LLM温度参数简明教程
如果你过去曾与 AI 助手或 LLM(大型语言模型)互动过,可能已经注意到一个名为温度 ( temperature)的参数。

如果你过去曾与 AI 助手或 LLM(大型语言模型)互动过,可能已经注意到一个名为温度 ( temperature)的参数。
在这里,我们将了解温度如何影响 LLM 输出、其计算以及一些不同温度值的示例。
你可以在此处尝试跨不同 LLM 进行一些小的温度变化。更详细的温度示例在这里。
1、LLM 的温度到底是什么?
LLM 温度是一个控制 LLM 预测的下一个单词的概率分布的参数。它通过改变下一个单词被选中的可能性,为 LLM 的输出增加了一些随机性或多样性。它可以影响 LLM 的输出,使其更加确定(可预测)或更加随机(随机)。温度等参数用于模拟或模仿人类语言生成中的固有变化。
在生产中,温度值通常介于 0–2+ 之间。
- 较低的温度值(<1)可以产生更确定或更可预测的 LLM 输出,称为使 LLM 更“可预测”。
- 温度 1 默认为训练期间学习到的 LLM 固有单词分布,反映了 Softmax 函数的未改变输出(稍后会详细介绍)。
- 较高的温度值(>1)可以产生更随机或随机和变化的 LLM 输出,称为使 LLM 更具“创造性”。然而,“创造性”一词可能用词不当,因为产生更多样化的输出并不一定等同于创造力。
当温度值设置为 0 时,大多数系统会触发贪婪采样以进行下一个单词预测,即简单地选取词汇表中概率最高的单词(注意:文本生成还有其他采样方法,请参见此处)。在某些情况下,如果温度值过高(>>2)或过低(=0),则可能会触发退化行为,如重复循环或 LLM 幻觉。
LLM 中的幻觉是指看似合理但事实上不正确的输出,或不连贯和无意义的文本。该术语在比喻上类似于一个人对实际上不存在或不真实的事物的感知。
重要的是要注意,0 到 2 之间的温度值不会消除幻觉;相反,它们会将随机性和多样性引入输出,这可能会根据上下文增加或减少幻觉。为了减轻幻觉,可以采用检索增强生成 (RAG)、思维链 (CoT) 等策略和其他技术来提高 LLM 生成文本的准确性和连贯性。

2、LLM 回顾
在深入研究数学之前,让我们先简单了解一下 LLM 的工作原理。
LLM 可以被认为是基于从大量训练数据中学习到的模式和关联来预测下一个单词的模型。在训练期间,LLM 通过称为反向传播的过程调整其内部参数,从大量文本数据中学习模式、语法(单词排列)和含义。
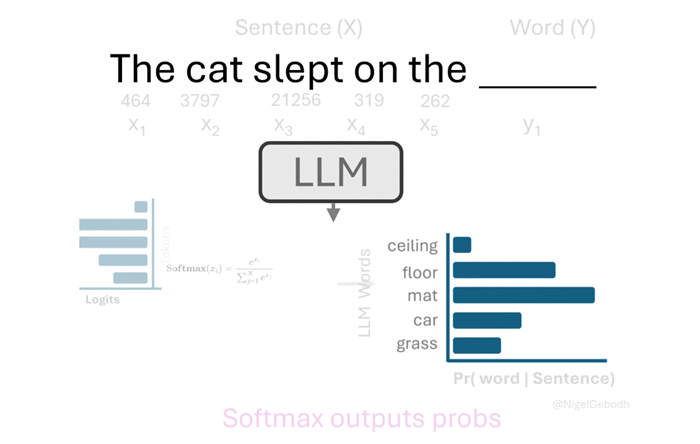
LLM 对输入文本采取的步骤:
- 标记化:输入文本被分解为更小的单元(标记),例如单词或子单词,从而使模型能够处理可变长度的输入。
- 嵌入:每个标记都映射到一个唯一的数字表示(使用查找表或嵌入层),从而捕获语义含义。
- 编码:标记嵌入通过模型的多个层(例如,转换器)进行处理,这些层会创建上下文化的向量表示,以理解上下文中单词之间的关系。
- Logits 计算:解码器模型(通常在 GPT 等自回归模型中)根据处理后的输入为序列中的每个标记生成原始的、未归一化的输出分数(logits)。
- Softmax 激活:logits 通过 softmax 函数传递,将它们转换为可能的下一个标记的概率分布,表示每个标记成为序列中的下一个标记的可能性。
- 单词选择:模型根据概率分布选择一个单词(或标记),通常是通过选择最可能的标记或从分布中抽样以获得更多样化的输出。
3、数学
Softmax 函数是一种数学转换,它采用原始分数向量并将其转换为概率分布。它通过对每个值求幂并对结果进行归一化来实现这一点,但所有求幂值的总和为 1。最初应用程序
它于 1868 年左右出现在物理学和统计学中,被称为玻尔兹曼分布或吉布斯分布。术语“softmax”由 John S. Bridle 于 1989 年创造。
在自然语言处理 (NLP) 中,Softmax 函数通常应用于 LLM 生成的对数,以产生可能的下一个标记的概率分布。此分布表示每个标记成为序列中的下一个单词或子单词的可能性。
Softmax 函数定义为:

