MiniCPM-V端侧多模态大模型
MiniCPM-V 是一系列高效的 MLLM,旨在在手机和个人电脑等端侧设备上运行,使其成为各种 AI 应用程序的强大工具。
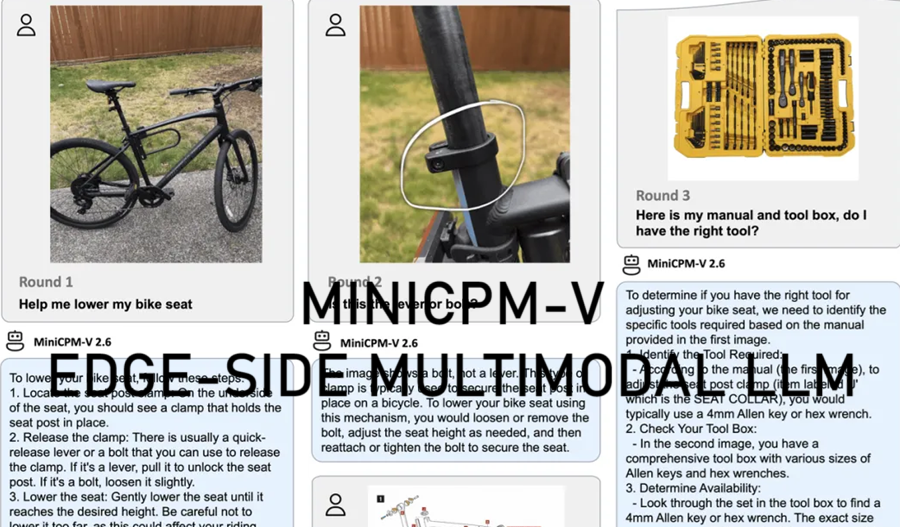
过去几年,多模态大型语言模型 (MLLM) 席卷了 AI 世界,彻底改变了我们理解和与技术互动的方式。然而,这些强大的模型通常需要强大的云服务器,这限制了它们在移动、离线和隐私敏感环境中的使用。
MiniCPM-V 是一系列高效的 MLLM,旨在在手机和个人电脑等端侧设备上运行。该系列的最新型号 MiniCPM-Llama3-V 2.6 实现了 GPT-4V 级别的性能,使其成为各种 AI 应用程序的强大工具。
1、MiniCPM-V模型简介
你知道吗? MiniCPM-V 模型可以部署在移动设备上,无需云服务器即可提供高性能。这使它们成为隐私敏感和离线场景的理想选择。
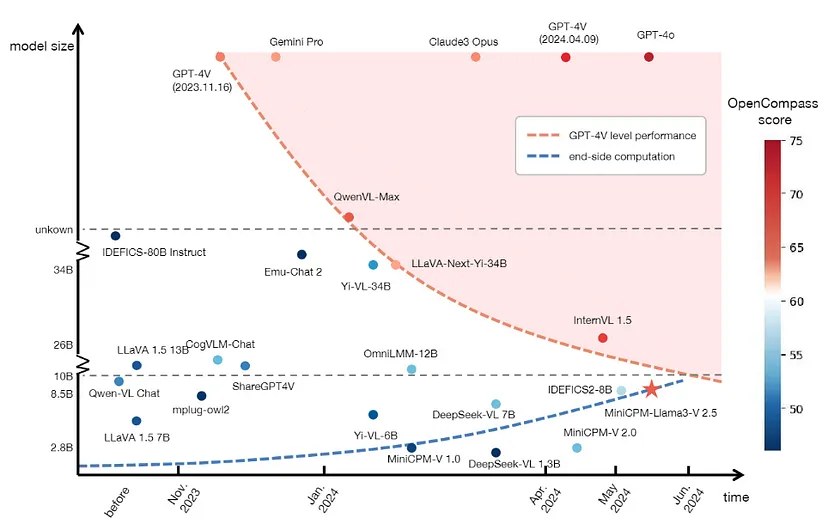
MiniCPM-V的主要特点
- 领先的性能:在多个基准测试中优于其他领先模型,如 GPT-4V-1106 和 Gemini Pro。
- 强大的 OCR 功能:擅长读取图像中的文本、将表格转换为 markdown 等。
- 值得信赖的行为:较低的幻觉率使其更加可靠。
- 多语言支持:支持 30 多种语言,增强了其全球适用性。
- 高效部署:针对移动和端侧设备进行了优化。
1.1 模型架构
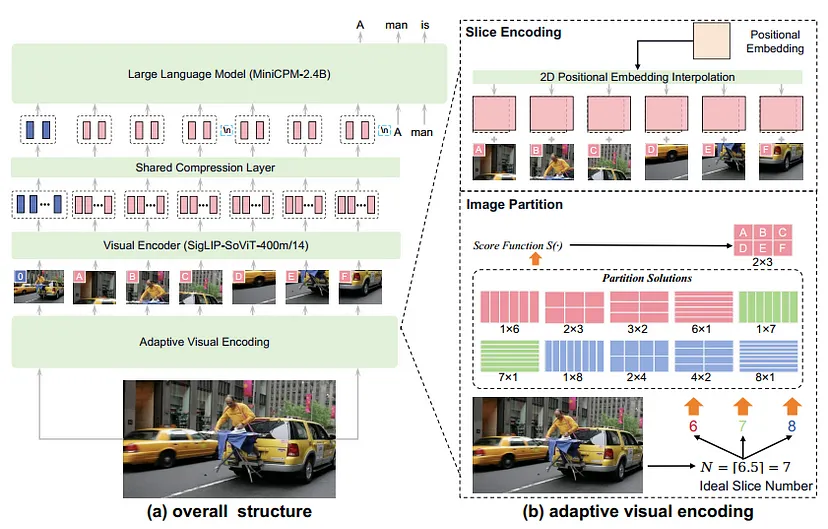
MiniCPM-V 模型由三个主要组件组成:
- 视觉编码器:处理图像并将其转换为视觉标记。
- 压缩层:减少标记数量以实现高效处理。
- 大型语言模型 (LLM):根据视觉和文本输入生成文本。
1.2 训练过程
MiniCPM-V 的训练过程涉及三个阶段:
- 预训练:使用大规模图像-文本对将视觉模块与 LLM 对齐。
- 监督微调 (SFT):使用高质量数据集增强模型的知识和交互能力。
- 带有 AI 反馈的强化学习 (RLAIF-V):减少幻觉并提高响应准确性。
1.3 端侧设备部署
在智能手机等设备上部署 MiniCPM-V 涉及多种优化技术:
- 量化:通过压缩模型权重来减少内存使用量。
- 内存优化:在处理过程中有效管理内存。
- 编译优化:通过在目标设备上编译模型来提高性能。
- 配置优化:动态调整设置以获得最佳性能。
- NPU 加速:利用专用硬件加快处理速度。
这些优化使得在资源有限的设备上运行强大的 AI 模型成为可能,从而开辟了广泛的应用范围。
系好安全带,迎接更多挑战!
2、Gradio聊天应用
让我们从一些令人兴奋的事情开始 — 使用 Gradio 与 MiniCPM-V 聊天。Gradio 提供了一个易于使用的界面来创建基于 Web 的演示。设置方法如下:
import gradio as gr
