Meta MoCha:电影级角色AI
想象一下,AI生成的电影角色不仅会说话,还会像真人演员一样做手势、表达情感并进行对话。有了Meta的MoCha,这样的未来已经到来。

想象一下,AI生成的电影角色不仅会说话,还会像真人演员一样做手势、表达情感并进行对话。有了Meta的MoCha,这样的未来已经到来。
自2024年底以来,生成式领域见证了显著的进步,尤其是在音频、视频和图像生成方面。中国在这方面率先取得了进展,发布了用于视频生成的开源模型,如Hunyuan Video和Wan 2.1。此外,ChatGPT发布的GPT-4o对整个吉卜力世界产生了深远影响。
Meta现在发布了MoCha,这是一个专门用于电影中会说话角色的视频生成模型。
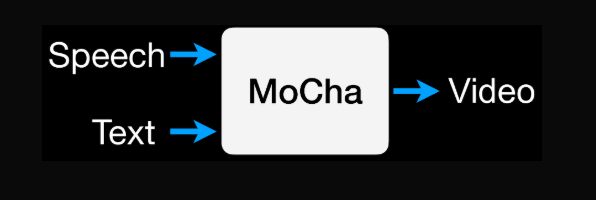
Meta MoCha是由Meta(GenAI)和滑铁卢大学的研究人员开发的先进AI模型,旨在从语音音频和文本提示直接生成电影级会说话角色的视频。
它通过生产全身、富有表现力且上下文一致的角色动画,超越了传统的“会说话头”合成,达到了电影级别的质量。
1、MoCha的主要特点
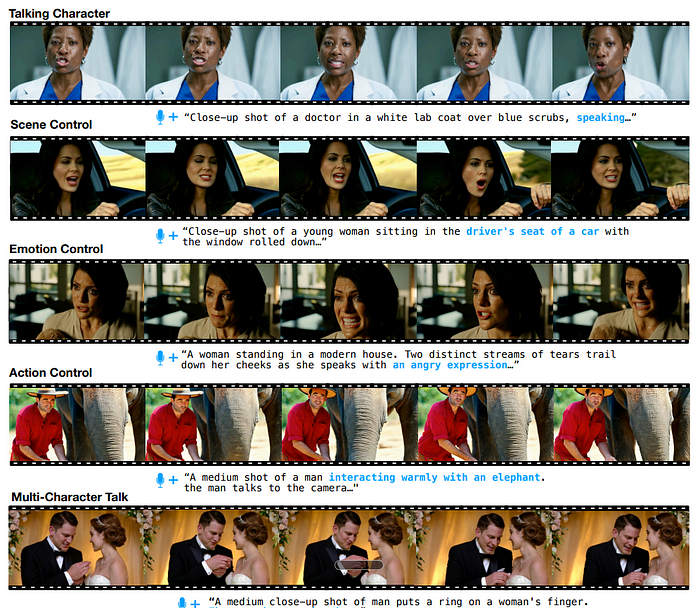
端到端会说话角色生成:
- 生成全身动画,而不仅仅是面部表情,与语音和上下文动作同步。
- 支持各种镜头类型(特写、中景、远景)和角色风格(人类、卡通、动物)。
输入灵活性:
- 文本提示: 定义角色、场景、动作和摄像机构图。
- 语音音频: 驱动唇部动作、面部表情和身体手势。
技术创新:
语音-视频窗口注意力:
- 一种新的注意力机制,将语音标记与视频帧对齐,确保精确的唇同步和自然运动。
联合训练策略:
- 将带有语音标注(ST2V)和仅文本(T2V)的视频数据集成在一起,以提高泛化能力。
多角色对话:
- 第一个支持使用带角色标签的提示进行结构化、轮次对话的模型。
无需辅助条件:
- 与之前的模型(如EMO、Hallo3)不同,MoCha不需要参考图像、骨架或关键点——只需要原始语音和文本。
高质量输出:
- 在720p分辨率下生成128帧视频,每秒24帧(5.3秒片段)。
2、MoCha是如何工作的?
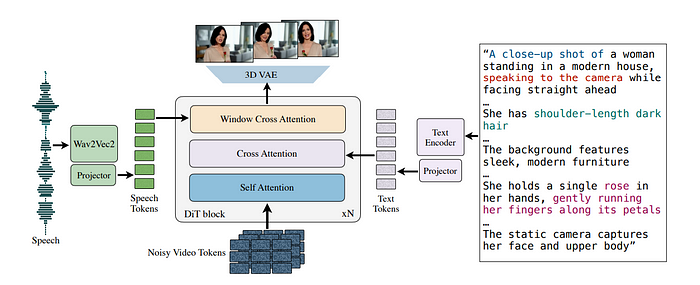
架构:
- 基于扩散Transformer(DiT)主干,处理潜在视频标记。
- 条件视频生成基于**语音嵌入(Wav2Vec2)**和文本通过交叉注意力。
训练:
- 使用流匹配进行高效动力学模拟。
多阶段方法:
从特写镜头开始(强语音相关性)。
逐渐引入更复杂的任务,如全身运动。
评估:
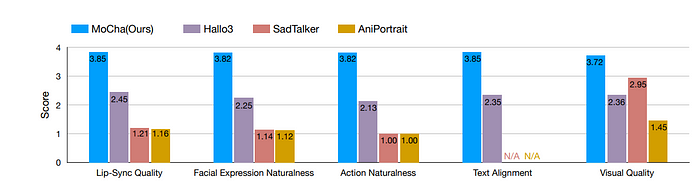
- MoCha-Bench: 一个定制基准,包含150个测试案例。
- 在以下方面优于基线(SadTalker、AniPortrait、Hallo3):
唇同步准确性
面部表情真实性
动作自然性
整体视觉质量(人类评分 ≈ 4/4)
3、为什么MoCha脱颖而出?
MoCha通过:
- 消除了对辅助输入(如参考图像)的依赖。
- 实现了多角色互动——这是该领域的首创。
- 通过先进的对齐和训练策略实现了电影级别的现实感。
- 对近景视频非常友好
4、结束语
MoCha不仅仅是一个AI模型——它是数字电影制作中的游戏规则改变者。通过仅凭语音和文本实现无缝的全身角色动画,Meta重新定义了我们对AI生成内容的看法。无论是电影、虚拟影响者还是互动叙事,MoCha为一个AI驱动的角色与真实演员无法区分的未来铺平了道路。
虽然该模型尚未开源,但其潜力是不可否认的。随着AI的不断发展,像MoCha这样的工具将成为创意行业不可或缺的一部分。在那之前,我们热切期待它的下一个突破——也许是对全世界开放发布?
原文链接:Meta MoCha: AI for Movie-Grade Talking Character
汇智网翻译整理,转载请标明出处