Softmax 函数。
其中:
- xᵢ 输入的每个值(logit 值)
- eˣⱼ 是每个输入值的幂(欧拉数:e ~ 2.71828)
- Σⱼᴺ eˣⱼ 是所有幂(e)输入(x)的总和
温度(T)参数是对 Softmax 函数的简单修改,用于调整输入:

术语“温度”借用自物理学领域。它来自与玻尔兹曼分布的关系,后者描述了能量状态如何随温度变化。机器学习中术语“温度”的早期使用来自 1985 年的 Ackley 及其同事。
4、示例
有关完整示例集,请参见此处。
示例 1 — 不带温度的简单 Softmax 变换。
给定一个数字列表,计算它们的 softmax 概率。
list=[2.0,4.0,3.0]手动:

使用 Python:
#Calculating Softmax
import torch
import torch.nn.functional as F
#1) Using Our Function
#Define a softmax function
def my_softmax(input_vector):
e = np.exp(input_vector)
return e / e.sum()
list_in = [2.0, 4.0, 3.0]
output = my_softmax(list_in)
print(f"\nThe softmax probabilities are: \n {output}")
#2) Using PyTorch Function
#Convert list to torch tensor
list_in_torch = torch.tensor(list_in)
output = F.softmax(list_in_torch, dim=0)
print(f"\nThe softmax probabilities (using Pytorch) are: \n {output}")The softmax probabilities are:
[0.09003057 0.66524096 0.24472847]
The softmax probabilities (using Pytorch) are:
tensor([0.0900, 0.6652, 0.2447])示例 2 — 温度变化下的 LLM 输出 Softmax 变换
给定 LLM 的 logit 输出列表,找出最可能的单词及其概率。假设 LLM 只知道 5 个单词(LLM 词汇表通常包含数千个单词)。
计算温度为 1.0 和 100.0 的概率
index=[0,1,2,3,4]words=[ceiling,floor,mat,car,grass]logits=[−49.82,−46.40,−45.25,−47.30,−48.32]温度:1.0


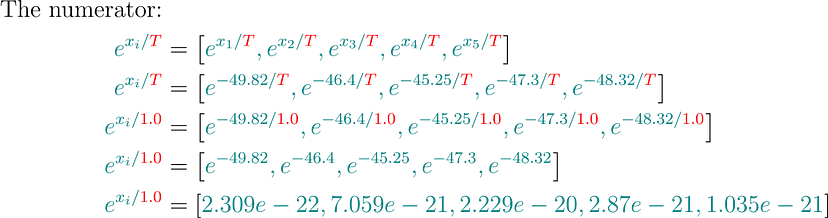

合并所有:

