MLOps 初学者指南
在本文中,我将通过端到端项目实施分享一些基本的 MLOps 实践和工具,帮助你更有效地管理机器学习项目,从开发到生产。
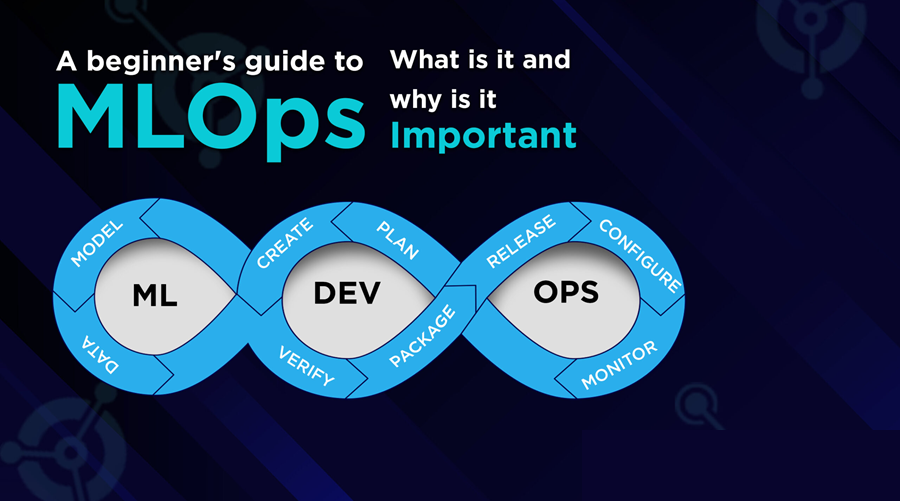
在生产中开发、部署和维护机器学习模型可能具有挑战性和复杂性。这就是机器学习操作 (MLOps) 发挥作用的地方。
MLOps 是一套自动化和简化机器学习 (ML) 工作流和部署的实践。在本文中,我将通过端到端项目实施分享一些基本的 MLOps 实践和工具,帮助你更有效地管理机器学习项目,从开发到生产。
阅读本文后,你将了解:
- 如何使用 DVC 进行数据版本控制。
- 如何使用 MLflow 跟踪日志、工件和注册模型版本。
- 如何使用 FastAPI、Docker 和 AWS ECS 部署模型。
- 如何使用 Evidently AI 监控生产中的模型。
本文中使用的所有代码均可在 GitHub 上找到。
在开始之前,让我们先快速了解什么是 MLOps。
1、什么是 MLOps?
MLOps 是一套旨在简化和自动化机器学习 (ML) 系统生命周期的技术和实践。MLOps 旨在通过为专业人员和研究人员提供明确的指导方针和责任来提高将 ML 模型部署到生产中的效率和可靠性。它弥合了 ML 开发和生产之间的差距,确保可以在现实环境中高效地开发、部署、管理和维护机器学习模型。这种方法有助于减少系统设计错误,从而在现实环境中实现更稳健、更准确的预测。
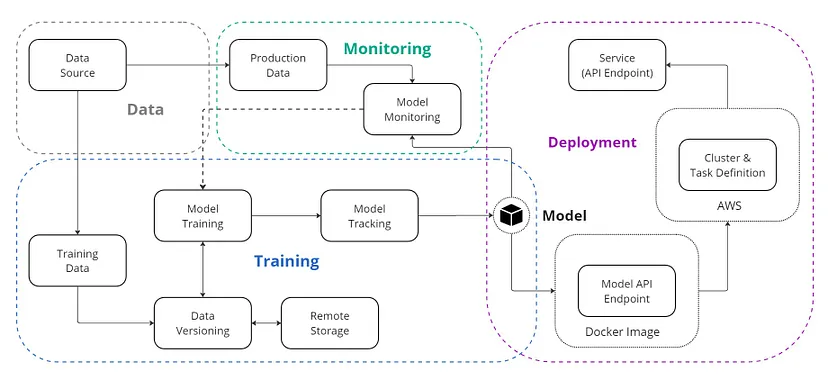
我们为什么需要 MLOps?
通常,任何机器学习项目都从定义业务问题开始。定义问题后,将实施数据提取、数据准备、特征工程和模型训练步骤来开发模型。模型开发完成后,通常会将其存储在某个地方,以便工程和运营团队可以将其部署用于生产。
这种方法有什么问题?
它在开发和部署阶段之间造成了差距,导致效率低下和潜在错误。如果没有数据科学家和工程师之间的协作,模型可能无法针对生产进行优化,这可能导致性能下降、缺乏可扩展性和维护困难等问题。
MLOps 通过创建集成开发和运营的统一工作流程来解决这些问题。它确保模型可靠、可扩展且更易于维护。这种方法降低了出错的风险,加快了部署速度,并通过持续监控使模型保持有效和最新。
现在我们对 MLOps 有了基本的了解,让我们继续实施部分。
2、项目设置
机器学习项目需要标准的项目结构,以确保可以轻松维护和修改它。良好的项目结构使团队成员能够轻松有效地协作。
对于这个项目,我们将使用一个非常基本的结构来帮助我们管理机器学习项目的整个生命周期,包括数据提取、预处理、模型训练、评估、部署和监控。
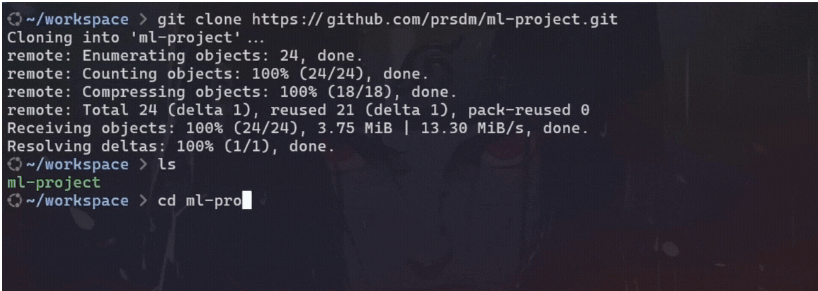
首先,从 GitHub 克隆 mlops-project 存储库并继续操作。
#clone repository from github
git clone https://github.com/prsdm/mlops-project.git克隆存储库后,项目结构将如下所示:
.
