MatFormer:一次训练,多次部署
Gemma 3n 的秘密武器,让一个模型适应所有场景。

在本文中,我们将尝试揭开 MatFormer 的神秘面纱,这是许多 LLM 用来更好地扩展模型的构建块之一。
1、背景
现代 LLM,包括 GPT-5、DeepSeek-V3 和 Gemini 1.5 都非常庞大,通常拥有数百亿个参数。这种现象背后的原因是规模定律(Scaling Law),它基本上表明更多的参数会导致更好的性能。然而,追求更大的模型带来了许多实际挑战,在现实世界的应用中:
- 增长的训练成本:训练一个拥有数百亿参数的完整模型是极其昂贵的。事实上,即使微调这样的模型也可能超出许多没有大规模计算资源的实践者的承受范围。实际上,许多组织只能负担得起微调最多 7B 参数的模型,这使得开发更大的模型变得不那么实用。
- 服务效率:推理成本大致与模型大小成正比,与训练不同,推理会持续且大规模发生。这使得服务更大的模型更加具有挑战性和昂贵。
- 模型选择:不同的任务和延迟要求往往需要不同大小的模型。然而,为每个场景训练单独的模型需要浪费大量时间和计算资源。
为了缓解这些挑战,已经探索了不同的方法。在下面的章节中,我们将简要回顾两种方法,即模型压缩 [1] 技术(包括知识蒸馏、剪枝、量化和低秩分解)以及专家混合(MoE)。我们还将讨论这些方法中的缺失环节。
1.1 知识蒸馏
知识蒸馏(Knowledge Distillation)的概念最初由 Geoffrey Hinton 在他的论文“从神经网络中提炼知识”[4] 中提出。它提出了一个新的学习范式,通过模仿一个更大模型(教师模型)的行为来训练一个小模型(学生模型)。
典型的知识蒸馏工作流程包括以下步骤:
- 在硬标签上训练一个大的教师模型。
- 使用教师模型对一个大型未标记数据集进行推理以获得其输出概率,通常称为软目标。
- 使用这些软目标训练一个较小的学生模型。
- 部署学生模型,它轻量级但保留了教师模型的大部分能力(或知识)。
与直接从硬标签学习小模型相比,从软目标蒸馏知识通常能产生更好的性能。这是因为软目标包含了关于教师模型对任务理解的丰富信息。例如,当一张猫的图片也与狗有一些特征时,教师模型可能会预测它是 90% 的猫和 10% 的狗。这种细微的分布揭示了类之间的关系,使学生模型不仅学习教师预测的内容,还学习其泛化方式。因此,学生模型变得更加稳健,并且性能接近教师模型,尽管参数远少于教师模型。
对于有兴趣了解更多知识蒸馏的人,这里有一个 KDD 2022 的动手教程笔记本,它详细介绍了知识蒸馏的主要步骤:知识蒸馏演示。
1.2 剪枝
模型剪枝(Pruning)是一种通过移除冗余或不太重要的权重来减少神经网络的大小和计算成本的技术。主要思想是,训练好的模型中许多参数对最终预测的贡献很小——因此通过移除它们,我们可以使模型更小更快,同时保持性能几乎不变。