使用 Python:
# Example Softmax Calculation
# Assume for simplicity:
# * The model only knows the 5 words listed below (it has a vocabulary of 5).
import pandas as pd
import seaborn as sns
#Example model output
model_output_vals = {"word_index":[i for i in range(5)],
"words":["ceiling", "floor", "mat", "car", "grass"],
"logits":[-49.82, -46.40, -45.25, -47.30, -48.32]}
temp = 1.0
#Convert the data to a DataFrame
model_output = pd.DataFrame(model_output_vals)
#Define a softmax function with temperature
def my_softmax(input_vector, Temp=1.0):
e = np.exp(np.divide(input_vector,Temp))
return e / e.sum()
#Calculate the probabilities
probs = my_softmax(model_output["logits"], Temp=temp)
model_output["softmax_prob"] = probs
#Select the most probable word
most_prob = np.argmax(probs)
print(f"\nThe index of the most probable word is: {most_prob}")
#Pull out the most probable word
print(f"\nThe most probable word is: { model_output['words'][most_prob] }" \
f" (Prob: {model_output['softmax_prob'][most_prob]:.5f})")
#Style our table
cm = sns.light_palette("orange", as_cmap=True)
s1 = model_output
s1 = s1.style.background_gradient(subset=["logits"],cmap=cm)
cm = sns.light_palette("green", as_cmap=True)
s1.background_gradient(subset=["softmax_prob"],cmap=cm)The index of the most probable word is: 2
The most probable word is: mat (Prob: 0.66571)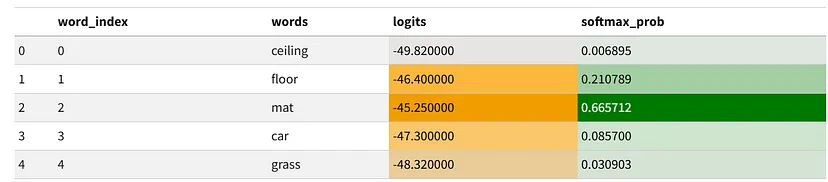

从 softmax 概率中,我们可以看出最可能单词为:mat,概率为:0.666
温度:100.0
手动:
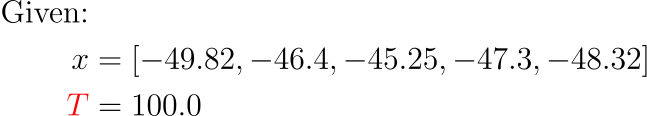

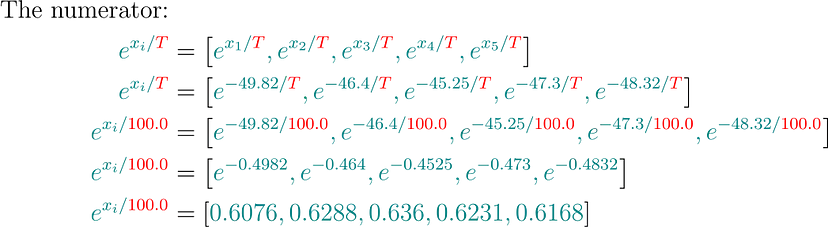

合并所有:

