多模态文档图像数据增强
本文介绍介绍如何使用与 Albumentations AI 合作开发的一种TextImage Augmentation实现文档图像数据增强。

在这篇博文中,我们提供了一个教程,介绍如何使用与 Albumentations AI 合作开发的一种新的文档图像数据增强技术。
1、动机
视觉语言模型 (VLM) 具有广泛的应用范围,但它们通常需要针对特定用例进行微调,特别是对于包含文档图像的数据集,即具有大量文本内容的图像。在这些情况下,文本和图像在模型训练的所有阶段相互作用至关重要,而对两种模式应用增强可确保这种相互作用。本质上,我们希望模型能够学会正确阅读,这在最常见的数据缺失情况下具有挑战性。
因此,在解决数据集有限的微调模型中的挑战时,对文档图像的有效数据增强技术的需求变得显而易见。一个常见的担忧是,典型的图像转换(例如调整大小、模糊或更改背景颜色)会对文本提取准确性产生负面影响。

我们认识到需要数据增强技术,在增强数据集的同时保留文本的完整性。这种数据增强可以促进新文档的生成或现有文档的修改,同时保持其文本质量。
2、简介
为了满足这一需求,我们引入了与 Albumentations AI 合作开发的新数据增强管道。该管道处理图像和其中的文本,为文档图像提供全面的解决方案。此类数据增强是多模态的,因为它同时修改图像内容和文本标注。
正如之前的博客文章中所讨论的,我们的目标是检验这样一个假设:在 VLM 的预训练期间集成对文本和图像的增强是有效的。详细参数和用例说明可在 Albumentations AI 文档中找到。Albumentations AI 支持动态设计这些增强并将其与其他类型的增强集成。
3、实现方法
为了增强文档图像,我们首先随机选择文档中的行。超参数 fraction_range 控制要修改的边界框分数。
接下来,我们将几种文本增强方法中的一种应用于相应的文本行,这些方法通常用于文本生成任务。这些方法包括随机插入、删除和交换以及停用词替换。
修改文本后,我们将插入文本的图像部分涂黑并对其进行修复,使用原始边界框大小作为新文本字体大小的代理。可以使用参数 font_size_fraction_range 指定字体大小,该参数确定选择字体大小的范围作为边界框高度的分数。请注意,可以检索修改后的文本和相应的边界框并将其用于训练。此过程会产生一个具有语义相似文本内容和视觉扭曲图像的数据集。
4、主要功能
TextImage Augmentation库可用于两个主要目的:
a) 在图像上插入任何文本:此功能允许你在文档图像上叠加文本,从而有效地生成合成数据。通过使用任何随机图像作为背景并渲染全新的文本,你可以创建多样化的训练样本。无 OCR 文档理解转换器中引入了一种类似的技术,称为 SynthDOG。
b) 在图像上插入增强文本:这包括以下文本增强:
- 随机删除:随机从文本中删除单词。
- 随机交换:在文本中交换单词。
- 停用词插入:将常用停用词插入文本。
将这些增强与 Albumentations 中的其他图像转换相结合,可以同时修改图像和文本。你也可以检索增强文本。
注意:此 repo 中介绍的数据增强管道的初始版本包括同义词替换。它在此版本中被删除,因为它会造成大量时间开销。
5、快速上手
使用如下代码安装TextImage Augmentation:
!pip install -U pillow
!pip install albumentations
!pip install nltk
使用如下代码导入依赖包:
import albumentations as A
import cv2
from matplotlib import pyplot as plt
import json
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
可视化:
def visualize(image):
plt.figure(figsize=(20, 15))
plt.axis('off')
plt.imshow(image)
5.1 加载数据
请注意,对于这种类型的增强,你可以使用 IDL 和 PDFA 数据集。它们提供你要修改的线条的边界框。在本教程中,我们将重点介绍 IDL 数据集中的样本。
bgr_image = cv2.imread("examples/original/fkhy0236.tif")
image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
with open("examples/original/fkhy0236.json") as f:
labels = json.load(f)
font_path = "/usr/share/fonts/truetype/liberation/LiberationSerif-Regular.ttf"
visualize(image)