剪枝的有效性很大程度上取决于我们如何识别对模型性能贡献最小的权重或结构。大多数方法依赖于基于幅度或梯度的标准 [5],假设绝对值较小的参数,或者其扰动对损失影响最小的参数,携带的信息较少,可以安全地移除。
有两种主要类型的剪枝:
- 非结构化剪枝根据其重要性移除单个权重。这可能导致高度稀疏的权重矩阵和更小的内存占用,但通常需要专门的硬件或库才能获得真正的加速,因为稀疏模式是不规则的。
- 结构化剪枝移除整个组件,如神经元、通道、滤波器、块 [6],甚至层。由于这种剪枝保持了模型的结构规则,它会在标准硬件(GPU、CPU)上实现实际加速,并且通常用于模型部署。
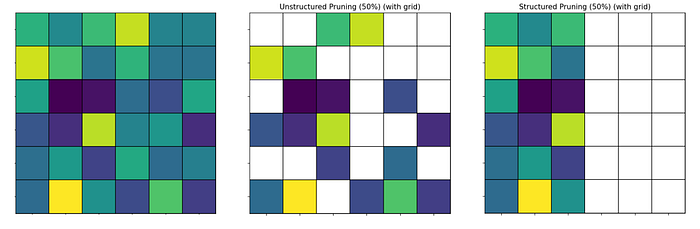
在两种情况下,剪枝之后可以进行微调(类似于蒸馏步骤,将原始模型作为教师)以恢复一些丢失的准确性。
1.3 量化
量化(Quantization)是一种模型压缩技术,通过降低神经网络数字的精度来减少内存使用和计算成本。例如,将 32 位浮点数(FP32)权重和激活转换为更低精度的格式,如 16 位(FP16)、8 位(INT8)甚至 4 位。这减少了内存使用和计算成本,使得推理速度更快,特别是在边缘或移动设备上。
量化算法有三个主要分支:
- 训练后量化(PTQ) —— 在不重新训练的情况下对预训练模型进行量化。它简单且快速,但可能会略微降低准确性,尤其是在低比特(例如 INT4)设置下。PTQ 通常使用校准数据来确定最佳缩放因子。
- 量化感知训练(QAT) —— 在训练过程中模拟量化效果。通过在前向和反向传递中引入假量化操作,模型学习适应量化噪声。QAT 通常比 PTQ 实现更高的准确性,尤其是在较小的比特宽度下。
- 动态量化 / 混合精度量化 —— 根据其敏感性或运行时条件对不同层或张量应用不同的比特宽度。这更灵活地平衡速度和准确性。
量化已成为高效部署大型模型的标准技术,许多现代框架(如 PyTorch 和 TensorRT)支持自动化的流水线。
1.4 低秩分解
低秩分解(LoRA)是一种模型压缩技术,通过将大权重矩阵近似为较小的低秩矩阵的乘积来减少参数数量和计算量。核心思想是,深度网络中许多学习到的权重矩阵在其行和列之间具有冗余的相关性,特别是在全连接和注意力层中,这意味着其真实信息内容位于一个较低维的子空间中。
形式上,一个大小为 m×n 的权重矩阵 W 可以分解为两个较小的矩阵 U(m×r)和 V(r×n),其中 r 远小于 min(m,n)。原来的计算 Wx 被替换为 U(Vx),显著减少了参数和 FLOPs。
这个过程在下面的图中有所说明,其中 10x10 的矩阵被分解为两个低秩矩阵的乘积:U(10x3)和 V(3x10)。正如我们所看到的,这两个矩阵的乘积成功地重建了原始矩阵,捕捉了其关键特征。