使用 Python:
# Example Softmax Calculation
# Assume for simplicity:
# * The model only knows the 5 words listed below (it has a vocabulary of 5).
import pandas as pd
import seaborn as sns
#Example model output
model_output_vals = {"word_index":[i for i in range(5)],
"words":["ceiling", "floor", "mat", "car", "grass"],
"logits":[-49.82, -46.40, -45.25, -47.30, -48.32]}
temp = 100.0
#Convert the data to a DataFrame
model_output = pd.DataFrame(model_output_vals)
#Define a softmax function with temperature
def my_softmax(input_vector, Temp=1.0):
e = np.exp(np.divide(input_vector,Temp))
return e / e.sum()
#Calculate the probabilities
probs = my_softmax(model_output["logits"], Temp=temp)
model_output["softmax_prob"] = probs
#Select the most probable word
most_prob = np.argmax(probs)
print(f"\nThe index of the most probable word is: {most_prob}")
#Pull out the most probable word
print(f"\nThe most probable word is: { model_output['words'][most_prob] }" \
f" (Prob: {model_output['softmax_prob'][most_prob]:.5f})")
#Style our table
cm = sns.light_palette("orange", as_cmap=True)
s1 = model_output
s1 = s1.style.background_gradient(subset=["logits"],cmap=cm)
cm = sns.light_palette("green", as_cmap=True)
s1.background_gradient(subset=["softmax_prob"],cmap=cm)The index of the most probable word is: 2
The most probable word is: mat (Prob: 0.20436)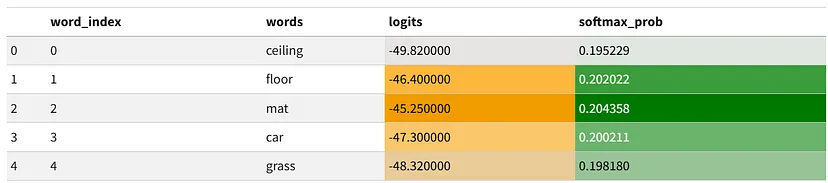
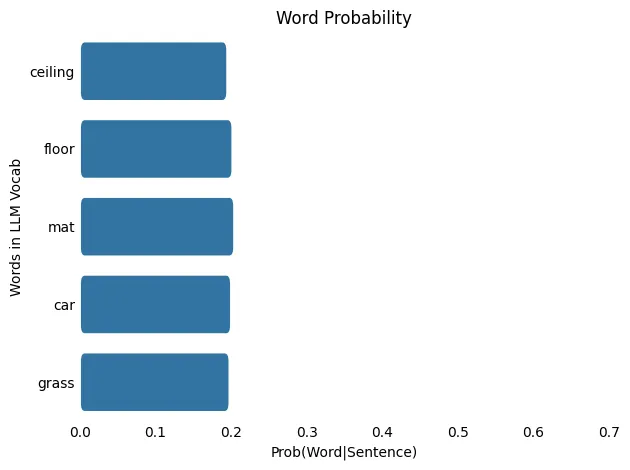
从 softmax 概率中,我们看到最可能的单词是:mat,概率为: 0.204
这是什么意思?
随着温度从 1.0 升至 100.0,概率分布从更集中(或“尖锐”)转变为更分散(或“平坦”),这意味着在较低温度下概率较低的单词被选中的几率更高。
使用贪婪采样,即始终选择概率最高的单词,模型始终选择排名靠前的单词。但是,如果我们修改采样方法,从概率最高的前 3 个单词中随机选择一个单词,则潜在选项将扩展到包括 [‘mat’、‘floor’、‘car’] 等单词。
4、应用温度的 LLM
要了解温度参数如何影响大型语言模型 (LLM) 的输出,我们将使用 GPT-2,这是由 OpenAI 开发的开源文本生成模型。GPT-2 可通过 Hugging Face 等平台获得,并以中等规模的模型而闻名。
GPT-2 具有以下特点:
- 1.24 亿个参数:这些是模型的可学习权重,可帮助模型根据输入数据进行预测。
- 50,257 个词汇量:模型的词汇量由一组标记(使用字节对编码的单词或子单词)组成,GPT-2 经过训练可以识别和生成这些标记。
- 768 维向量嵌入大小:这是指用于编码每个标记的密集向量表示的大小。
- 12 个注意力头:这些是每个转换器层中使用的并行注意力机制,用于捕获输入序列关系的不同方面。