├── .github # DVC metadata and configuration
│ └── workflows # GitHub Actions workflows for CI/CD
│ └── docs.yml
├── data # Directory for storing data files
│ ├── train.csv
│ └── test.csv
├── docs # Project documentation.
│ └── index.md
├── models # Store trained models
├── mlruns # Directory for MLflow run logs and artifacts
├── steps # Source code for data processing and model training
│ ├── __init__.py
│ ├── ingest.py
│ ├── clean.py
│ ├── train.py
│ └── predict.py
├── tests # Directory to store tests
│ ├── __init__.py
│ ├── test_ingest.py
│ └── test_clean.py
├── .gitignore # To ignore files that can't commit to Git
├── app.py # FastAPI app file
├── config.yml # Configuration file
├── data.dvc # For tracking data files and their versions
├── dataset.py # Script to download or generate data
├── dockerfile # Dockerfile for containerizing FastAPI
├── LICENSE # License for project
├── main.py # To automate model training
├── Makefile # To store useful commands to make train or make test
├── mkdocs.yml # Configuration file for MkDocs
├── README.md # Project description
├── requirements.txt # Requirements file for reproducing the environment.
├── samples.json # Sample data for testing
'''Extra files for monitoring'''
├── data
│ └──production.csv # data for Monitoring
├── monitor.ipynb # Model Monitoring notebook
├── test_data.html # monitoring results for test data
└── production_data.html # monitoring results for production data以下是结构细分:
- data:存储用于模型训练和评估的数据文件。
- docs:包含项目文档。
- models:存储经过训练的机器学习模型。
- mlruns:包含 MLflow 生成的日志和工件。
- steps:包含用于数据提取、清理和模型训练的源代码。
- tests:包含单元测试以验证代码的功能。
- app.py:包含用于部署模型的 FastAPI 应用程序代码。
- config.yml:用于存储项目参数和路径的配置文件。
- data.dvc:使用 DVC 跟踪数据文件及其版本。
- dataset.py:用于下载或生成数据的脚本。
- dockerfile:用于构建用于容器化 FastAPI 应用程序的 Docker 映像。
- main.py:自动化模型训练过程。
- Makefile:包含用于自动执行训练或测试等任务的命令。
- mkdocs.yml:MkDocs 的配置文件,用于生成项目文档。
- requirements.txt:包含项目所需的所有软件包。
- samples.json:包含用于测试目的的示例数据。
- monitor.ipynb:用于监控模型性能的 Jupyter 笔记本。
- production_data.html 和 test_data.html:存储测试和生产数据的监控结果。
此项目结构旨在组织整个机器学习项目,从开发到监控。
现在,让我们创建一个虚拟环境并使用以下命令激活它:
对于 bash:
#create venv
python3 -m venv venv#activate
source venv/bin/activate对于命令行:
#create venv
python -m venv venv#activate
.\venv\Scripts\activate接下来,使用 requirements.txt 文件安装所有必需的包。
#install all the dependancies
pip install -r requirements.txt示例:
设置好环境并安装依赖项后,我们现在可以继续模型训练部分。
3、模型训练
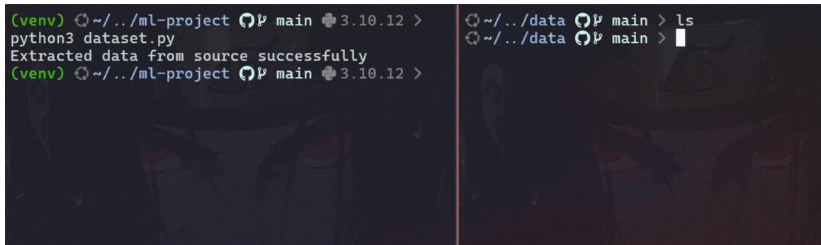
在模型训练中,第一步是从源获取数据,源可以是本地存储或远程存储。为此,请运行 dataset.py 文件。
#to get data from source
python3 dataset.py此脚本从源检索数据,将其拆分为训练和测试数据集,然后将它们存储在 data/ 目录中。
示例:
将数据存储在数据目录中后,接下来的步骤包括清理、处理和模型训练。steps/ 文件夹包含每个阶段的模块。
#model training part from project structure
├── steps/
│ ├── ingest.py
│ ├── clean.py
│ ├── train.py
│ └── predict.py
├── main.py
├── models/model.pkl让我们看看每个文件的作用:
- ingestion.py 处理初始数据提取,确保数据正确加载并可用于下一阶段。
- clean.py 专注于数据清理任务,例如处理缺失值、删除重复项以及进行其他数据质量改进。
- train.py 负责在清理后的数据上训练模型,并将模型保存为 models/ 目录中的 model.pkl。
- predict.py 用于使用训练后的模型评估测试数据上的模型性能。
注意:可以根据项目要求更改或删除这些文件。
要按顺序运行所有这些步骤,请执行 main.py 文件:
#to train the model
python3 main.py本项目中的 main.py 文件如下所示:
import logging
from steps.ingest import Ingestion
from steps.clean import Cleaner
from steps.train import Trainer
from steps.predict import Predictor
# Set up logging
logging.basicConfig(level=logging.INFO,format='%(asctime)s:%(levelname)s:%(message)s')
def main():
# Load data
ingestion = Ingestion()
train, test = ingestion.load_data()
logging.info("Data ingestion completed successfully")
# Clean data
cleaner = Cleaner()
train_data = cleaner.clean_data(train)
test_data = cleaner.clean_data(test)
logging.info("Data cleaning completed successfully")
# Prepare and train model
trainer = Trainer()
X_train, y_train = trainer.feature_target_separator(train_data)
trainer.train_model(X_train, y_train)
trainer.save_model()
logging.info("Model training completed successfully")
# Evaluate model
predictor = Predictor()
X_test, y_test = predictor.feature_target_separator(test_data)
accuracy, class_report, roc_auc_score = predictor.evaluate_model(X_test, y_test)
logging.info("Model evaluation completed successfully")
# Print evaluation results
print("\n============= Model Evaluation Results ==============")
print(f"Model: {trainer.model_name}")
print(f"Accuracy Score: {accuracy:.4f}, ROC AUC Score: {roc_auc_score:.4f}")
print(f"\n{class_report}")
print("=====================================================\n")
if __name__ == "__main__":
main()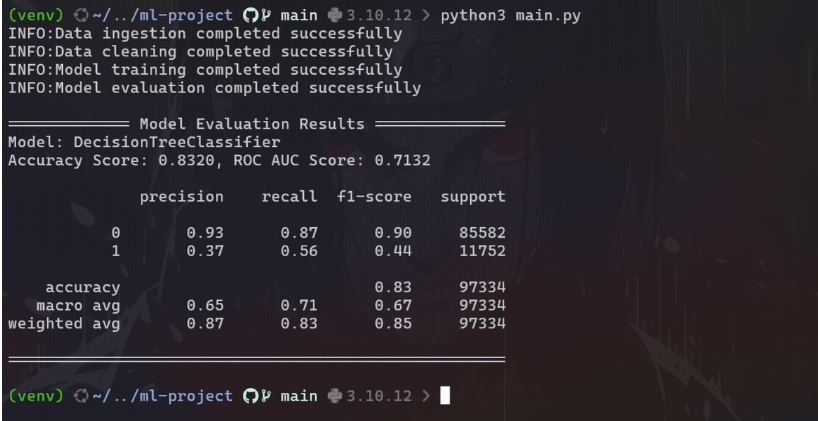
现在,让我们看看如何使用 DVC 和 MLflow 等工具改进这个项目。
4、数据版本控制 (DVC)
让我们从数据版本控制 (DVC) 开始,这是一个免费的开源工具,旨在管理大型数据集、自动化 ML 管道和处理实验。它可以帮助数据科学和机器学习团队更有效地管理数据、确保可重复性并改善协作。
为什么要使用 DVC 而不是 GitHub?