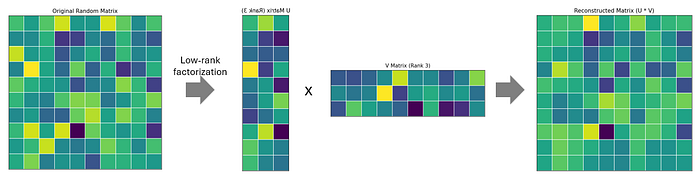
低秩方法可以在训练后(通过 SVD 分解和微调)或训练期间(通过施加低秩约束)应用。它们特别适用于压缩大型语言模型和视觉变压器,并且可以与剪枝或量化结合以进一步提高性能。
然而,主要权衡是激进的秩减少会降低表达能力和准确性,需要仔细选择秩或自适应分解技术。
1.5 专家混合
专家混合(MoE)是一种神经网络架构,旨在扩大模型容量而不成比例地增加计算量。而不是为每个输入激活所有参数,MoE 动态选择一小部分专门的子网络来处理每个示例,这些子网络被称为 专家。
下图显示了一个典型的 MoE 架构,左边显示了一堆 N 个 Transformer 层,每个层都有一个单一的 MHA 子层,然后是一个 FFN 子层。相比之下,右边显示了一堆 N/2 个 Transformer 层,其中较低 Transformer 层的 FFN 子层已被替换为 MoE 层。
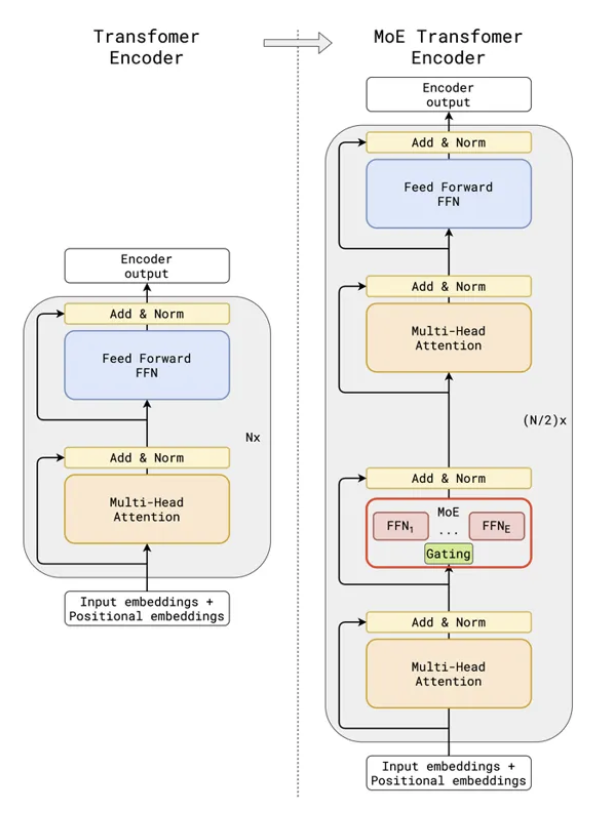
换句话说,每隔一个 Transformer 层的 FFN 子层将被替换为 MoE 层。在实践中,我们可以实现 MoE 来替换指定间隔的 Transformer 层中的 FFN。
MoE 的核心是一个 门控网络,它根据学习到的标准将每个输入路由到一个或几个专家(例如,哪个专家对于给定的标记或特征最相关)。这意味着虽然模型可能包含数十亿个参数,但每次前向传递中只有很小一部分是活跃的,从而实现了 稀疏计算。
这就是为什么我们经常看到带有 MoE 的 LLM 描述它们的模型大小为“XX 总参数,其中 YY 个在每个标记中被激活”,其中 YY 远小于 XX,如 DeepSeek-V3 所示:
“它由 236B 总参数组成,其中每个标记激活 21B。”
这种稀疏性使得 MoE 模型能够在相似的计算成本下实现更高的表示能力。最近的大规模 LLM 利用 MoE 来平衡性能、效率和可扩展性。
然而,MoE 引入了新的挑战,如 负载平衡(确保所有专家都被利用)、路由稳定性以及分布式环境中的 通信开销。高效解决这些问题一直是扩展现代语言模型的研究热点。
对 MoE 感兴趣的读者可以查看我们之前的文章链接 DeepSeek-V3 Explained 2: DeepSeekMoE
1.6 缺失的一环
我们迄今为止涵盖的大多数现有方法都将模型效率视为一种事后考虑。它们从一个大型、完全训练的网络开始,然后对其进行压缩或重新配置以满足部署约束。虽然有效,但这些方法都共享一个根本性的局限性:它们将效率和能力视为独立的优化阶段。
更具体地说:
- 蒸馏将知识从一个大型模型转移到一个小型模型,但需要重新训练,并且常常遭受教师-学生不匹配的问题。
- 剪枝和低秩分解在训练后去除冗余,但可能会损害表示平衡并需要微调。
- 量化通过降低数值精度来加快推理速度,但它不会根据不同的运行时预算调整模型容量。
