某个特定类别。运行时间性能取决于正则表达式的复杂性和长度,范围通常从每秒2000到10,000篇文档不等。
在Google Colab中的“标准”GPU上,零样本分类器的运行性能仅为每秒4个示例;微调模型的性能为每秒36个示例。
以下混淆矩阵显示,微调的LLM在识别市场报告方面的预测性能几乎完美:
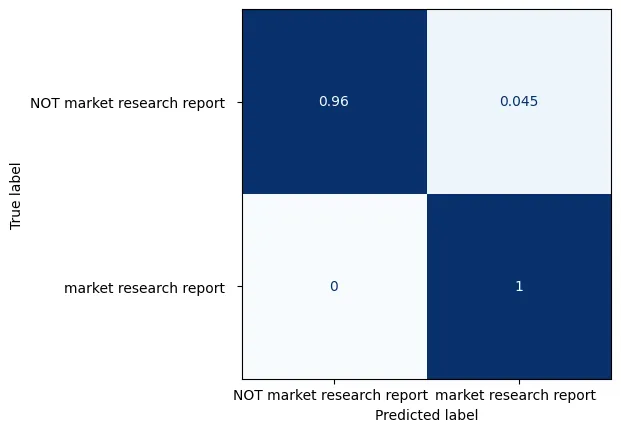
微调LLM识别市场研究报告的混淆矩阵
矩阵被归一化,使得行总和为100%,即对角线元素显示特异性和召回率。
另一方面,用于识别市场报告的正则表达式侧重于特异性,以避免错误地将非市场研究报告的文章标记为市场研究报告:
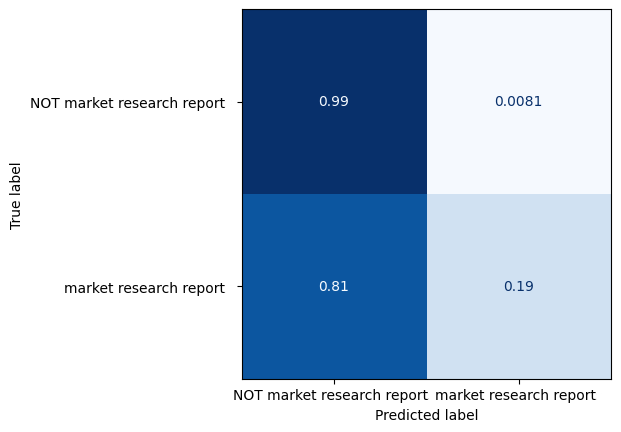
其他正则表达式的设计可能会导致性能特征大不相同。
基于规则的方法可以很好地识别初创企业新闻:
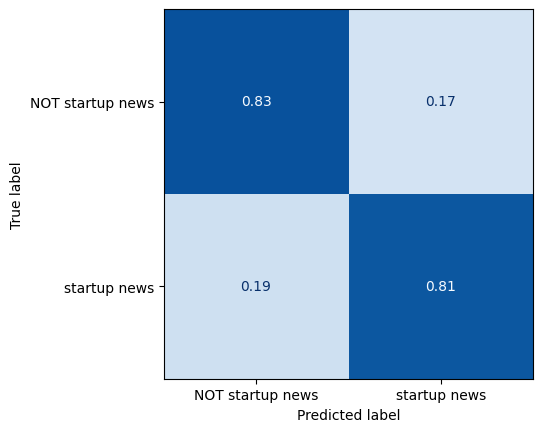
我们可能认为这是因为初创企业类别可以通过一组有限的特征关键词很好地描述。然而,LLM的表现仍然显著更好:
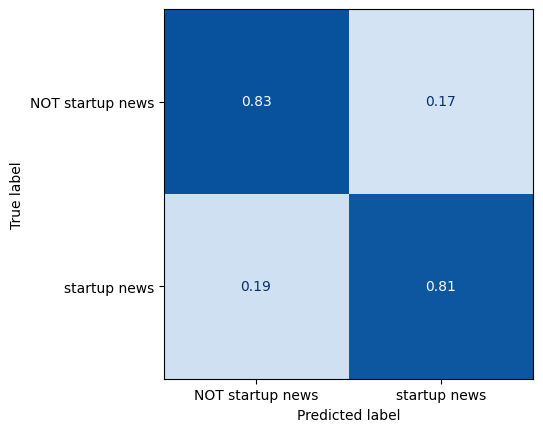
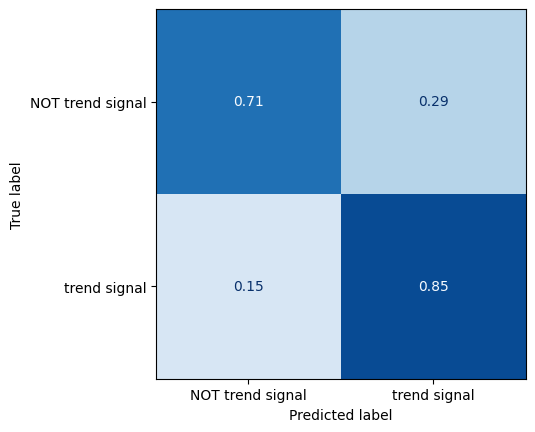
即使对于微调过的LLM来说,检测趋势信号也是一个困难的任务。我们可能推测,这可能是由于该类别的宽泛和不太明确的性质。额外的训练数据可能会提高性能。尽管如此,算法仍能正确识别数据流中85%的趋势信号:
7、结论
- 微调的大规模语言模型(LLM),在大约每类标签1000篇新闻文章的小型数据集上进行微调,相比基于关键词匹配的基于规则的新闻分类,其结果明显更优。
- 对7000万篇新闻文章进行分类预计需要约135天的“标准”GPU计算时间。
- 基于规则的新闻分类要快几个数量级。
参考文献
[Muhlroth & Grottke 2022] Christian Muhlroth 和 Michael Grottke。“人工智能在创新中的应用:如何发现新兴趋势和技术。”IEEE工程管理学报。69, no. 2 (2022年4月): 493–510。
[Panagiotou et al. 2022] Nikolaos Panagiotou, Antonia Saravanou 和 Dimitrios Gunopulos。“新闻监测:实时探索新闻的框架。”数据7, no. 1 (2022): 3。
