商业文档多模态AI搜索
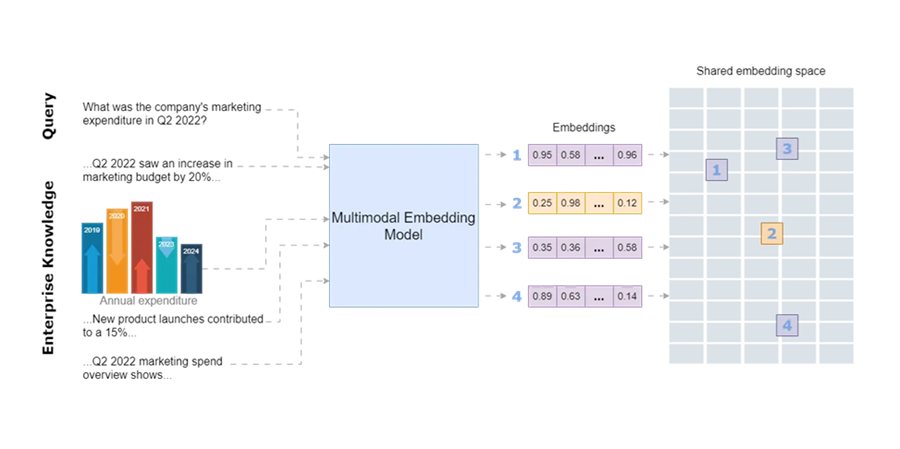
商业文档,例如复杂的报告、产品目录、设计文件、财务报表、技术手册和市场分析报告,通常包含多模态数据(文本以及图形、图表、地图、照片、信息图、图表和蓝图等视觉内容)。从这些文档中找到正确的信息需要对客户或公司员工提出的给定查询的文本和相关图像进行语义搜索。例如,公司的产品可能通过其标题、文本描述和图像来描述。同样,项目提案可能包括文本、说明预算分配的图表、显示地理覆盖范围的地图和过去项目的照片的组合。
准确快速地搜索多模态信息对于提高业务生产力非常重要。业务数据通常以文本和图像格式分布在各种来源中,这使得高效检索所有相关信息变得具有挑战性。虽然生成式 AI 方法(尤其是利用 LLM 的方法)增强了业务中的知识管理(例如,检索增强生成、图形 RAG 等),但它们在访问多模态、分散的数据方面面临限制。统一不同数据类型的方法允许用户使用自然语言提示查询各种格式。此功能可以使公司内的员工和管理层受益,并改善客户体验。它可以有多种用例,例如对相似主题进行聚类并发现主题趋势、构建推荐引擎、让客户参与更相关的内容、更快地访问信息以改进决策、提供特定于用户的搜索结果、增强用户交互以使其感觉更直观和自然,以及减少查找信息所花费的时间,仅举几例。
在现代 AI 模型中,数据被处理为称为嵌入的数值向量。专门的 AI 模型(称为嵌入模型)将数据转换为数值表示,可用于有效地捕获和比较含义或特征的相似性。嵌入对于语义搜索和知识映射非常有用,是当今复杂的 LLM 的基础支柱。
本文探讨了嵌入模型(特别是稍后介绍的多模态嵌入模型)在业务应用程序中增强跨多种数据类型的语义搜索的潜力。本文首先为不熟悉嵌入在 AI 中如何工作的读者解释嵌入的概念。然后,它讨论了多模态嵌入的概念,解释了如何将来自多种数据格式的数据组合成统一的嵌入,以捕获跨模态关系,这对与业务相关的信息搜索任务非常有用。最后,本文探讨了最近引入的多模态嵌入模型,用于业务应用程序的多模态语义搜索。
本教程的完整代码可以从github下载。
1、嵌入空间和语义搜索
嵌入存储在向量空间中,其中相似的概念彼此靠近。将嵌入空间想象成一个图书馆,相关主题的书籍放在一起。例如,在嵌入空间中,“桌子”和“椅子”等单词的嵌入会彼此靠近,而“飞机”和“棒球”会相距较远。这种空间排列使模型能够有效地识别和检索相关项目,并增强了推荐、搜索和聚类等多项任务。
为了演示如何计算和可视化嵌入,让我们创建一些不同概念的类别。完整代码可在 GitHub 上找到:
categories = {
"Fruits": ["Apple", "Banana", "Orange", "Grape", "Mango", "Peach", "Pineapple"],
"Animals": ["Dog", "Cat", "Elephant", "Tiger", "Lion", "Monkey", "Rabbit"],
"Countries": ["Canada", "France", "India", "Japan", "Brazil", "Germany", "Australia"],
"Sports": ["Soccer", "Basketball", "Tennis", "Baseball", "Cricket", "Swimming", "Running"],
"Music Genres": ["Rock", "Jazz", "Classical", "Hip Hop", "Pop", "Blues"],
"Professions": ["Doctor", "Engineer", "Teacher", "Artist", "Chef", "Lawyer", "Pilot"],