- MoE通过稀疏性提高计算效率,但仍依赖于专用的路由和独立的专家模块。
在后面的章节中,我们将解释如何将效率直接整合到训练过程中。而不是压缩一个现有的模型,它在同一个 transformer 骨干中共同训练多个粒度,使一个平滑的能力谱成为可能,而无需额外的重新训练或蒸馏。
2、MatFormer
为了更好地理解 MatFormer,我们从 Matryoshka 表示学习 (MRL) 开始,它体现了类似的嵌套结构概念。
2.1 Matryoshka 表示学习 (MRL)
如果“Matryoshka”这个词听起来不熟悉,请想想传统的俄罗斯套娃——一系列逐渐变小的木制人物,每个都正好放在更大的一个里面。

这就是理解 Matryoshka 表示学习 [2] 的关键:它旨在学习一组嵌套的嵌入,其中较小的表示包含在较大的表示中。这种设计允许一个模型只需训练一次,然后通过简单地截断嵌入就可以在多个维度尺度上部署。
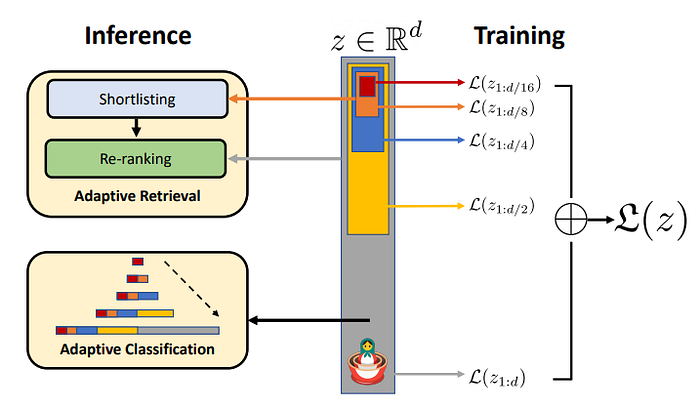
这个概念在上面的图中得到了说明:维度为 d 的完整嵌入位于中心,包围着多个逐步缩小的子嵌入——d/2、d/4、d/8 和 d/16。在训练过程中,每个子嵌入都会生成自己的任务损失,所有这些损失的组合构成了整体的训练目标。换句话说,每个子嵌入都与完整的嵌入一起优化,朝着相同的下游目标,确保跨尺度的一致性。
在推理时,任何子嵌入都可以独立使用,允许从业者通过选择适合特定设备或服务约束的嵌入大小来灵活地权衡准确性、延迟和内存占用。
Matryoshka 表示学习 (MRL) 因此提供了一种优雅的方式来在嵌入空间内直接实现多粒度效率。它是与架构无关的,意味着它可以应用于几乎所有产生嵌入的模型,从语言模型到视觉变压器。它的简单性和适应性使其特别适用于基于检索的应用程序,其中较小的嵌入可以加速近似最近邻 (ANN) 搜索而不牺牲整体模型对齐。
然而,Matryoshka 表示学习 (MRL) 也有一些限制。
首先,它只在表示层面运作——这意味着我们可以截断最终嵌入,但不能截断模型本身。为了生成这些嵌入,我们仍然需要通过整个全尺寸模型进行推理,因此它并没有真正减少推理时的计算成本。
其次,MRL 主要适用于检索或存储密集型应用程序,如搜索和推荐,其中嵌入维度直接影响 ANN 搜索中的内存和延迟。它在生成或序列建模任务中适用性远不如前者,因为在这些任务中,效率需要在整个模型中实现,而不仅仅是输出嵌入。
最后,MRL 依赖于固定的嵌入尺寸层次结构。例如,如果模型在嵌套维度 128 → 256 → 512 上进行训练,它无法平滑地推广到任意截断(比如使用前 100 个维度),因为这些维度在训练期间并未联合优化。
这些限制自然引发了一个更广泛的问题:我们能否将 Matryoshka 原理从表示空间扩展到模型本身?