Git 非常适合对源代码和文本文件进行版本控制,但在处理大型二进制文件(如数据集)时存在局限性。Git 不提供二进制文件版本之间的有意义的比较;它只存储新版本而不显示详细差异,这使得跟踪随时间的变化变得具有挑战性。此外,将大型数据集或敏感数据存储在 GitHub 中并不理想,因为它可能导致存储库臃肿和潜在的安全风险。
DVC 通过元数据和外部存储(如 S3、Google Cloud Storage 或 Azure Blob Storage)管理大文件来解决这些问题,同时保持对数据更改和版本历史记录的详细跟踪。 DVC 使用人类可读的元文件来定义数据版本,并与 Git 或任何源代码控制管理 (SCM) 工具集成,以对整个项目(包括数据资产)进行版本控制和共享。此外,它还通过控制对项目组件的访问并与指定团队和个人共享这些组件来提供安全协作。
要开始使用 DVC,请先安装它(如果尚未安装):
#install DVC via pip
pip install dvc然后,初始化 DVC:
#initialize a DVC
dvc init这将设置必要的 DVC 配置文件。
现在,将数据文件添加到 DVC:
#add data
dvc add data这将使用 DVC 跟踪数据文件,并将实际数据存储在外部存储中。
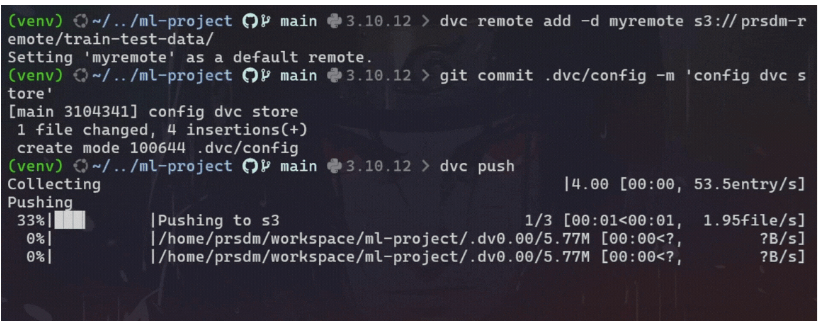
配置远程存储:
#add remote storage configuration
dvc remote add -d <remote_name> <remote_storage_path>将 <remote_name> 替换为远程存储的名称,将 <remote_storage_path> 替换为远程存储的路径(例如,s3://mybucket/mydata)。
将数据推送到远程存储:
#commit the DVC configuration changes to Git
git commit .dvc/config -m 'config dvc store'#upload data to the configured remote storage
dvc push这会将数据上传到配置的远程存储。
将所有已提交的更改推送到 git:
#push all committed changes to the Git repository
git push origin main示例:
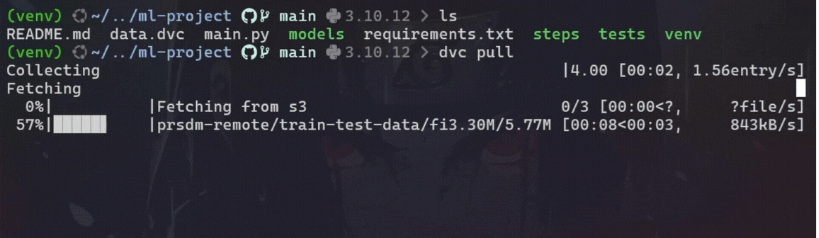
要将最新数据版本从远程存储拉到本地目录,请使用以下命令:
#pull the latest version of the data
dvc pull示例:
通过集成 DVC,我们可以高效地管理大型数据集,同时让 Git 存储库专注于源代码。
注意:我们可以使用 DVC 对模型进行版本控制,就像数据文件一样。
5、MLflow
使用 DVC 对数据进行版本控制后,即使我们没有积极尝试多个模型,也必须保持模型训练、版本更改和参数配置的清晰记录。
如果没有系统跟踪,可能会出现几个问题:
- 版本详细信息丢失:如果不跟踪每个模型版本使用了哪些参数和代码更改,就很难重现或在过去的工作基础上进行构建。这会减慢进度并导致重复犯错。
- 版本比较困难:持续记录每个模型的性能有助于比较不同版本。没有这一点,很难看出模型是否有所改进。
- 协作挑战:在团队中,没有明确的方法来管理模型版本可能会导致混乱和意外覆盖彼此的工作,从而使协作过程复杂化。
这就是 MLflow 的作用所在。MLflow 不仅仅用于实验;它在跟踪 ML 模型的生命周期方面也发挥着关键作用。它记录指标、工件和参数,确保每个版本更改都有记录并易于检索。借助 MLflow,我们可以监控每次运行,并比较不同版本。这样,最有效的模型始终是可识别的,并且可以随时部署。
要集成 MLflow,请先安装 MLflow(如果尚未安装):
#install mlfow
pip install mlflow然后更新 main.py 文件以包含参数、指标和模型的日志记录。代码将如下所示:
import logging
import yaml
import mlflow
import mlflow.sklearn
from steps.ingest import Ingestion
from steps.clean import Cleaner
from steps.train import Trainer
from steps.predict import Predictor
from sklearn.metrics import classification_report
# Set up logging
logging.basicConfig(level=logging.INFO,format='%(asctime)s:%(levelname)s:%(message)s')
def main():
with open('config.yml', 'r') as file:
config = yaml.safe_load(file)
mlflow.set_experiment("Model Training Experiment")
with mlflow.start_run() as run:
# Load data
ingestion = Ingestion()
train, test = ingestion.load_data()
logging.info("Data ingestion completed successfully")
# Clean data
cleaner = Cleaner()
train_data = cleaner.clean_data(train)
test_data = cleaner.clean_data(test)
logging.info("Data cleaning completed successfully")
# Prepare and train model
trainer = Trainer()
X_train, y_train = trainer.feature_target_separator(train_data)
trainer.train_model(X_train, y_train)