"Vehicles": ["Car", "Bicycle", "Motorcycle", "Airplane", "Train", "Boat", "Bus"],
"Furniture": ["Chair", "Table", "Sofa", "Bed", "Desk", "Bookshelf", "Cabinet"],
"Emotions": ["Happiness", "Sadness", "Anger", "Fear", "Surprise", "Disgust", "Calm"],
"Weather": ["Hurricane", "Tornado", "Blizzard", "Heatwave", "Thunderstorm", "Fog"],
"Cooking": ["Grilling", "Boiling", "Frying", "Baking", "Steaming", "Roasting", "Poaching"]
}我现在将使用嵌入模型(Cohere 的 embed-english-v3.0 模型,这是本文的重点,将在本文之后详细讨论示例)来计算这些概念的嵌入,如以下代码片段所示。运行此代码需要安装以下库:
!pip install cohere umap-learn seaborn matplotlib numpy pandas regex altair scikit-learn ipython faiss-cpu下面的代码计算上述概念的文本嵌入并将其存储在 NumPy 数组中:
import cohere
import umap
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Initialize Cohere client
co = cohere.Client(api_key=os.getenv("COHERE_API_KEY_2"))
# Flatten categories and concepts
labels = []
concepts = []
for category, items in categories.items():
labels.extend([category] * len(items))
concepts.extend(items)
# Generate text embeddings for all concepts with corrected input_type
embeddings = co.embed(
texts=concepts,
model="embed-english-v3.0",
input_type="search_document" # Corrected input type for text
).embeddings
# Convert to NumPy array
embeddings = np.array(embeddings)嵌入可以有数百或数千个维度,无法直接可视化。因此,我们降低嵌入的维数,使高维数据可直观解释。计算嵌入后,以下代码使用 UMAP(均匀流形近似和投影)降维方法将嵌入映射到二维空间,以便我们可以绘制和分析相似概念如何聚集在一起:
# Dimensionality reduction using UMAP
reducer = umap.UMAP(n_neighbors=20, random_state=42)
reduced_embeddings = reducer.fit_transform(embeddings)
# Create DataFrame for visualization
df = pd.DataFrame({
"x": reduced_embeddings[:, 0],
"y": reduced_embeddings[:, 1],