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# Load model and tokenizer
model_name = "OpenBMB/MiniCPM-Llama3-V-2.5"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Define the chat function
def chat(input_text):
inputs = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(inputs)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Create Gradio interface
iface = gr.Interface(fn=chat, inputs="text", outputs="text", title="Chat with MiniCPM-V")
iface.launch()只需运行上述代码,然后瞧!你可以直接从浏览器与 MiniCPM-V 聊天。
3、 MiniCPM-V安装
在开始使用 MiniCPM-V 之前,我们需要安装它。
首先安装依赖项。确保你已安装 Python 和 pip。然后,安装所需的软件包:
pip install torch transformers gradio然后克隆代码库。从 GitHub 获取最新版本的 MiniCPM-V:
git clone https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V接下来安装模型。导航到项目目录并安装模型:
pip install .4、使用 MiniCPM-V 进行预测
安装 MiniCPM-V 后,你可以开始进行预测。这是一个基本的推理示例:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# Load the model and tokenizer
model_name = "OpenBMB/MiniCPM-Llama3-V-2.5"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Define your input text
input_text = "Translate English to French: Hello, how are you?"
# Encode and generate
inputs = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(inputs)
# Decode and print the result
print(tokenizer.decode(outputs[0], skip_special_tokens=True))运行此代码以查看 MiniCPM-V 的实际操作,将英语翻译成法语。很简洁,对吧?