trainer.save_model()
logging.info("Model training completed successfully")
# Evaluate model
predictor = Predictor()
X_test, y_test = predictor.feature_target_separator(test_data)
accuracy, class_report, roc_auc_score = predictor.evaluate_model(X_test, y_test)
report = classification_report(y_test, trainer.pipeline.predict(X_test), output_dict=True)
logging.info("Model evaluation completed successfully")
# Tags
mlflow.set_tag('Model developer', 'prsdm')
mlflow.set_tag('preprocessing', 'OneHotEncoder, Standard Scaler, and MinMax Scaler')
# Log metrics
model_params = config['model']['params']
mlflow.log_params(model_params)
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("roc", roc_auc_score)
mlflow.log_metric('precision', report['weighted avg']['precision'])
mlflow.log_metric('recall', report['weighted avg']['recall'])
mlflow.sklearn.log_model(trainer.pipeline, "model")
# Register the model
model_name = "insurance_model"
model_uri = f"runs:/{run.info.run_id}/model"
mlflow.register_model(model_uri, model_name)
logging.info("MLflow tracking completed successfully")
# Print evaluation results
print("\n============= Model Evaluation Results ==============")
print(f"Model: {trainer.model_name}")
print(f"Accuracy Score: {accuracy:.4f}, ROC AUC Score: {roc_auc_score:.4f}")
print(f"\n{class_report}")
print("=====================================================\n")
if __name__ == "__main__":
main()接下来,运行main.py脚本并使用以下命令查看实验详细信息:
#to launch MLflow UI
mlflow ui在浏览器中打开提供的 URL http://127.0.0.1:5000 来探索和比较记录的参数、指标和模型。
示例:
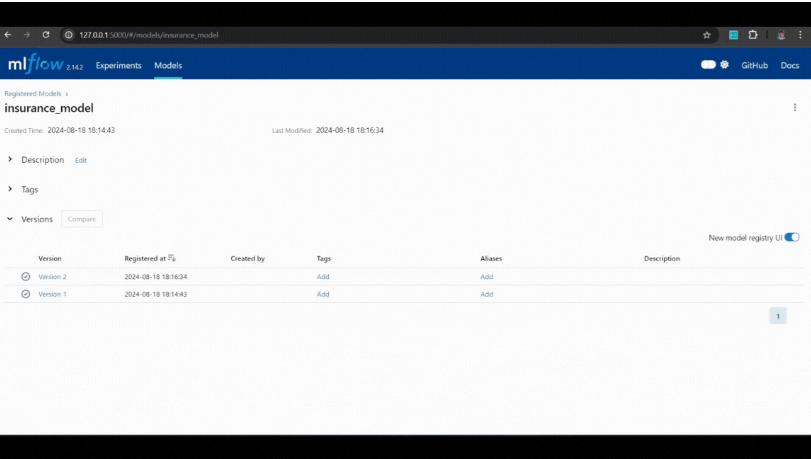
通过使用 MLflow,我们可以轻松跟踪模型版本并管理更改,确保可重复性和选择最有效模型进行部署的能力。
在进入部署部分之前,让我们看一下项目中存在的 Makefile 和 config.yml 文件。这些文件有助于简化工作流程并确保项目设置和配置的一致性。
6、Makefile
使用 make file 对于管理 Python 项目非常有帮助。许多数据科学家和 ML 工程师没有意识到这一点,但 make 可以自动执行日常任务,例如设置环境、安装依赖项、模型训练、运行测试和清理文件,从而节省时间并减少错误。make file 通常用于软件开发,因为它有助于管理难以记住的长而复杂的命令。
该项目中的 make file 如下所示:
bash:
python = venv/bin/python
pip = venv/bin/pip
setup:
python3 -m venv venv
$(python) -m pip install --upgrade pip
$(pip) install -r requirements.txt
run:
$(python) main.py
mlflow:
venv/bin/mlflow ui
test:
$(python) -m pytest
clean:
rm -rf steps/__pycache__
rm -rf __pycache__
rm -rf .pytest_cache
rm -rf tests/__pycache__
remove:
rm -rf venv对于 Windows(cmd),该文件需要稍微修改一下。
python = venv/Scripts/python
pip = venv/Scripts/pip
setup:
python -m venv venv
$(python) -m pip install --upgrade pip
$(pip) install -r requirements.txt
run:
$(python) main.py
mlflow:
venv/Scripts/mlflow ui
test:
$(python) -m pytest
clean:
@if exist steps\__pycache__ (rmdir /s /q steps\__pycache__)
@if exist __pycache__ (rmdir /s /q __pycache__)
@if exist .pytest_cache (rmdir /s /q .pytest_cache)