"Category": labels,
"Concept": concepts
})
# Plot using Seaborn
plt.figure(figsize=(12, 8))
sns.scatterplot(data=df, x="x", y="y", hue="Category", style="Category", palette="Set2", s=100)
# Add labels to each point
for i in range(df.shape[0]):
plt.text(df["x"][i] + 0.02, df["y"][i] + 0.02, df["Concept"][i], fontsize=9)
plt.legend(loc="lower right")
plt.title("Visualization of Embeddings by Category")
plt.xlabel("UMAP Dimension 1")
plt.ylabel("UMAP Dimension 2")
plt.savefig("C:/Users/h02317/Downloads/embeddings.png",dpi=600)
plt.show()以下是这些概念在 2D 空间中的嵌入可视化:
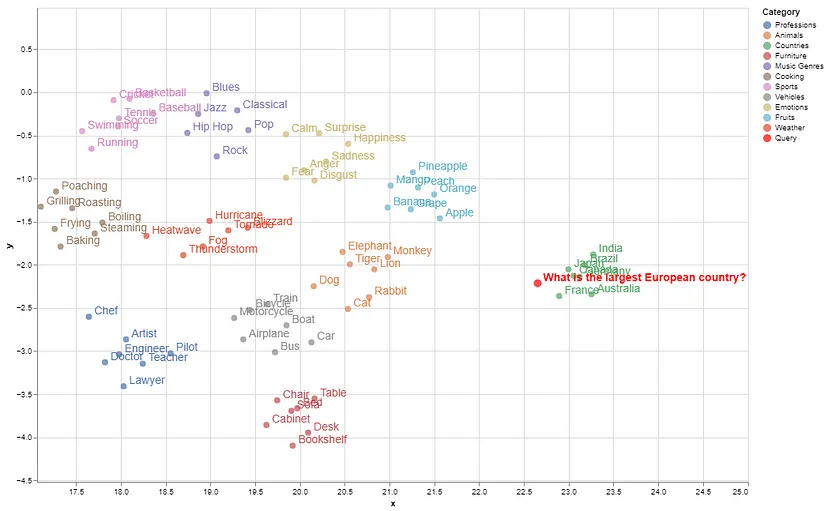
语义相似的项目在嵌入空间中分组,而含义相差较远的概念则位于较远的位置(例如,国家/地区与其他类别的聚集距离较远)。
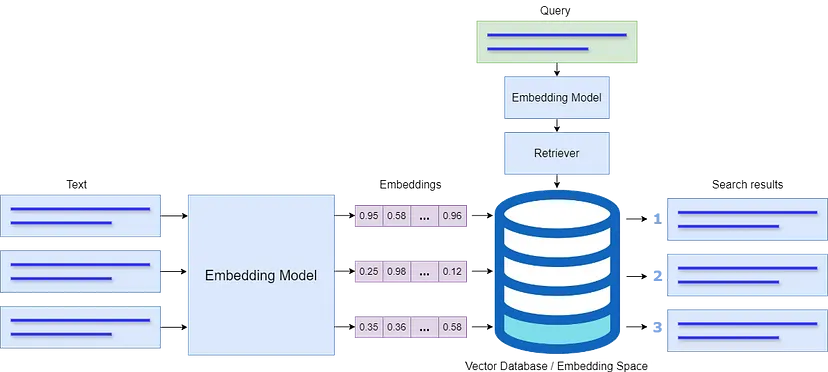
为了说明搜索查询如何映射到该空间中的匹配概念,我们首先将嵌入存储在向量数据库(FAISS 向量存储)中。接下来,我们以相同的方式计算查询的嵌入,并在嵌入空间中识别嵌入与查询语义紧密匹配的“邻域”。此接近度是使用查询嵌入与存储在向量数据库中的嵌入之间的欧几里得距离或余弦相似度来计算的。
import cohere
import numpy as np
import re
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset
import umap
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
import warnings
from IPython.display import display, Markdown
import faiss
import numpy as np
import pandas as pd
from sklearn.preprocessing import normalize
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)
# Normalize embeddings (optional but recommended for cosine similarity)
embeddings = normalize(np.array(embeddings))
# Create FAISS index
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension) # L2 distance, can use IndexFlatIP for inner product (cosine similarity)
index.add(embeddings) # Add embeddings to the FAISS index
# Embed the query
query = "Which is the largest European country?"
