MarkItDown深入研究
MarkItDown 是 Microsoft 开发的 Python 包,旨在将各种文件格式转换为 Markdown。

MarkItDown 是 Microsoft 开发的 Python 包,旨在将各种文件格式转换为 Markdown。
自首次亮相以来,该库的人气飙升,在短短两周内就获得了超过 25,000 个 GitHub 星!🤯
1、是什么让 MarkItDown 如此受欢迎?
MarkItDown 为各种文件类型提供强大的支持,例如:
- Office 格式:Word、PowerPoint、Excel
- 媒体文件:图像(带有 EXIF 数据和描述)、音频(带有转录支持)
- Web 和数据格式:HTML、JSON、XML、CSV
- 档案:ZIP 文件
它不仅可以处理 Word 等标准格式,还可以处理多模式数据,这使其脱颖而出。例如,它使用 OCR 和语音识别从图像和音频文件中提取内容。
将任何内容转换为 Markdown 的能力使 MarkItDown 成为 LLM 培训的强大工具。通过处理特定领域的文档,它提供了丰富的上下文,以便在 LLM 驱动的应用程序中生成更准确、更相关的响应。
2、MarkItDown 入门
使用 MarkItDown 非常简单 - 只需要 4 行代码:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("test.xlsx")
print(result.text_content)以下是 MarkItDown 的一些用例。
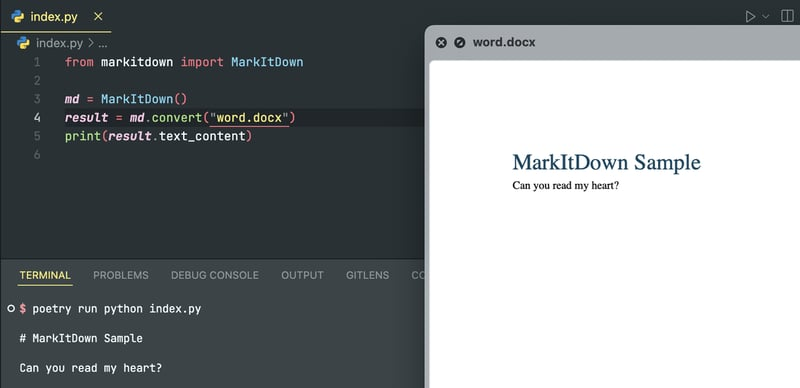
转换 Word 文档可生成干净准确的 Markdown:
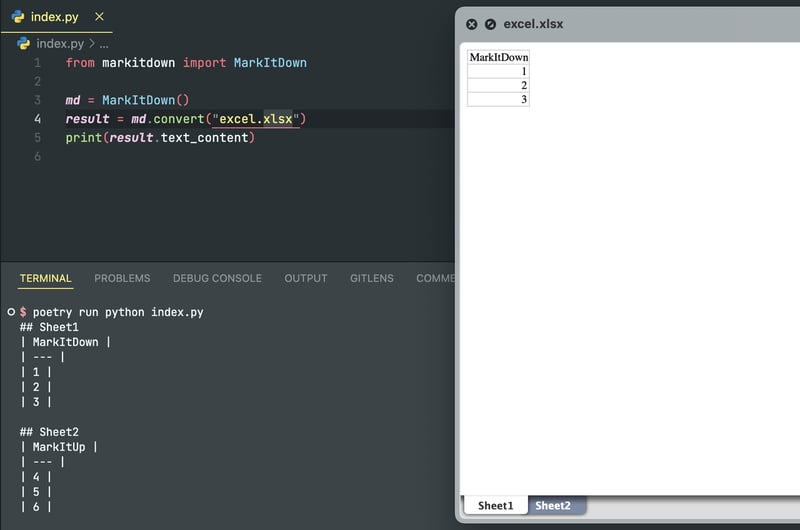
即使是多标签 Excel 电子表格也可以轻松处理:
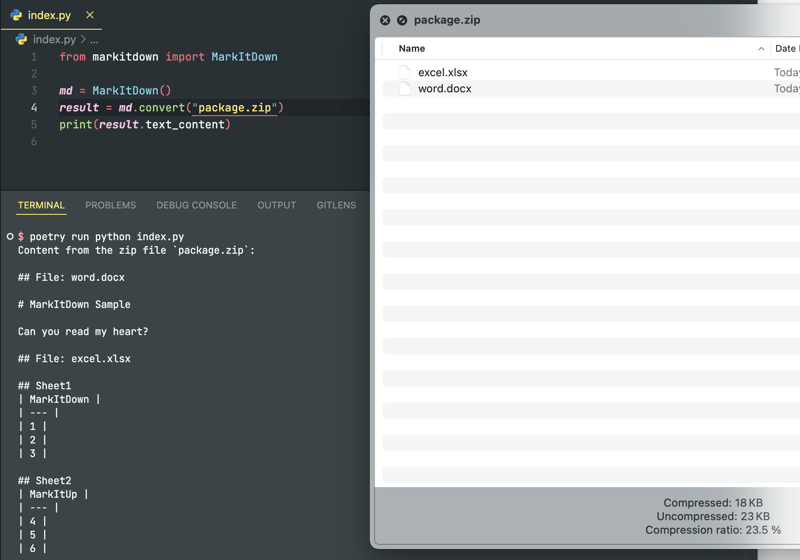
ZIP 存档?没问题!该库会递归解析其中的所有文件:
最初,图像提取可能不会产生任何结果:
这是因为 MarkItDown 依赖 LLM 来生成图像描述。通过集成 LLM 客户端,您可以启用此功能:
from openai import OpenAI
client = OpenAI(api_key="i-am-not-an-api-key")
md = MarkItDown(llm_client=client, llm_model="gpt-4o")配置完成后,可以成功处理图像文件:
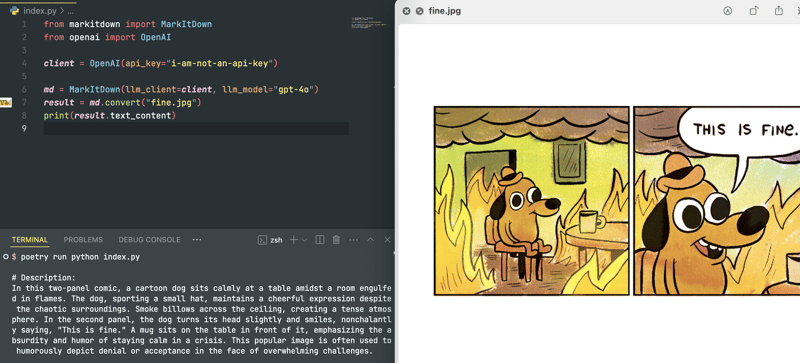
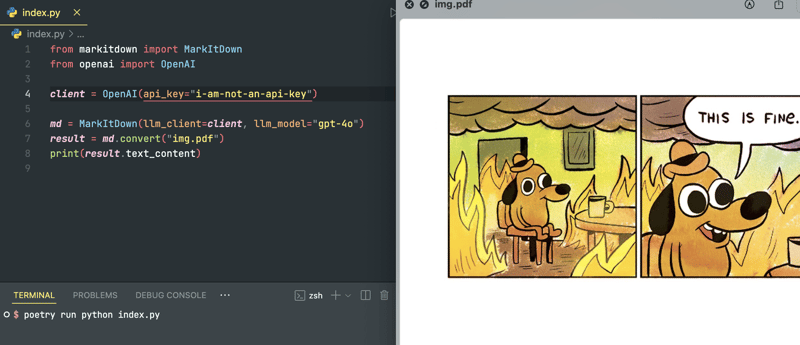
注意:LLM 不会处理基于图像的 PDF。PDF 需要 OCR 预处理才能提取内容。
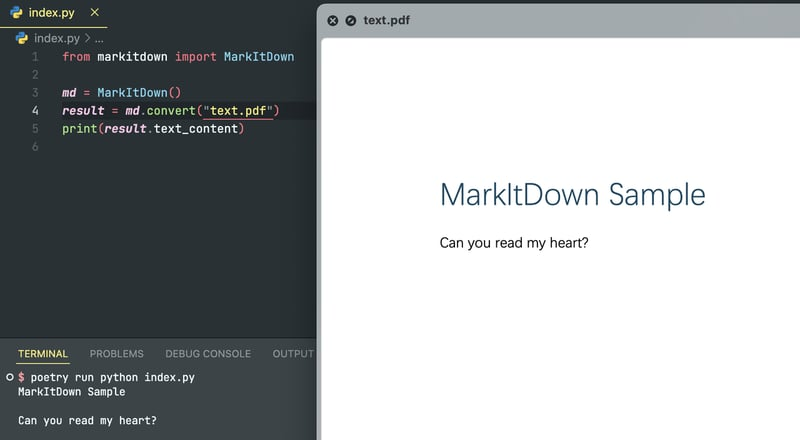
但是,PDF 在提取时会丢失其格式,因此无法区分标题和纯文本:
3、局限性
MarkItDown 并非没有限制:
- 无法处理没有 OCR 的 PDF 文件。
- 从 PDF 文件中提取时无法设置格式。
尽管如此,作为一个开源项目,它具有高度可定制性。由于其代码库简洁,开发人员可以轻松扩展其功能。
4、MarkItDown 的工作原理
MarkItDown 的架构简单且模块化。其核心逻辑完全位于单个文件中。
它有一个 DocumentConverter 类,该类定义了一个通用的 convert() 方法:
class DocumentConverter:
"""Base class for all document converters."""
def convert(
self, local_path: str, **kwargs: Any
) -> Union[None, DocumentConverterResult]:
raise NotImplementedError()各个转换器从此基类继承并动态注册:
self.register_page_converter(PlainTextConverter())