我们需要正确地预处理数据,因为边界框的输入格式是标准化的 Pascal VOC。因此,我们按如下方式构建元数据:
page = labels['pages'][0]
def prepare_metadata(page: dict, image_height: int, image_width: int) -> list:
metadata = []
for text, box in zip(page['text'], page['bbox']):
left, top, width_norm, height_norm = box
metadata.append({
"bbox": [left, top, left + width_norm, top + height_norm],
"text": text
})
return metadata
image_height, image_width = image.shape[:2]
metadata = prepare_metadata(page, image_height, image_width)
5.2 随机交换
transform = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["swap"], clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9))])
transformed = transform(image=image, textimage_metadata=metadata)
visualize(transformed["image"])

5.3 随机删除
transform = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["deletion"], clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9))])
transformed = transform(image=image, textimage_metadata=metadata)
visualize(transformed['image'])

5.4 随机插入
在随机插入中,我们将随机单词或短语插入文本中。在这种情况下,我们使用停用词,即语言中的常用词,在自然语言处理 (NLP) 任务中经常被忽略或过滤掉,因为它们与其他词相比所包含的信息较少。停用词的示例包括 “is”、 “the”、 “in”、 “and”、 “of”等。
stops = stopwords.words('english')
transform = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["insertion"], stopwords = stops, clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9))])
transformed = transform(image=image, textimage_metadata=metadata)
visualize(transformed['image'])

6、我们可以与其他转换结合吗?
让我们使用 A.Compose 定义一个复杂的转换管道,其中包括使用指定字体属性和停用词插入文本、普朗克抖动和仿射变换。首先,使用 A.TextImage,我们使用指定的字体属性将文本插入图像中,背景清晰,字体颜色为红色。还要指定要插入的文本的比例和大小。然后使用 A.PlanckianJitter 改变图像的色彩平衡。最后,使用 A.Affine 应用仿射变换,其中包括缩放、旋转和平移图像。
transform_complex = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["insertion"], stopwords = stops, clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9)),
A.PlanckianJitter(p=1),
A.Affine(p=1)
])
transformed = transform_complex(image=image, textimage_metadata=metadata)
visualize(transformed["image"])