query_embedding = co.embed(texts=[query], model="embed-english-v3.0", input_type="search_document").embeddings[0]
query_embedding = normalize(np.array([query_embedding])) # Normalize query embedding
# Search for nearest neighbors
k = 5 # Number of nearest neighbors
distances, indices = index.search(query_embedding, k)
# Format and display results
results = pd.DataFrame({
'texts': [concepts[i] for i in indices[0]],
'distance': distances[0]
})
display(Markdown(f"Query: {query}"))
# Convert DataFrame to markdown format
def print_markdown_results(df):
markdown_text = f"Nearest neighbors:\n\n"
markdown_text += "| Texts | Distance |\n"
markdown_text += "|-------|----------|\n"
for _, row in df.iterrows():
markdown_text += f"| {row['texts']} | {row['distance']:.4f} |\n"
display(Markdown(markdown_text))
# Display results in markdown
print_markdown_results(results)以下是与查询最接近的 5 个匹配项,按它们与存储概念中查询嵌入的最小距离排序:

如图所示,在给定的概念中,France 是此查询的正确匹配。在可视化的嵌入空间中,查询的位置属于“country”组。
下图描述了语义搜索的整个过程:
2、多模态嵌入
文本嵌入已成功用于语义搜索和检索增强生成 (RAG)。为此目的使用了几种嵌入模型,例如来自 OpenAI、Google、Cohere 等的模型。同样,Hugging Face 平台上提供了几种开源模型,例如 all-MiniLM-L6-v2。虽然这些模型对于文本到文本的语义搜索非常有用,但它们无法处理图像数据,而图像数据是商业文档中的重要信息来源。此外,企业通常需要在没有适当元数据的情况下从文档或庞大的图像存储库中快速搜索相关图像。
一些多模态嵌入模型(例如 OpenAI 的 CLIP)部分解决了这个问题,该模型将文本和图像连接起来,可用于识别图像中的各种视觉概念并将它们与名称关联起来。但是,它的文本输入能力非常有限,对于纯文本甚至文本到图像的检索任务,其性能很低。
文本和图像嵌入模型的组合也用于将文本和图像数据聚类到单独的空间中;但是,这会导致偏向纯文本数据的弱搜索结果。在多模态 RAG 中,文本嵌入模型和多模态 LLM 的组合用于从文本和图像中回答问题。有关开发多模态 RAG 的详细信息,请阅读我的这篇文章:将多模态数据集成到大型语言模型中。
多模态嵌入模型应该能够在单个数据库中包含图像和文本数据,与维护两个单独的数据库相比,这将降低复杂性。通过这种方式,模型将优先考虑数据背后的含义,而不是偏向特定模态。
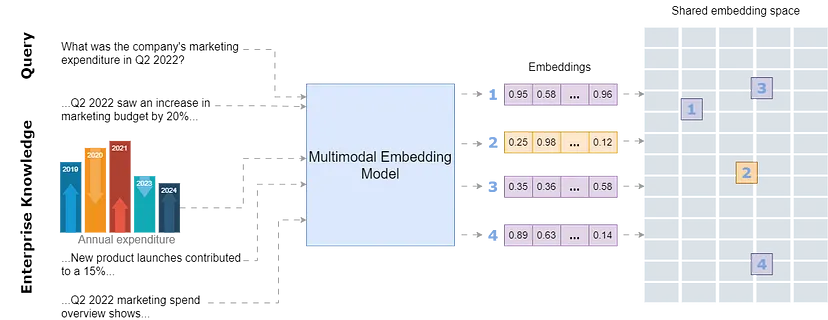
通过将所有模态存储在单个嵌入空间中,该模型将能够将文本与相关图像连接起来,并检索和比较不同格式的信息。这种统一的方法增强了搜索相关性,并允许更直观地探索共享嵌入空间内的互连信息。
3、探索用于业务用例的多模态嵌入模型
Cohere 最近推出了多模态嵌入模型 Embed 3,该模型可以从文本和图像生成嵌入并将其存储在统一的嵌入空间中。根据 Cohere 的博客,该模型在各种多模态任务(例如零样本、文本到图像、图形和图表、电子商务目录和设计文件等)中表现出色。
在本文中,我探索了 Cohere 的文本到图像、文本到文本和图像到图像检索任务的多模态嵌入模型,该模型适用于业务场景,在该场景中,客户使用文本查询或图像从在线产品目录中搜索产品。在在线产品目录中使用文本到图像、文本到文本和图像到图像检索为企业和客户带来了多种优势。这种方法允许客户以灵活的方式搜索产品,无论是通过键入查询还是上传图像。例如,看到自己喜欢的商品的客户可以上传照片,然后模型将从目录中检索外观相似的产品以及有关该产品的所有详细信息。同样,客户可以通过描述产品特征而不是使用确切的产品名称来搜索特定产品。
此用例涉及以下步骤。
- 演示如何使用 LlamaParse 从产品目录中解析多模态数据(文本和图像)。
- 使用 Cohere 的多模态模型 embed-english-v3.0 创建多模态索引。
- 创建多模态检索器并针对给定查询对其进行测试。
- 创建带有提示模板的多模态查询引擎,以查询多模态向量数据库以执行文本到文本和文本到图像任务(组合)
- 从向量数据库中检索相关图像和文本并将其发送到 LLM 以生成最终响应。
- 测试图像到图像检索任务。
我使用 OpenAI 的 DALL-E 图像生成器生成了一个虚构公司的家具目录示例。该目录包含 4 个类别,共 36 张带说明的产品图片。以下是产品目录第一页的快照:

完整代码和示例数据可在 GitHub 上找到。让我们一步一步讨论。
Cohere 的 embedding 模型的使用方式如下:
model_name = "embed-english-v3.0"
api_key = "COHERE_API_KEY"