@if exist tests\__pycache__ (rmdir /s /q tests\__pycache__)
remove:
@if exist venv (rmdir /s /q venv)以下是每个部分的细分:
- make setup:创建虚拟环境 (venv)、升级 pip 并从 requirements.txt 安装所需的软件包。这可确保所有依赖项在不同环境中一致安装。
- make run:使用虚拟环境中的 Python 解释器执行 main.py。
- make mlflow:启动 mlflow ui 以跟踪实验和模型指标。
- make test:此命令使用 pytest 运行项目中定义的所有测试用例。
- make clean:删除缓存文件(例如 pycache、.pytest_cache 和其他临时文件)以保持目录清洁。
- make remove:从项目中完全删除虚拟环境 (venv)。
运行 make file 的示例命令:
# For example, to set up the environment
make setup
# OR To run the main script
make run
# OR To run the tests
make test
# so on...示例:
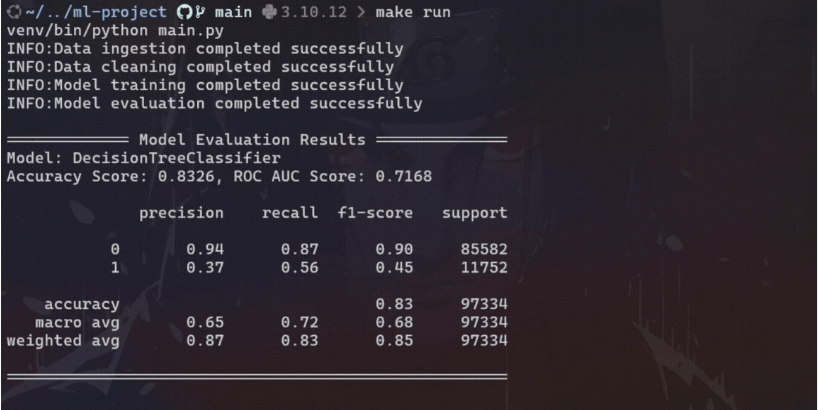
通过使用 make 文件,我们可以自动化和简化各种任务,确保一致性并减少不同环境中的手动错误。
7、Config.yml
YAML 文件是存储和管理机器学习模型配置设置的绝佳方式。它们有助于管理数据/模型路径、模型参数和其他配置,从而更轻松地尝试不同的配置并保持代码可重用性。
Config.yml 文件如下所示:
data:
train_path: data/train.csv
test_path: data/test.csv
train:
test_size: 0.2
random_state: 42
shuffle: true
model:
name: DecisionTreeClassifier
params:
criterion: entropy
max_depth: null
store_path: models/
# name: GradientBoostingClassifier
# params:
# max_depth: null
# n_estimators: 10
# store_path: models/
# name: RandomForestClassifier
# params:
# n_estimators: 50
# max_depth: 10
# random_state: 42
# store_path: models/以下是每个部分的作用:
- data:指定训练、测试和生产(最新)数据集的路径。这可确保数据位置在一个地方进行管理,并且可以轻松更新。
- train:包含将数据拆分为训练集和测试集的参数,例如 test_size、random_state 以及是否对数据进行混洗。这些设置有助于保持一致的数据拆分和可重复性。
- model:定义模型名称、其参数以及存储训练模型的位置。此配置可轻松在不同模型之间切换,从而提供模型选择的灵活性。
使用 config.yml 文件可简化模型参数和路径的管理。它允许轻松试验不同的配置和模型,通过保持参数设置的一致性来提高可重复性,并通过将配置与代码逻辑分开来帮助维护更清晰的代码。
示例:
在以下示例中,根据 config.yml 文件中指定的配置,模型更改为“GradientBoostingClassifier”。

现在,让我们进入部署部分,我们将使用 FastAPI、Docker 和 AWS ECS。此设置将帮助我们创建一个可扩展且易于管理的应用程序,用于提供机器学习模型。
8、FastAPI
FastAPI 是一个使用 Python 构建 API 的现代框架。由于其速度快且简单,它非常适合提供机器学习模型。
首先,安装 FastAPI 和 Uvicorn(如果尚未安装):
#install fastapi and uvicorn
pip install fastapi uvicorn在 app.pyfile 中定义用于提供模型的 FastAPI 应用程序和端点。
from fastapi import FastAPI
from pydantic import BaseModel
import pandas as pd
import joblib
app = FastAPI()
class InputData(BaseModel):
Gender: str
Age: int
HasDrivingLicense: int
RegionID: float
Switch: int
PastAccident: str
AnnualPremium: float
model = joblib.load('models/model.pkl')
@app.get("/")
async def read_root():
return {"health_check": "OK", "model_version": 1}
@app.post("/predict")
async def predict(input_data: InputData):
df = pd.DataFrame([input_data.model_dump().values()],
columns=input_data.model_dump().keys())
pred = model.predict(df)
return {"predicted_class": int(pred[0])}然后,使用以下命令在 http://127.0.0.1:8000/docs 本地测试 FastAPI 服务器:
#run the FastAPI app
uvicorn app:app --reload示例:
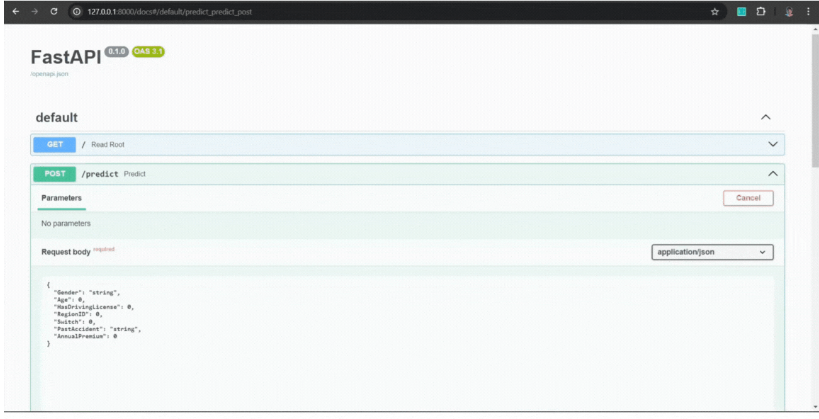
现在让我们使用 Docker 将此 API 容器化。
9、Docker
Docker 是一个开源平台,通过将软件应用程序打包到容器中来简化软件应用程序的部署。这些容器充当轻量级、可移植的单元,其中包含在不同环境中运行应用程序所需的一切。
为什么要使用容器?