这个问题引导我们进入 MatFormer,它将嵌套粒度的概念带入了 transformer 的结构设计,使一个模型能够有效地在多个尺度上运行。
2.2 MatFormer 架构
从架构上看,MatFormer 也遵循 Matryoshka 的理念,但它是在一个子网络级别上实现的,而不是在子嵌入级别上。
回想一下,在标准的 Transformer 块中,我们有一个多头注意力(MHA)块,后面跟着一个前馈(FFN)块,如下面的图所示。
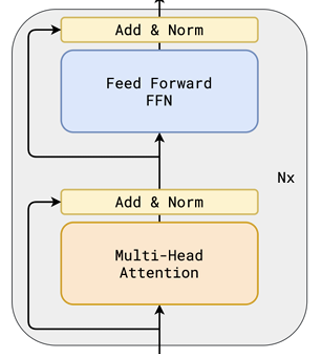
为了将 MRL 的理念从 嵌入级别 扩展到 模型级别,一个自然的方法是在网络中引入嵌套结构,特别是在线性变换中,这些线性变换构成了 MHA 和 FFN 块。
在 MatFormer 论文中,作者通过在两个块中实验嵌套配置来探索这个可能性。然而,他们的最终实现仅将嵌套机制应用于 FFN 块,因为 Transformer 的大部分参数都存在于其中。这种设计选择在架构简洁性和参数效率之间取得了平衡。
一个标准的 FFN 块由两个线性层组成:
- 第一个线性层将隐藏表示从维度 d_model 扩展到 d_ff。
- 第二个线性层将其从 d_ff 投影回 d_model。
通常,d_ff 是 d_model 的几倍,通常是四倍。例如,在 BERT Base 模型中,d_model 是 768,而 d_ff 是 3072。这种扩展-收缩模式使 FFN 块既参数密集又是一个理想的嵌套候选,因为它提供了大量的多粒度优化空间。
为了在这些线性层中启用嵌套结构,MatFormer 只需选择第一个线性层权重矩阵的前 m 行,以及第二个线性层权重矩阵的前 m 列:
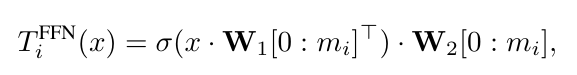
这种设计结果是如下图所示的 MatFormer 块。从概念上讲,它可以被视为一个标准的 Transformer 块,其中原始的 FFN 被一个嵌套的 FFN 结构所取代。在这种表述中,Transformer 块遵循层次关系 T₁ ⊂ T₂ ⊂ … ⊂ T_g,其中 g 表示嵌套 Transformer 粒度级别的总数。每个较小的块完全包含在较大的块中,反映了模型级别的 Matryoshka 式嵌套原则。
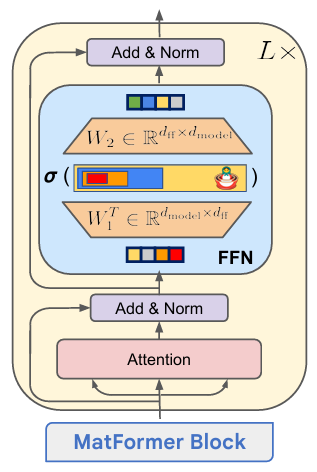
在 MatFormer 论文中,作者将 g 设置为 4,导致四个不同粒度的子模型,分别用标志 {s, M, L, XL} 表示。XL 模型,即原始的 Transformer 模型,被称为通用模型。
在 MatFormer 论文中,作者将 g 设为 4,导致四个不同粒度的子模型,分别用标志 {S, M, L, XL} 表示。XL 模型对应于全规模的 Transformer,也被称为通用模型。
下面的代码脚本展示了 MatFormer 的架构:
class ModifiedLlamaMLP(LlamaMLP):
def __init__(self, config, scale_factors):
super().__init__(
hidden_size=config.hidden_size,
intermediate_size=config.intermediate_size,
hidden_act=config.hidden_act)
self.intermediate_size = config.intermediate_size
self.scale_factors = scale_factors # List of scale factors for 's', 'm', 'l', 'xl'
self.current_subset_hd = None
def configure_subnetwork(self, flag):
"""Configure subnetwork size based on flag."""
hd = self.intermediate_size
if flag == 's':
scale = self.scale_factors[0] # hd/8
elif flag == 'm':
scale = self.scale_factors[1] # hd/4
elif flag == 'l':
scale = self.scale_factors[2] # hd/2
else: # 'xl'
scale = self.scale_factors[3] # hd
self.current_subset_hd = int(hd * scale)
def forward(self, x):
if self.current_subset_hd is None:
raise ValueError("Subnetwork size not configured. Call `configure_subnetwork` first.")