input_type_embed = "search_document" #for image embeddings, input_type_embed = "image"
# Create a cohere client.
co = cohere.Client(api_key)
text = ['apple','chair','mango']
embeddings = co.embed(texts=list(text),
model=model_name,
input_type=input_type_embed).embeddings可以使用 Cohere 的试用 API 密钥在其网站上创建一个免费帐户来测试该模型。
为了演示如何提取多模态数据,我使用 LlamaParse 从目录中提取产品图像和文本。这个过程在我之前的文章中有详细介绍。可以通过在 Llama Cloud 网站上创建一个帐户来使用 LlamaParse 以获取 API 密钥。免费 API 密钥允许每天 1000 页的信用额度。
需要安装以下库才能运行本文中的代码:
!pip install nest-asyncio python-dotenv llama-parse qdrant-client以下代码从环境文件 (.env) 加载 Llama Cloud、Cohere 和 OpenAI 的 API 密钥。OpenAI 的多模态 LLM GPT-4o 用于生成最终响应。
import os
import time
import nest_asyncio
from typing import List
from dotenv import load_dotenv
from llama_parse import LlamaParse
from llama_index.core.schema import ImageDocument, TextNode
from llama_index.embeddings.cohere import CohereEmbedding
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core import Settings
from llama_index.core.indices import MultiModalVectorStoreIndex
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
import qdrant_client
from llama_index.core import SimpleDirectoryReader
# Load environment variables
load_dotenv()
nest_asyncio.apply()
# Set API keys
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
LLAMA_CLOUD_API_KEY = os.getenv("LLAMA_CLOUD_API_KEY")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")以下代码使用 LlamaParse 从目录中提取文本和图像节点。提取的文本和图像保存到指定路径:
# Extract text nodes
def get_text_nodes(json_list: List[dict]) -> List[TextNode]:
return [TextNode(text=page["text"], metadata={"page": page["page"]}) for page in json_list]
# Extract image nodes
def get_image_nodes(json_objs: List[dict], download_path: str) -> List[ImageDocument]:
image_dicts = parser.get_images(json_objs, download_path=download_path)
return [ImageDocument(image_path=image_dict["path"]) for image_dict in image_dicts]
# Save the text in text nodes to a file
def save_texts_to_file(text_nodes, file_path):
texts = [node.text for node in text_nodes]
all_text = "\n\n".join(texts)
with open(file_path, "w", encoding="utf-8") as file:
file.write(all_text)
# Define file paths
FILE_NAME = "furniture.docx"
IMAGES_DOWNLOAD_PATH = "parsed_data"
# Initialize the LlamaParse parser
parser = LlamaParse(
api_key=LLAMA_CLOUD_API_KEY,
result_type="markdown",
)
# Parse document and extract JSON data
json_objs = parser.get_json_result(FILE_NAME)
json_list = json_objs[0]["pages"]
#get text nodes
text_nodes = get_text_nodes(json_list)
#extract the images to a specified path