容器提供了一种隔离和部署应用程序的简化方法,确保它们在各种环境中一致运行,无论是在开发人员的笔记本电脑上还是在云端。这种隔离增强了可移植性和资源效率,使 docker 成为现代软件开发的重要工具。
要安装 Docker,请按照 Docker 网站上的说明进行操作。
现在,在项目目录中创建一个 Dockerfile 来构建 Docker 映像:
#official Python 3.10 image
FROM python:3.10
#set the working directory
WORKDIR /app
#add app.py and models directory
COPY app.py .
COPY models/ ./models/
# add requirements file
COPY requirements.txt .
# install python libraries
RUN pip install --no-cache-dir -r requirements.txt
# specify default commands
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "80"]现在,使用以下命令构建 Docker 映像:
# To build docker image
docker build -t <image_name> <path_to_dockerfile>示例:
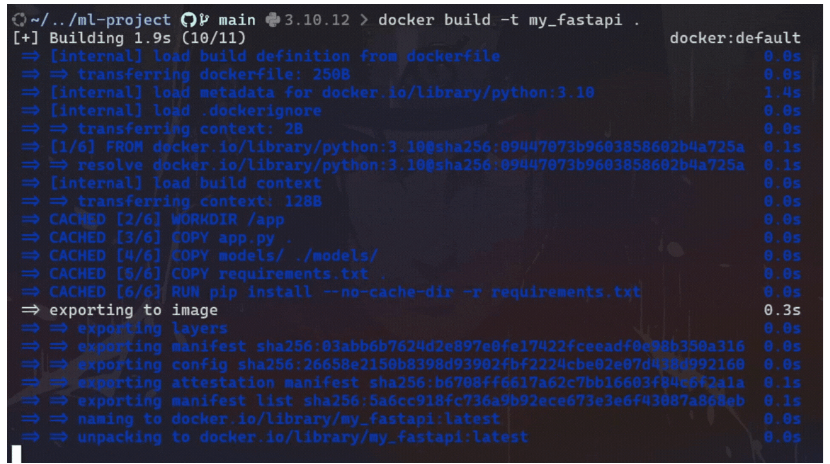
最后,运行 Docker 容器来测试 http://localhost:80/predict 上的 API:
# To run docker container
docker run -d -p 80:80 <image_name>示例:
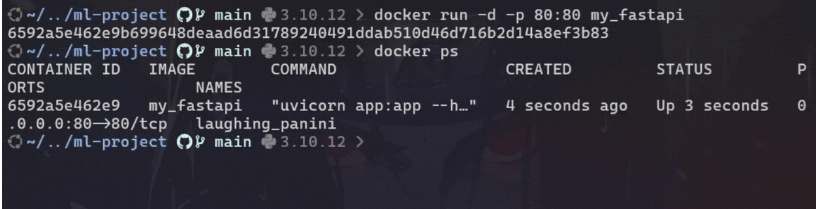
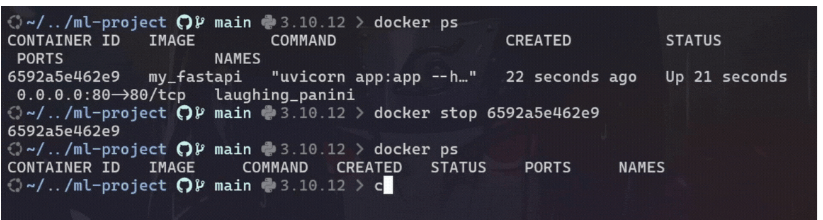
要停止正在运行的 Docker 容器,请使用以下命令找到正在运行的容器的容器 ID 或名称:
# To show running containers
docker ps一旦识别出容器 ID 或名称,就可以使用以下命令将其停止:
# To stop the container
docker stop <container_id_or_name>示例:
现在,要将 Docker 映像推送到 Docker Hub,请按照以下步骤操作:
列出系统上的所有 Docker 映像及其标签,并找到要推送的正确映像:
# List images by name and tag.
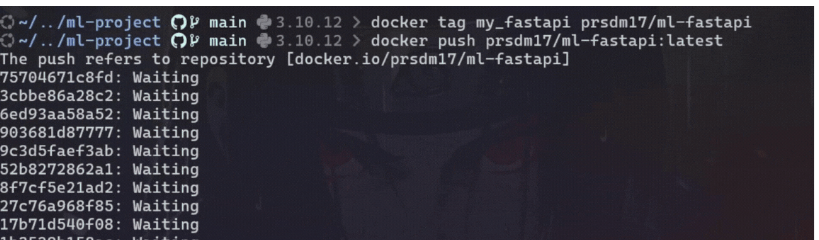
docker image ls使用所需的存储库和名称标记图像:
# Tag the image
docker tag <image_name> <dockerhub_username>/<docker-repo-name>使用以下命令将标记的图像上传到 Docker Hub:
# Push the Docker image
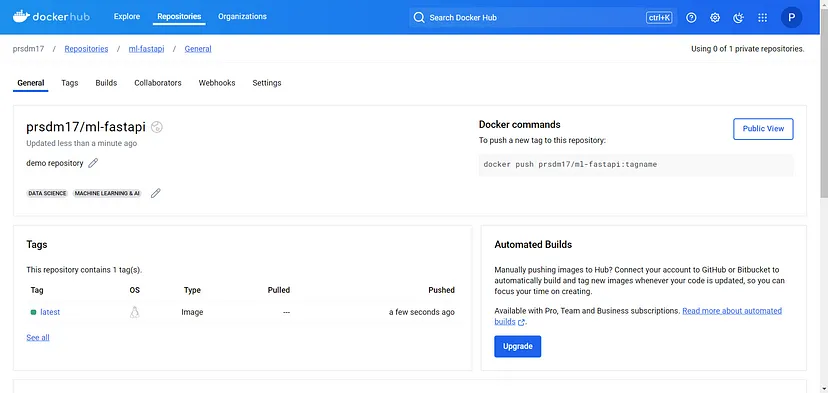
docker push <dockerhub_username>/<docker-repo-name>:latest此命令将把镜像上传到Docker Hub 上的指定存储库。
示例:
现在我们已将 Docker 映像推送到 Docker Hub,我们可以继续将其部署在 AWS Elastic Container Service (ECS) 上。
10、AWS ECS
AWS ECS 是一种完全托管的容器编排服务,允许在 AWS 上轻松运行和扩展 Docker 容器。它支持 EC2 和 Fargate 启动类型。以下是分步指南:
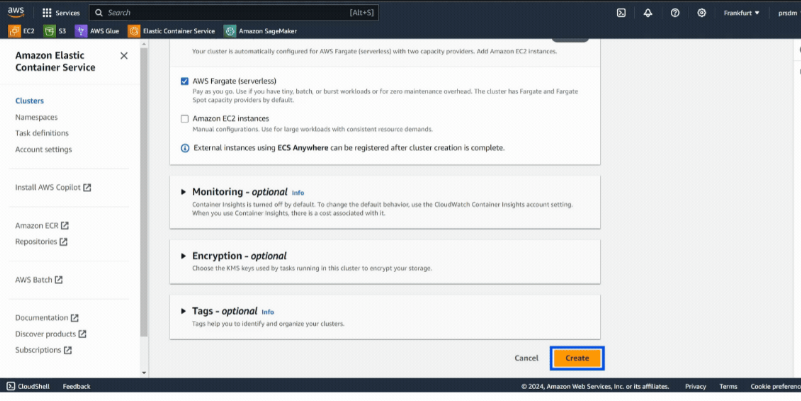
首先,创建一个 ECS 集群:
- 步骤 1:登录 AWS 帐户,然后转到 ECS 服务并选择“创建集群”创建一个新的 ECS 集群。