- 12 个层:该模型有 12 个转换器层,可让模型处理和理解数据中更复杂的模式。
我们将研究使用 LLM 完成两种类型的任务:
- 单个下一个单词生成:根据给定输入的上下文预测下一个单词。
- 连续生成下一个单词:生成一系列单词,其中每个新单词都是根据先前生成的单词进行预测的。
模型设置:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_to_load = "openai-community/gpt2"
model_to_load_task = "text-generation"
# Load the model's pretrained tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_to_load)
# Load the pretrained model
model = AutoModelForCausalLM.from_pretrained(
model_to_load,
device_map = device, #CPU or GPU
torch_dtype = "auto",
trust_remote_code = True
)
To pass inputs to the model we can run the following:
# Input sentence
prompt = "The cat sat on the"
temperature = 0.5
# Tokenize/encode input prompt
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# Generate the output with adjusted temperature
outputs = model.generate(input_ids,
max_new_tokens=1, #Just want one word generated
temperature=temperature, #Set temp
output_scores=True, #Output model word scores
output_logits=True, #Outout logits
return_dict_in_generate=True,
do_sample=True, #Perform sampling for next word
pad_token_id=tokenizer.eos_token_id)
# Get the generated token ID/next word
generated_token_id = outputs.sequences[0][-1].item()
# Decode the generated token ID to a word
generated_word = tokenizer.decode([generated_token_id])4.1 单个下一个单词生成
在单个下一个单词生成中,GPT-2 被赋予一个初始输入序列(例如部分句子)并预测最可能的下一个单词。该模型根据序列中前面的单词提供的上下文做出此预测。
一旦预测出下一个单词,就会输出该单词,并且该过程停止,这意味着一次只生成一个单词。根据模型学习到的关联,根据最高概率选择单词,除非用新输入重复该过程,否则不会发生进一步的预测。
我们将把我们一直在看的同一个句子传递给 LLM,看看它会输出什么。
输入句子: The cat slept on the ______.
prompt = "The cat slept on the"
temps = [0.1, 0.5, 1., 5., 10., 100.]
for ii in temps:
word_out = next_word_prediction(prompt, temp=ii)
print(f"LLM Temperature: {ii} \n {prompt} {word_out}")在这里,我们将相同的输入句子传递给具有不同温度值的 LLM,并查看模型词汇表中选定单词的概率分布。
LLM温度:0.1
输入: The cat slept on the
输出: The cat slept on the floor
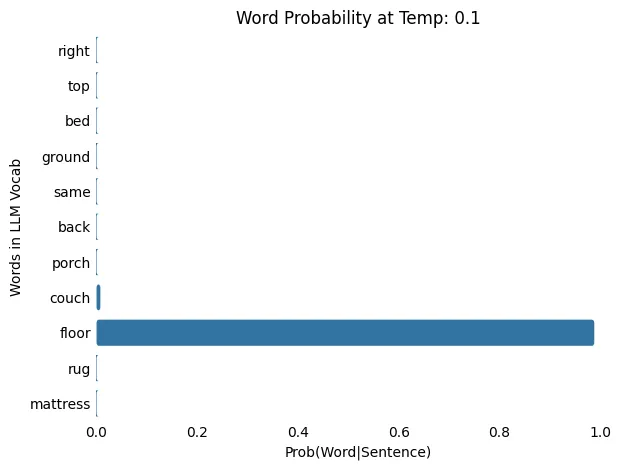
LLM 温度:0.5
输入: The cat slept on the
输出: The cat slept on the bed