image_documents = get_image_nodes(json_objs, IMAGES_DOWNLOAD_PATH)
# Save the extracted text to a .txt file
file_path = "parsed_data/extracted_texts.txt"
save_texts_to_file(text_nodes, file_path)以下是显示其中一个节点的提取文本和元数据的快照:
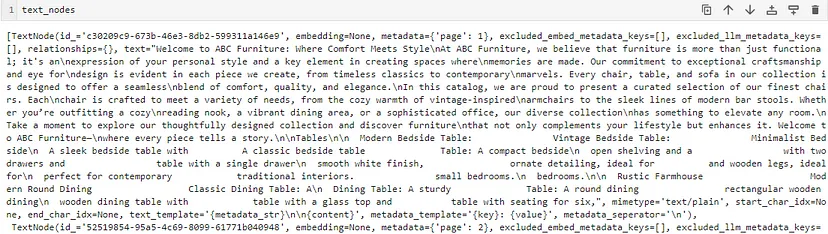
我将文本数据保存到 .txt 文件中。以下是 .txt 文件中的文本:

以下是文件夹内解析数据的结构

请注意,文本描述与各自的图像没有任何联系。目的是证明嵌入模型可以检索文本以及相关图像以响应查询,因为共享嵌入空间中文本和相关图像彼此存储得很近。
Cohere 的试用 API 允许有限的 API 速率(每分钟 5 次 API 调用)。为了嵌入目录中的所有图像,我创建了以下自定义类,以一定的延迟(30 秒,也可以测试更小的延迟)将提取的图像发送到嵌入模型:
delay = 30
# Define custom embedding class with a fixed delay after each embedding
class DelayCohereEmbedding(CohereEmbedding):
def get_image_embedding_batch(self, img_file_paths, show_progress=False):
embeddings = []
for img_file_path in img_file_paths:
embedding = self.get_image_embedding(img_file_path)
embeddings.append(embedding)
print(f"sleeping for {delay} seconds")
time.sleep(tsec) # Add a fixed 12-second delay after each embedding
return embeddings
# Set the custom embedding model in the settings
Settings.embed_model = DelayCohereEmbedding(
api_key=COHERE_API_KEY,
model_name="embed-english-v3.0"
)以下代码从目录加载已解析的文档并创建多模态 Qdrant Vector 数据库和索引(采用自 LlamaIndex 实现):
# Load documents from the directory
documents = SimpleDirectoryReader("parsed_data",
required_exts=[".jpg", ".png", ".txt"],
exclude_hidden=False).load_data()
# Set up Qdrant vector store
client = qdrant_client.QdrantClient(path="furniture_db")
text_store = QdrantVectorStore(client=client, collection_name="text_collection")
image_store = QdrantVectorStore(client=client, collection_name="image_collection")
storage_context = StorageContext.from_defaults(vector_store=text_store, image_store=image_store)
# Create the multimodal vector index
index = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
image_embed_model=Settings.embed_model,
)最后,多模态检索器创建该函数是为了从多模态向量数据库中检索匹配的文本和图像节点。检索到的文本节点和图像的数量由 similarity_top_k 和 image_similarity_top_k 定义。
retriever_engine = index.as_retriever(similarity_top_k=4, image_similarity_top_k=4)让我们测试一下检索器对查询“帮我找一把带金属支架的椅子”的响应。辅助函数 display_images 绘制检索到的图像:
###test retriever
from llama_index.core.response.notebook_utils import display_source_node
from llama_index.core.schema import ImageNode
import matplotlib.pyplot as plt
from PIL import Image
def display_images(file_list, grid_rows=2, grid_cols=3, limit=9):
"""
Display images from a list of file paths in a grid.
Parameters:
- file_list: List of image file paths.
- grid_rows: Number of rows in the grid.
- grid_cols: Number of columns in the grid.
- limit: Maximum number of images to display.