self.register_page_converter(HtmlConverter())
self.register_page_converter(DocxConverter())
self.register_page_converter(XlsxConverter())
self.register_page_converter(Mp3Converter())
self.register_page_converter(ImageConverter())
# ...这种模块化方法可以轻松添加对新文件类型的支持。
5、文件转换工作流程
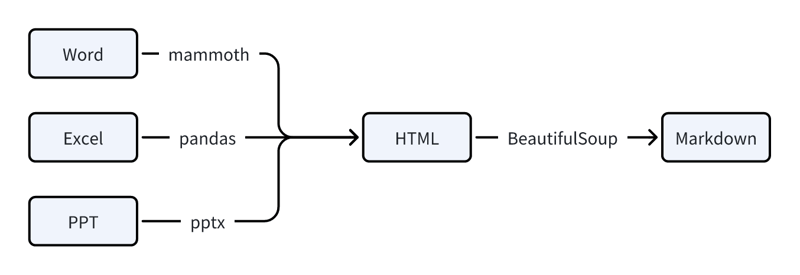
- Office 文档
使用 mammoth、pandas 或 pptx 等库将 Office 文件转换为 HTML,然后使用 BeautifulSoup 转换为 Markdown。
- 音频文件
音频使用 Speech_recognition 库转录,该库利用 Google 的 API。
(微软,为什么不使用 Azure?💔)
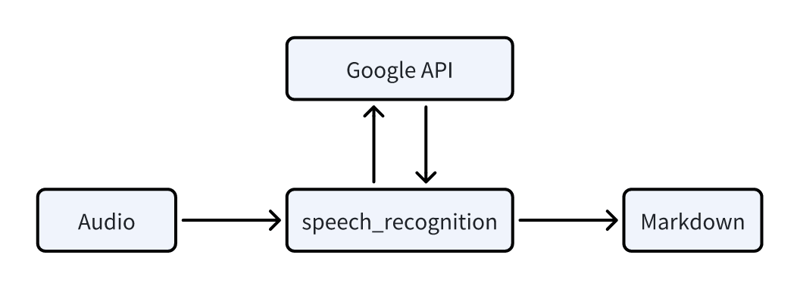
- 图像
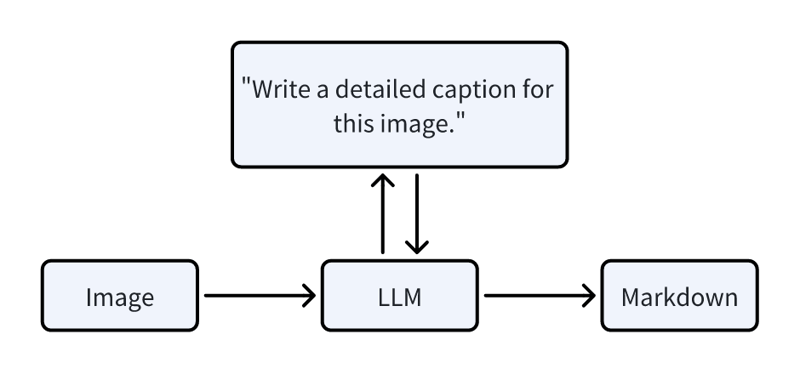
图像处理涉及通过 LLM 提示生成标题:
“为此图像写一个详细描述。”
PDF 由 pdfminer 库处理,但缺少内置 OCR。你必须预处理 PDF 以进行文本提取。

6、将 MarkItDown 部署为 API
MarkItDown 可以在本地运行,但将其作为 API 托管可以解锁额外的灵活性,使其易于集成到 Zapier 和 n8n 等工作流程中。
以下是使用 FastAPI 的 MarkItDown API 的简单示例:
import shutil
from markitdown import MarkItDown
from fastapi import FastAPI, UploadFile
from uuid import uuid4
md = MarkItDown()
app = FastAPI()