gate_proj = self.gate_proj.weight[:self.current_subset_hd]
up_proj = self.up_proj.weight[:self.current_subset_hd]
down_proj = self.down_proj.weight[:, :self.current_subset_hd]
down_proj = F.linear(self.act_fn(F.linear(x, gate_proj) * F.linear(x, up_proj)), down_proj)
self.current_subset_hd = None
return down_proj
2.3 训练
回想一下,在 Matryoshka 表示学习 (MRL) 中,每个子嵌入都会产生自己的损失,并且这些损失被结合起来形成最终的训练目标。这确保了每个子嵌入在一次训练过程中被联合优化。
然而,直接将这种方法应用于 MatFormer 将在计算上不可行,因为同时优化所有嵌套子网络将需要每次迭代中多次前向和反向传递。
为了解决这个问题,MatFormer 采用了一种更高效的训练策略:在每个训练步骤中,它从 g 个嵌套配置中采样一个子模型结构,并在一次前向-反向传递中仅更新该子模型。
另一个设计问题是——这些子模型应该如何采样? 在他们的实验中,作者使用所有子模型的均匀随机采样,尽管他们指出调整采样概率可以进一步提高个体子模型的强度和平衡。
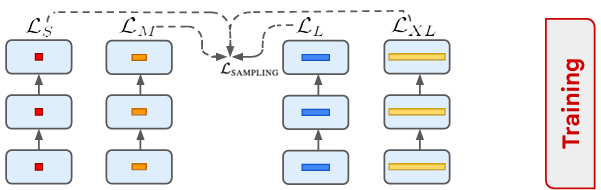
这是如何实现的?
回想一下,在模型架构中,我们引入了一个名为 configure_subnetwork() 的函数,它根据给定的配置标志设置 self.current_subset_hd 的值。
为了在训练期间启用网络采样,对于每个批次执行以下步骤:
- 生成一个对应于子模型配置的随机标志。
- 在每次前向传递之前,使用生成的标志调用
configure_subnetwork()以激活选定的子网络。
下面的代码展示了如何为每个批次生成随机标志:
def collate_fn(batch):
input_ids = torch.stack([torch.tensor(b["input_ids"]) for b in batch])
attention_mask = torch.stack([torch.tensor(b["attention_mask"]) for b in batch])
labels = input_ids.clone()
# Generate a random flag for the entire batch
flag = random.choice(['s', 'm', 'l', 'xl'])
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels, "flag": flag}
这种策略是否需要更多训练轮次? 在我自己的实验中,是的——我们观察到 MatFormer 通常需要更多的训练迭代才能达到与等效大小的标准 Transformer 模型相同的准确率。
2.4 混搭
现在,假设我们使用上述的采样策略训练了一个 MatFormer 模型。此时,我们可以直接选择 g 个预定义的子模型中的任何一个来执行我们的下游任务。
然而,作者进一步采用了称为 混搭 的策略。不是为整个网络选择一个子模型配置,而是让每一层独立选择其粒度。这意味着我们可以通过混合不同容量的层来构建模型——从而得到一个组合爆炸的可能模型变体,源自一个训练好的 MatFormer 骨干。
这种混搭过程在下图中有所说明。
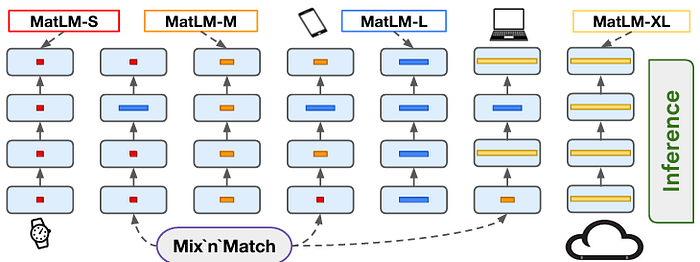
更具体地说,上图说明了七个可部署的模型,它们可以在从智能手表到云服务器的各种设备上运行。其中,只有四种变体是显式训练的:MatLM-S、MatLM-M、MatLM-L 和 MatLM-XL。其余三种是通过 混搭 策略隐式推导出来的,这意味着它们可以直接用于推理而无需任何额外的训练。
这是 MatFormer 的关键创新:你只需训练一次,就能获得一大群子模型 免费。
那么为什么混搭有效呢?