- 步骤 2:为集群命名,选择 AWS Fargate(无服务器),然后单击“创建”。 (这将需要几分钟。)
然后,定义任务定义:
- 步骤 1:在 ECS 控制台中,转到“任务定义”并创建新的任务定义。
- 步骤 2:为任务命名并配置内存和 CPU 要求等设置。
- 步骤 3:在容器定义中从 Docker Hub 获取 Docker 镜像 URL,并保留容器端口映射的默认值。单击“创建”。
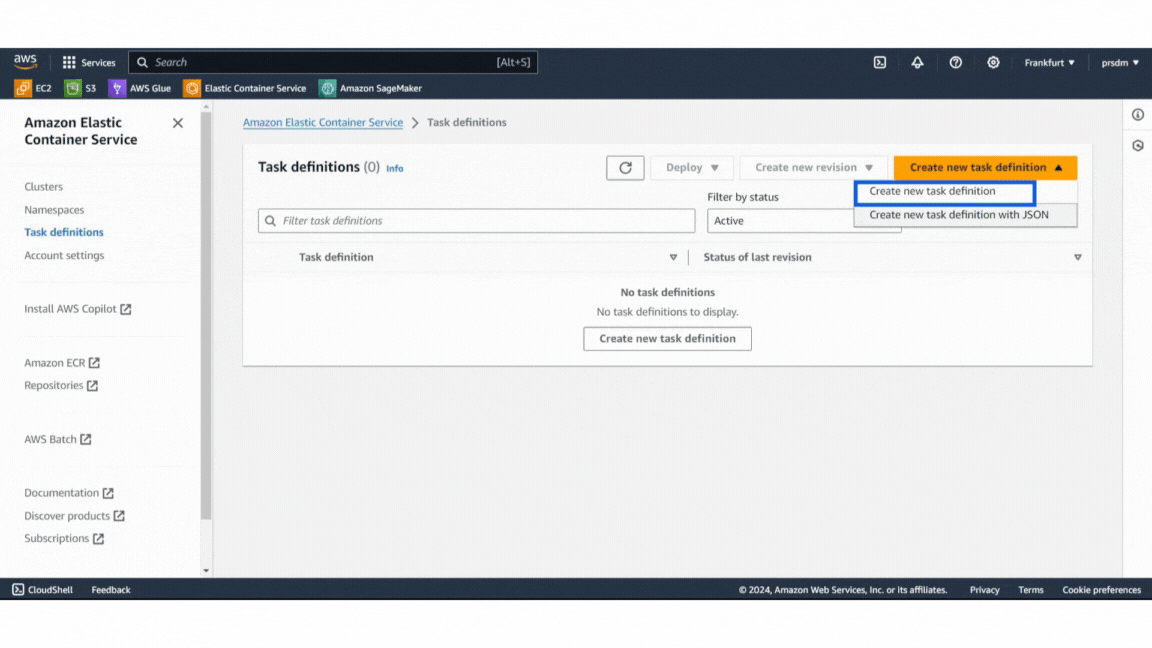
之后,添加安全组:
- 步骤 1:转到 EC2,然后在“网络和安全”中选择“安全组”,然后单击“创建安全组”。为其命名并添加说明。
- 步骤 2:在入站规则中,首先选择 HTTP 类型和来源 Anywhere-IPv4,然后对 Anywhere-IPv6 执行相同操作。单击“创建安全组”。
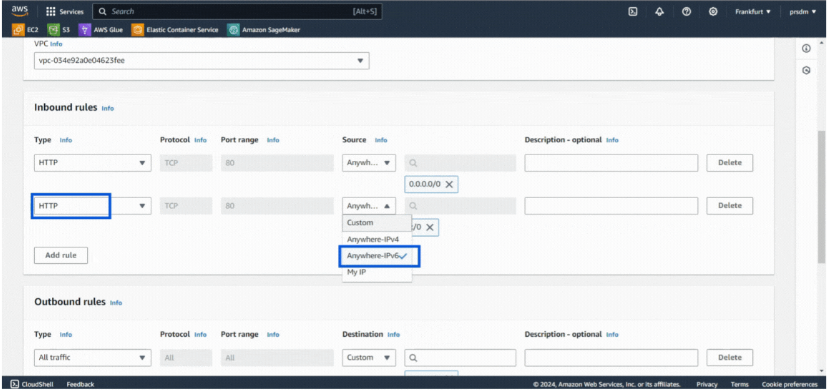
然后,创建一个服务:
- 步骤 1:转到已创建的 ECS 集群并添加新服务。
- 步骤 2:选择“启动类型”计算选项和“Fargate”启动类型。然后选择已创建的任务定义并在部署配置中提供服务名称。
- 步骤 3:最后,选择之前在网络下创建的安全组,然后单击“创建”。(创建服务需要 5-8 分钟。)
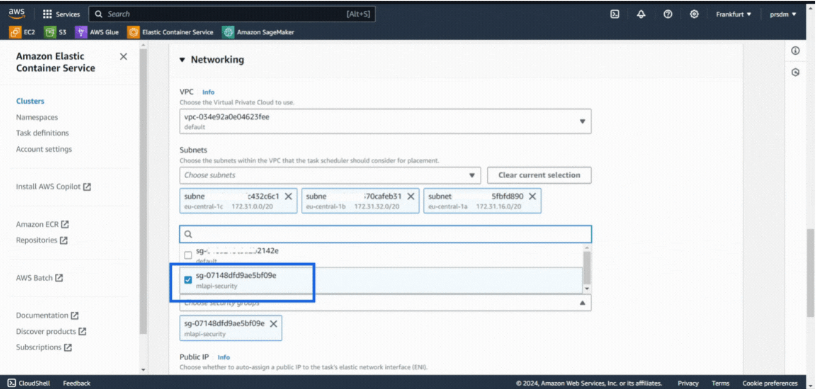
最后,访问正在运行的服务:
部署服务后,转到 ECS 集群的“服务”选项卡。找到服务,转到“任务”选项卡,然后选择一个正在运行的任务。打开任务的公共 IP 地址以访问 FastAPI 应用程序。它看起来会像这样:
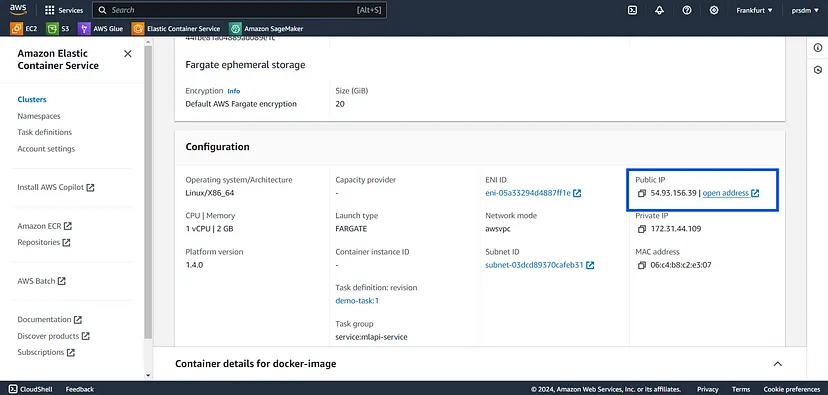
通过遵循以下步骤,我们可以将 FastAPI 应用程序在 Docker 容器中部署到 AWS ECS。这为机器学习模型提供了一个可扩展且易于管理的环境。
注意:如果需要,我们还可以添加 Elastic Load Balancing (ELB)。
成功部署模型后,下一步是在生产中持续监控模型,以确保其在生产数据上表现良好。模型监控涉及评估各种因素,例如服务器指标(例如 CPU 使用率、内存消耗、延迟)、数据质量、数据漂移、目标漂移、概念漂移、性能指标等。
为了让初学者更容易上手,我们将重点介绍使用 Evidently AI 的几种方法,例如数据漂移、目标漂移和数据质量。
11、Evidently AI
Evidently AI 是一种很好的工具,可用于监控模型性能、检测数据漂移和随时间变化的数据质量。它有助于确保模型在新数据进入时保持准确可靠。Evidently AI 提供有关模型性能如何演变的详细见解,并识别数据分布中的任何重大变化,这对于在生产环境中保持模型准确性至关重要。
要安装 Evidently AI,请使用以下命令:
#to install
pip install evidently
#or
pip install evidently @ git+https://github.com/evidentlyai/evidently.git接下来,运行 monitor.ipynb 文件来检测数据质量、数据漂移和目标漂移。该文件如下所示:
# If this .py file doesn't work, then use a notebook to run it.
import joblib
import pandas as pd
from steps.clean import Cleaner
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset, DataQualityPreset, TargetDriftPreset
from evidently import ColumnMapping
import warnings
warnings.filterwarnings("ignore")