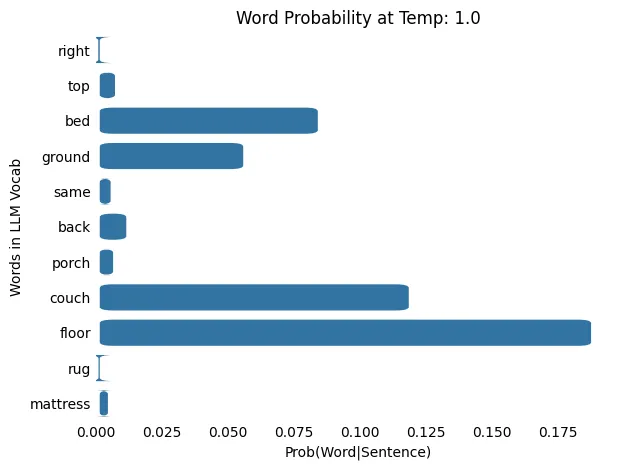
LLM 温度:1.0
输入: The cat slept on the
输出: The cat slept on the back
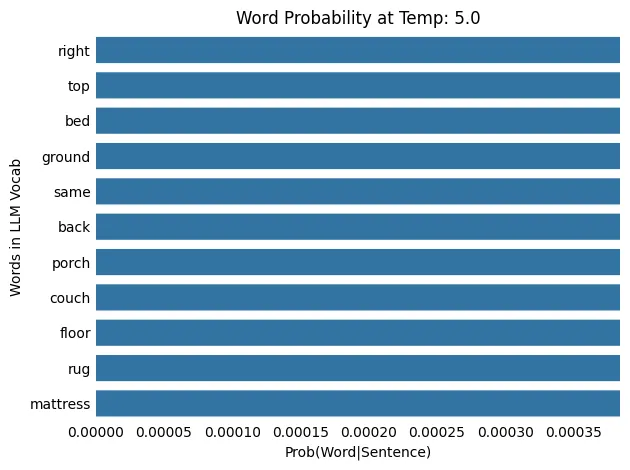
LLM 温度:5.0
输入: The cat slept on the
输出: The cat slept on the bathroom
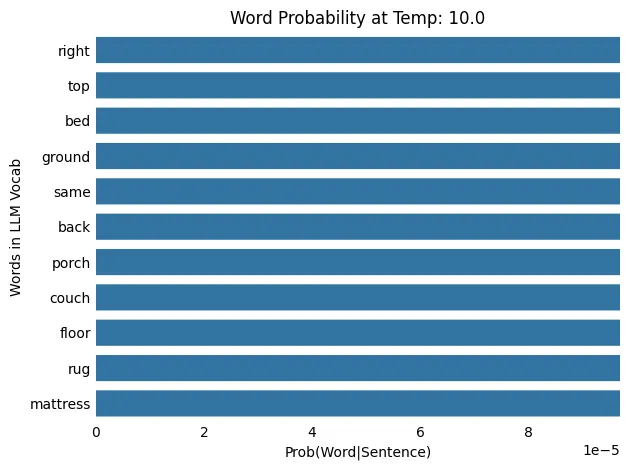
LLM 温度:10.0
输入: The cat slept on the
输出: The cat slept on the corner
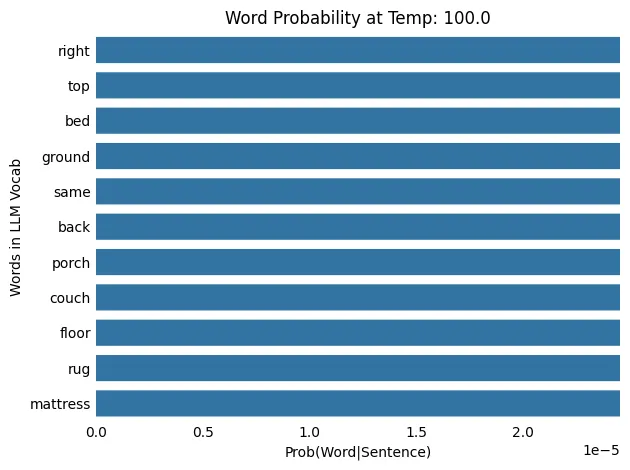
LLM 温度:100.0
输入: The cat slept on the
输出: The cat slept on the inside
这是什么意思?
随着温度从 0.1 升高到 100.0,概率分布从更集中(或“尖锐”)转变为更分散(或“平坦”),这意味着在较低温度下概率较低的单词被选中的机会更高。
4.2 连续的下一个单词生成
在连续的下一个单词生成中,GPT-2 会得到一个初始输入句子,并以自回归方式预测下一个最可能的单词。该模型根据它已经预测的先前单词,使用它已经建立的上下文来生成每个单词。预测下一个单词后,将其添加到句子中,并将更新后的序列传递回模型进行下一次迭代。此过程持续进行,直到满足以下两个条件之一:模型生成序列结束标记(例如 <EOS> 或 \n),或者达到最大迭代次数(或标记)。
我们将把我们一直在研究的同一句话传递给 LLM,看看它在多次迭代后会输出什么,如下所示:
Input sentence: The cat slept on the ______
1: The cat slept on the floor ______
2: The cat slept on the floor next ______
3: The cat slept on the floor next to ______
4: The cat slept on the floor next to the ______
5: The cat slept on the floor next to the window ______
6: The cat slept on the floor next to the window . ______
7: The cat slept on the floor next to the window . < EOS >我们将提示传递给 LLM,并将其预测输出 ( word_out) 附加到提示,并继续迭代,直到达到最大迭代次数 ( max_gen_iteration) 或预测句子结尾标记 ( <EOS>或 \n) :
prompt = "The cat slept on the"
temp = 0.5
max_gen_iteration = 20
for ii in range(max_gen_iteration):
word_out, probs_out = next_word_prediction(prompt, temp=temp)
print(prompt + word_out)
prompt += word_out在这里,我们将相同的输入句子传递给具有不同温度值的 LLM,并查看模型词汇表中选定单词的概率分布。
温度:0.5
参数:
- 输入文本:“The cat slept on the”
- 温度:0.5
- 最大迭代次数:20
prompt = "The cat slept on the"
temp = 0.5
max_iter = 20
gen_next_word_loop(prompt, temp = temp, max_iter = max_iter)
温度:10.0
参数:
- 输入文本:“The cat slept on the”
- 温度:10.0
- 最大迭代次数:20
prompt = "The cat slept on the"
temp = 10.0
max_iter = 20
gen_next_word_loop(prompt, temp = temp, max_iter = max_iter)
这是什么意思?
当比较温度为 0.5 和 10.0 时的输出时,我们观察到在温度为 0.5 时生成的文本更连贯,而在温度为 10.0 时,输出变得越来越不连贯,人类读者也越来越难以理解。
这突出了温度参数如何通过改变模型词汇表中可能的下一个单词的概率分布来影响连续单词的生成。
5、结束语
LLM 中的温度参数控制生成文本的随机性。较低的值会导致更确定和更连贯的输出,而较高的值会增加多样性但可能会降低连贯性。
除了基本应用之外,正在进行的研究还探索了基于输入上下文的动态温度调整,针对多任务学习等特定任务进行优化,控制连贯性和文本长度,并影响情绪基调。
随着未来的进步,我们可以期待看到增强的模型灵活性,从而允许在不同的应用程序中实现更多上下文敏感、自适应和创造性的输出。
原文链接:Why Does My LLM Have A Temperature?
汇智网翻译整理,转载请标明出处