5、探索可用模型
MiniCPM-V 配备了多种模型,可用于不同的任务。你可以按照以下方法探索模型:
from transformers import AutoTokenizer, AutoModel
model_names = ["OpenBMB/MiniCPM-V-1.0", "OpenBMB/MiniCPM-V-2.0", "OpenBMB/MiniCPM-Llama3-V-2.5"]
for model_name in model_names:
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
print(f"Loaded {model_name} successfully!")6、多轮对话:像专业人士一样聊天
多轮对话使互动更加动态。以下是处理多轮对话的示例:
chat_history = []
def chat(input_text):
global chat_history
inputs = tokenizer.encode(input_text + tokenizer.eos_token, return_tensors="pt")
outputs = model.generate(inputs, max_length=500, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(outputs[:, inputs.shape[-1]:][0], skip_special_tokens=True)
chat_history.append(response)
return response
print(chat("Hello! How are you today?"))
print(chat("Can you tell me a joke?"))7、使用多 GPU 推理加速
利用多个 GPU 来加速推理。方法如下:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import torch
model_name = "OpenBMB/MiniCPM-Llama3-V-2.5"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name).half()
model = torch.nn.DataParallel(model)
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_text = "What is the capital of France?"
inputs = tokenizer.encode(input_text, return_tensors="pt").to("cuda")
outputs = model.module.generate(inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))8、在 Mac 上运行推理
Mac 用户,我们已为你准备好!以下是如何在 Mac 上运行推理:
import torch
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "OpenBMB/MiniCPM-Llama3-V-2.5"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_text = "Explain the theory of relativity in simple terms."
inputs = tokenizer.encode(input_text, return_tensors="pt")
# Use MPS (Metal Performance Shaders) if available
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
model.to(device)
inputs = inputs.to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))9、在手机上部署
在手机上部署 MiniCPM-V 令人兴奋!以下是使用 llama.cpp 的基本设置:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
./main -m models/MiniCPM-Llama3-V-2.5.bin -p "Translate English to Spanish: Good morning!"10、使用 vLLM 进行高级推理
vLLM 提供了一种高效处理推理的高级方法。以下是示例:
from vllm import LLM
llm = LLM(model="OpenBMB/MiniCPM-Llama3-V-2.5")
prompt = "Write a short story about a dragon and a knight."
outputs = llm.generate(prompt, top_p=0.9)
for output in outputs:
print(output["text"])11、MiniCPM-V微调
微调允许你将预训练模型调整为特定任务或数据集,从而提高其性能和与你的应用程序的相关性。使用 MiniCPM-V,你可以针对翻译、摘要、问答等任务微调模型。
在开始之前,请确保你已设置必要的环境。这包括安装 Python 以及必要的库,例如 PyTorch 和 Transformers。
安装所需的软件包:
pip install torch transformers datasets让我们逐步了解微调 MiniCPM-V 的步骤。我们将使用文本分类任务作为示例。
首先加载预训练模型和分词器:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "OpenBMB/MiniCPM-Llama3-V-2.5"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)然后准备微调数据集。我们将使用 datasets库来加载和预处理我们的数据集:
from datasets import load_dataset
dataset = load_dataset("imdb")
train_dataset = dataset["train"].map(lambda e: tokenizer(e["text"], truncation=True, padding="max_length"), batched=True)
test_dataset = dataset["test"].map(lambda e: tokenizer(e["text"], truncation=True, padding="max_length"), batched=True)接下来定义训练参数。仅指定必要的训练参数,例如批次大小、学习率和时期数:
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)创建训练器实例。我们使用 Trainer 类微调模型:
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)开始微调过程:
trainer.train()
评估微调模型。微调后,必须评估模型以确保其符合期望:
results = trainer.evaluate()
print(results)12、多 GPU 微调
为了加快训练速度,可以使用多个 GPU。设置方法如下:
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
fp16=True,
dataloader_num_workers=4,
gradient_accumulation_steps=16,
evaluation_strategy="steps",
save_steps=500,
eval_steps=500,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
data_collator=None,
)原文链接:Unleashing MiniCPM-V: The Future of MLLMs on Your Phone!
汇智网翻译整理,转载请标明出处