7、如何获取更改后的文本?
要提取更改文本的边界框索引信息以及相应的转换文本数据,请运行以下单元格。此数据可有效用于训练模型以识别和处理图像中的文本变化。
transformed['overlay_data']
[{'bbox_coords': (375, 1149, 2174, 1196),
'text': "Lionberger, Ph.D., (Title: if Introduction to won i FDA's yourselves Draft Guidance once of the wasn't General Principles",
'original_text': "Lionberger, Ph.D., (Title: Introduction to FDA's Draft Guidance of the General Principles",
'bbox_index': 12,
'font_color': 'red'},
{'bbox_coords': (373, 1677, 2174, 1724),
'text': "After off needn't were a brief break, ADC member mustn Jeffrey that Dayno, MD, Chief Medical Officer for at their Egalet",
'original_text': 'After a brief break, ADC member Jeffrey Dayno, MD, Chief Medical Officer at Egalet',
'bbox_index': 19,
'font_color': 'red'},
{'bbox_coords': (525, 2109, 2172, 2156),
'text': 'll Brands recognize the has importance and of a generics ADF guidance to ensure which after',
'original_text': 'Brands recognize the importance of a generics ADF guidance to ensure',
'bbox_index': 23,
'font_color': 'red'}]
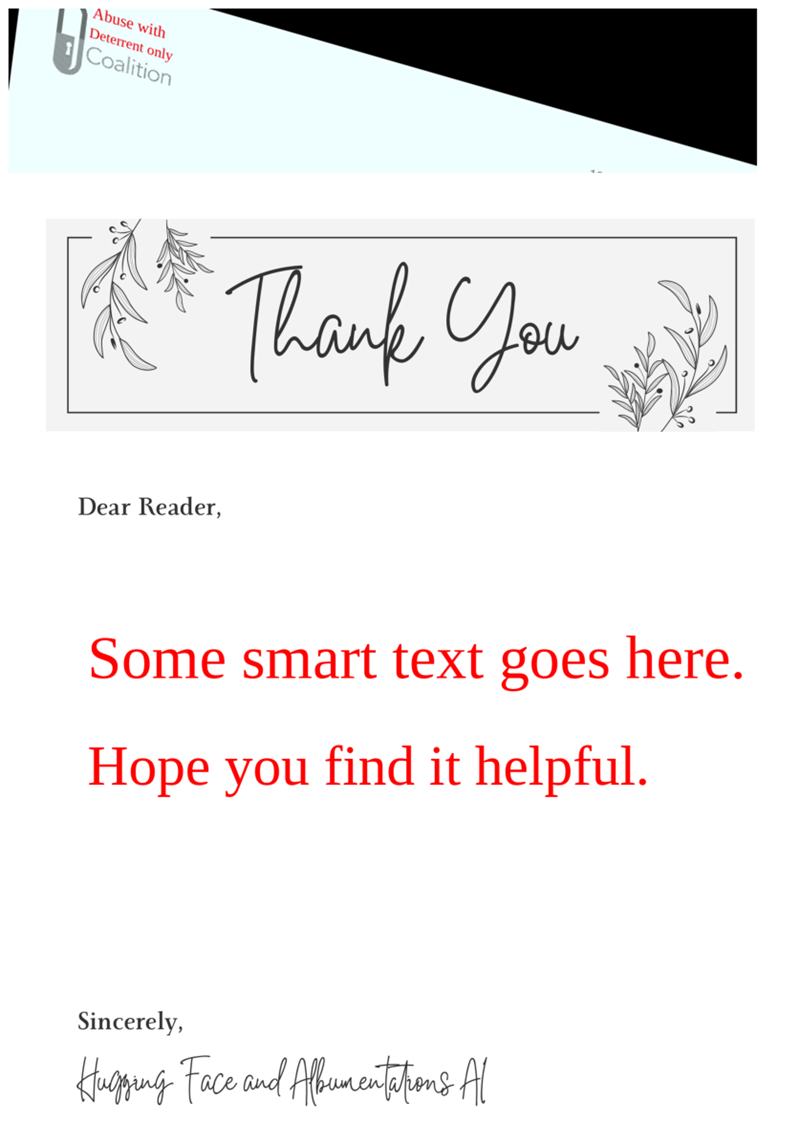
8、合成数据生成
此增强方法可以扩展到合成数据的生成,因为它可以在任何背景或模板上呈现文本。
template = cv2.imread('template.png')
image_template = cv2.cvtColor(template, cv2.COLOR_BGR2RGB)
transform = A.Compose([A.TextImage(font_path=font_path, p=1, clear_bg=True, font_color = 'red', font_size_fraction_range=(0.5, 0.7))])
metadata = [{
"bbox": [0.1, 0.4, 0.5, 0.48],
"text": "Some smart text goes here.",
}, {
"bbox": [0.1, 0.5, 0.5, 0.58],
"text": "Hope you find it helpful.",
}]
transformed = transform(image=image_template, textimage_metadata=metadata)
visualize(transformed['image'])
9、结束语
我们与 Albumentations AI 合作,推出了 TextImage Augmentation,这是一种多模态技术,可修改文档图像和文本。通过将文本增强(例如随机插入、删除、交换和停用词替换)与图像修改相结合,此管道允许生成不同的训练样本。
有关详细参数和用例说明,请参阅 Albumentations AI 文档。我们希望你发现这些增强功能对增强文档图像处理工作流程有用。
原文链接:Introducing Multimodal TextImage Augmentation for Document Images
汇智网翻译整理,转载请标明出处