"""
plt.figure(figsize=(16, 9))
count = 0
for idx, file_path in enumerate(file_list):
if os.path.isfile(file_path) and count < limit:
img = Image.open(file_path)
plt.subplot(grid_rows, grid_cols, count + 1)
plt.imshow(img)
plt.axis('off')
count += 1
plt.tight_layout()
plt.show()
query = "Find me a chair with metal stands"
retrieval_results = retriever_engine.retrieve(query)
retrieved_image = []
for res_node in retrieval_results:
if isinstance(res_node.node, ImageNode):
retrieved_image.append(res_node.node.metadata["file_path"])
else:
display_source_node(res_node, source_length=200)
display_images(retrieved_image)文本节点和检索器检索到的图像如下所示:
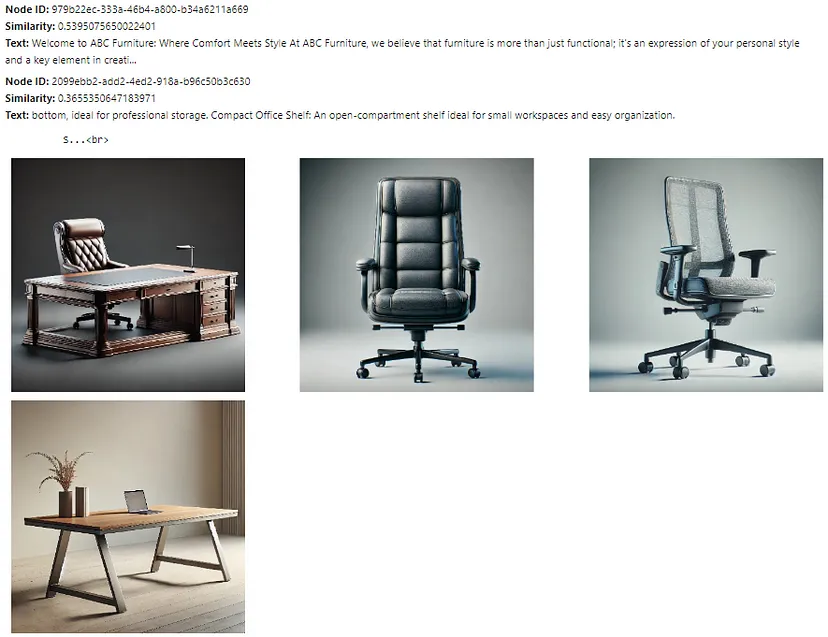
此处检索到的文本节点和图像接近查询嵌入,但并非所有文本节点和图像都相关。下一步是将这些文本节点和图像发送到多模态 LLM,以优化选择并生成最终响应。提示模板 qa_tmpl_str 指导 LLM 在此选择和响应生成过程中的行为。
import logging
from llama_index.core.schema import NodeWithScore, ImageNode, MetadataMode
# Define the template with explicit instructions
qa_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Using the provided context and images (not prior knowledge), "
"answer the query. Include only the image paths of images that directly relate to the answer.\n"
"Your response should be formatted as follows:\n"
"Result: [Provide answer based on context]\n"
"Relevant Image Paths: array of image paths of relevant images only separated by comma\n"
"Query: {query_str}\n"
"Answer: "
)
qa_tmpl = PromptTemplate(qa_tmpl_str)
# Initialize multimodal LLM
multimodal_llm = OpenAIMultiModal(model="gpt-4o", temperature=0.0, max_tokens=1024)
# Setup the query engine with retriever and prompt template
query_engine = index.as_query_engine(
llm=multimodal_llm,
text_qa_template=qa_tmpl,
retreiver=retriever_engine
)以下代码通过准备具有有效路径和元数据的图像节点,为提示模板 qa_tmpl_str 创建上下文字符串 ctx_str。它还将查询字符串嵌入提示模板。然后将提示模板与嵌入的上下文一起发送到 LLM 以生成最终响应。
# Extract the underlying nodes
nodes = [node.node for node in retrieval_results]
# Create ImageNode instances with valid paths and metadata
image_nodes = []
for n in nodes:
if "file_path" in n.metadata and n.metadata["file_path"].lower().endswith(('.png', '.jpg')):
# Add the ImageNode with only path and mimetype as expected by LLM
image_node = ImageNode(
image_path=n.metadata["file_path"],
image_mimetype="image/jpeg" if n.metadata["file_path"].lower().endswith('.jpg') else "image/png"
)
image_nodes.append(NodeWithScore(node=image_node))
logging.info(f"ImageNode created for path: {n.metadata['file_path']}")
logging.info(f"Total ImageNodes prepared for LLM: {len(image_nodes)}")
# Create the context string for the prompt
ctx_str = "\n\n".join(
[n.get_content(metadata_mode=MetadataMode.LLM).strip() for n in nodes]
)
# Format the prompt
fmt_prompt = qa_tmpl.format(context_str=ctx_str, query_str=query)