@app.post("/convert")
async def convert_markdown(file: UploadFile):
unique_id = uuid4()
temp_dir = f"./temp/{unique_id}"
shutil.os.makedirs(temp_dir, exist_ok=True)
file_path = f"{temp_dir}/{file.filename}"
with open(file_path, "wb") as f:
shutil.copyfileobj(file.file, f)
result = md.convert(file_path)
content = result.text_content
shutil.rmtree(temp_dir)
return {"result": content}要调用API:
const formData = new FormData();
formData.append('file', file);
const response = await fetch('http://localhost:8000/convert', {
method: 'POST',
body: formData,
});7、免费托管 API
托管 Python API 可能很棘手。传统服务(如 AWS EC2 或 DigitalOcean)需要租用整台服务器,这总是很昂贵。
但现在,你可以使用 Leapcell。
这是一个可以以无服务器方式托管 Python 代码库的平台 - 它只按 API 调用收费,并提供慷慨的免费使用套餐。
只需连接你的 GitHub 存储库,定义构建和启动命令,一切就绪:
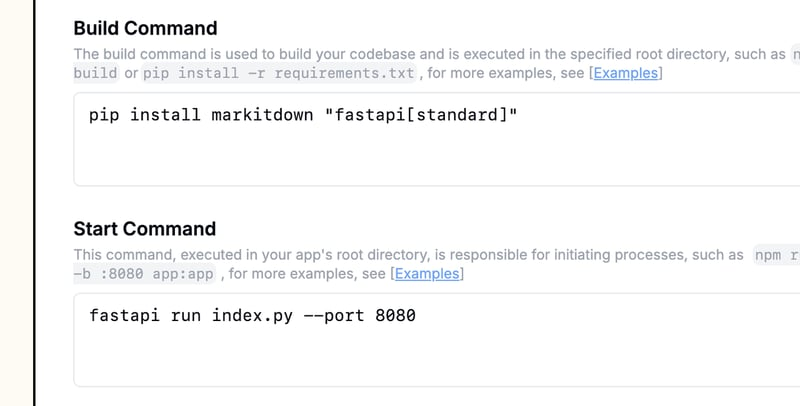
现在你有一个托管在云中的 MarkItDown API,可以集成到你的工作流程中,最重要的是,只有在真正调用时才收费。
原文链接:Deep Dive into Microsoft MarkItDown
汇智网翻译整理,转载请标明出处