# # import mlflow model version 1
# import mlflow
# logged_model = 'runs:/47b6b506fd2849429ee13576aef4a852/model'
# model = mlflow.pyfunc.load_model(logged_model)
# # OR import from models/
model = joblib.load('models/model.pkl')
# Loading data
reference = pd.read_csv("data/train.csv")
current = pd.read_csv("data/test.csv")
production = pd.read_csv("data/production.csv")
# Clean data
cleaner = Cleaner()
reference = cleaner.clean_data(reference)
reference['prediction'] = model.predict(reference.iloc[:, :-1])
current = cleaner.clean_data(current)
current['prediction'] = model.predict(current.iloc[:, :-1])
production = cleaner.clean_data(production)
production['prediction'] = model.predict(production.iloc[:, :-1])
# Apply column mapping
target = 'Result'
prediction = 'prediction'
numerical_features = ['Age', 'AnnualPremium', 'HasDrivingLicense', 'RegionID', 'Switch']
categorical_features = ['Gender','PastAccident']
column_mapping = ColumnMapping()
column_mapping.target = target
column_mapping.prediction = prediction
column_mapping.numerical_features = numerical_features
column_mapping.categorical_features = categorical_features
# Data drift detaction part
data_drift_report = Report(metrics=[
DataDriftPreset(),
DataQualityPreset(),
TargetDriftPreset()
])
data_drift_report.run(reference_data=reference, current_data=current, column_mapping=column_mapping)
data_drift_report
# data_drift_report.json()
data_drift_report.save_html("test_drift.html")定期对传入数据运行监控脚本,以生成有关数据漂移和模型性能的报告。这些报告可以帮助我们确定何时需要重新训练,并确保我们的模型在一段时间内保持准确和可靠。
通过这一步,我们成功完成了 MLOps 项目实施。
12、结束语
在本文中,我们通过一个实践项目介绍了基本的 MLOps 实践和工具。
我们使用 DVC 对数据进行版本控制,使用 MLflow 跟踪和注册模型,并使用 FastAPI、Docker 和 AWS ECR 部署模型。
我们还使用 Evidently AI 设置了模型监控(数据质量、数据漂移和目标漂移)。
这些步骤为使用 MLOps 工具和实践管理机器学习项目(从开发到生产)奠定了坚实的基础。随着你获得这些工具和技术的经验,你可以探索更高级的自动化和编排方法来增强你的 MLOps 工作流程。
原文链接:Machine Learning Operations (MLOps) For Beginners
汇智网翻译整理,转载请标明出处