# Use the multimodal LLM to generate a response
llm_response = multimodal_llm.complete(
prompt=fmt_prompt,
image_documents=[image_node.node for image_node in image_nodes], # Pass only ImageNodes with paths
max_tokens=300
)
# Convert response to text and process it
response_text = llm_response.text # Extract the actual text content from the LLM response
# Extract the image paths after "Relevant Image Paths:"
image_paths = re.findall(r'Relevant Image Paths:\s*(.*)', response_text)
if image_paths:
# Split the paths by comma if multiple paths are present and strip any extra whitespace
image_paths = [path.strip() for path in image_paths[0].split(",")]
# Filter out the "Relevant Image Paths" part from the displayed response
filtered_response = re.sub(r'Relevant Image Paths:.*', '', response_text).strip()
display(Markdown(f"**Query**: {query}"))
# Print the filtered response without image paths
display(Markdown(f"{filtered_response}"))
if image_paths!=['']:
# Plot images using the paths collected in the image_paths array
display_images(image_paths)LLM 针对上述查询生成的最终(过滤)响应如下所示:

这表明嵌入模型成功地将文本嵌入与图像嵌入连接起来并检索相关结果,然后由 LLM 进一步细化。
下面显示了更多测试查询的结果:



现在让我们测试多模态嵌入模型以完成图像到图像的任务。我们使用不同的产品图片(不在目录中),并使用检索器来获取匹配的产品图片。以下代码使用经过修改的辅助函数 display_images 检索匹配的产品图片。
import matplotlib.pyplot as plt
from PIL import Image
import os
def display_images(input_image_path, matched_image_paths):
"""
Plot the input image alongside matching images with appropriate labels.
"""
# Total images to show (input + first match)
total_images = 1 + len(matched_image_paths)
# Define the figure size
plt.figure(figsize=(7, 7))
# Display the input image
plt.subplot(1, total_images, 1)
if os.path.isfile(input_image_path):
input_image = Image.open(input_image_path)
plt.imshow(input_image)
plt.title("Given Image")
plt.axis("off")
# Display matching images
for idx, img_path in enumerate(matched_image_paths):
if os.path.isfile(img_path):
matched_image = Image.open(img_path)
plt.subplot(1, total_images, idx + 2)
plt.imshow(matched_image)
plt.title("Match Found")
plt.axis("off")
plt.tight_layout()
plt.show()
# Sample usage with specified paths
input_image_path = 'C:/Users/h02317/Downloads/trial2.png'
retrieval_results = retriever_engine.image_to_image_retrieve(input_image_path)
retrieved_images = []
for res in retrieval_results:
retrieved_images.append(res.node.metadata["file_path"])
# Call the function to display images side-by-side
display_images(input_image_path, retrieved_images[:2])输入和输出(匹配)图像的一些结果如下所示:


这些结果表明,这种多模态嵌入模型在文本到文本、文本到图像和图像到图像任务中提供了令人印象深刻的性能。可以进一步探索此模型以用于具有大型文档的多模态 RAG,以增强对各种数据类型的检索体验。
此外,多模态嵌入模型在各种业务应用中都具有良好的潜力,包括个性化推荐、内容审核、跨模态搜索引擎和客户服务自动化。这些模型可以使公司开发更丰富的用户体验和更高效的知识检索系统。
原文链接:Multimodal AI Search for Business Applications
汇智网翻译整理,转载请标明出处