[Capuano et al. 2023] Nicola Capuano, Giuseppe Fenza, Vincenzo Loia 和 Francesco David Nota。“基于内容的假新闻检测:机器学习与深度学习的系统综述。”神经计算 530 (2023): 91–103。
[Ma et al. 2022] Congbo Ma, Wei Emma Zhang, Mingyu Guo, Hu Wang 和 Quan Z. Sheng。“多文档摘要:基于深度学习技术的调查。”ACM计算机调查 55, no. 5 (2022)。
[Lewis et al. 2019] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdel-rahman Mohamed, Omer Levy, Veselin Stoyanov 和 Luke Zettlemoyer。“BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。”计算语言学协会年会 (2019)。
[Williams et al. 2018] Adina Williams, Nikita Nangia 和 Samuel Bowman。“通过推理理解句子理解的广覆盖挑战语料库。”北美计算语言学协会会议论文集:人类语言技术卷 (2018): 1112–1122。
[Lison 2021] Pierre Lison, Jeremy Barnes 和 Aliaksandr Hubin。“skweak:NLP的弱监督易于实现。”计算语言学协会年会 (2021): 337–346。
[Youden 1950] W. J. Youden。“诊断测试的评级指数”。癌症 3.1 (1950): 32–35。
[Baldi et al. 2000] Pierre Baldi, Søren Brunak, Yves Chauvin, Claus A. F. Andersen 和 Henrik Nielsen。“评估分类预测算法的准确性:概述。”生物信息学 16, 卷5 (2000年5月): 412–424。
原文链接:LLMs for innovation and technology intelligence: news categorization and trend signal detection
汇智网翻译整理,转载请标明出处