原因在于,MatFormer 中的所有子模型都共享一个共同的分层参数空间,并通过随机子网络采样进行联合训练。每一层都学习在不同容量下保持稳定的表示,使得未见过的粒度组合能够协调运行。经过多次训练迭代,这种随机的协同优化在不同尺度上对齐了特征,产生了平滑的能力谱,即使未训练的层组合也能良好泛化。本质上,MatFormer 学习了一个统一、灵活的架构,可以无缝混合各种大小的层而无需重新训练。
理论上,我们可以以无数种方式构建子模型。对于一个具有 L 层和 g 粒度级别的通用模型,最多可能有 gᴸ 个可能的子模型。然而,在实践中,作者建议选择在层之间平滑变化的配置——确保第 j 层的容量不小于第 i 层的容量(j > i)。这种约束避免了可能破坏中间表示的突然粒度变化。
至于实现,作者没有发布混搭的示例代码,但逻辑很简单:为每层预定义一个比例因子列表,然后逐层应用 configure_subnetwork() 函数,根据选定的粒度切片相应的权重矩阵。
2.5 评估
MatFormer 论文呈现了非常详细的实验结果,涵盖了生成和分类任务,表明它在编码器和解码器模型上都能很好地工作。为了简洁起见,我们不会重复所有的实验和发现。
不过,我想讨论两个我认为有趣的实验:
- MatFormer 是否在训练中引入了不稳定性?是否会损害 Transformer 模型?
- 非显式训练的子模型是否有可预测的性能?或者说,它们是否位于准确率 vs #参数曲线上?
为了回答第一个问题,作者进行了实验,将 MatFormer 与其基线(即标准的 Transformer 模型)进行了比较。如下面的图所示,MatFormer 在验证损失(a)和 1-shot 评估(b)方面实际上优于其基线。
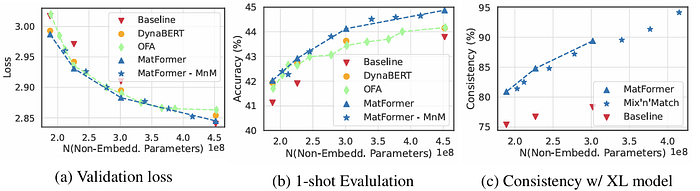
上图还说明了 混搭 的结果,其中子模型由星号图标表示。在两个评估图中,这些子模型与随着模型大小增加的性能曲线紧密对齐,证明它们的准确性随着参数数量的增加而可预测地变化。子图(c)进一步通过测量每个子模型与通用模型的一致性来量化这种关系,显示出更大的子模型表现出更强的对齐,并且行为更类似于完整模型。
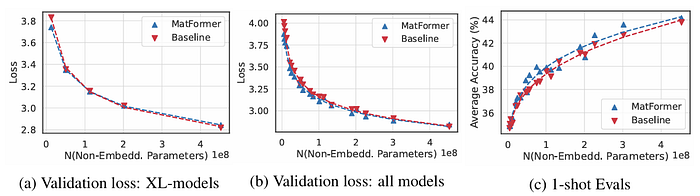
与此同时,下图比较了 MatFormer 和基线 Transformer 的缩放趋势。结果显示,MatFormer 的缩放规律几乎与标准 Transformer 模型相同,证实了其面向效率的设计不会损害基本的缩放行为。
3、结束语
MatFormer 代表了一种与模型压缩技术、MoE 或早期退出截然不同的模型效率新范式:
- 它不是压缩一个训练好的模型,而是在训练过程中将多粒度能力直接烘焙到架构中。这种“一次训练,多次部署”的设计允许一个 MatFormer 模型作为不同大小的多个子模型使用,而无需重新训练或蒸馏。
- 与专家混合(MoE)相比,MatFormer 允许提取适合部署的子模型,并节省了在大型 MoE 模型上做稀疏路由的努力。
总之,MatFormer 通过允许我们根据延迟或设备约束动态调整模型大小,为自适应推理打开了新的可能性。这对于多分辨率训练和联邦或设备端 LLM 部署尤其有用,在这些场景中,较小的子模型可以无缝与通用大型模型共享权重。
原文链接:MatFormer: Train Once and Deploy Many
汇智网翻译整理,转载请标明出处
