N8N:本地零代码AI环境
们将使用n8n自托管 AI 入门套件快速设置本地 AI 环境,并学习如何通过 n8n 仪表板使用哈利波特数据集为 RAG)聊天机器人构建 AI 工作流。
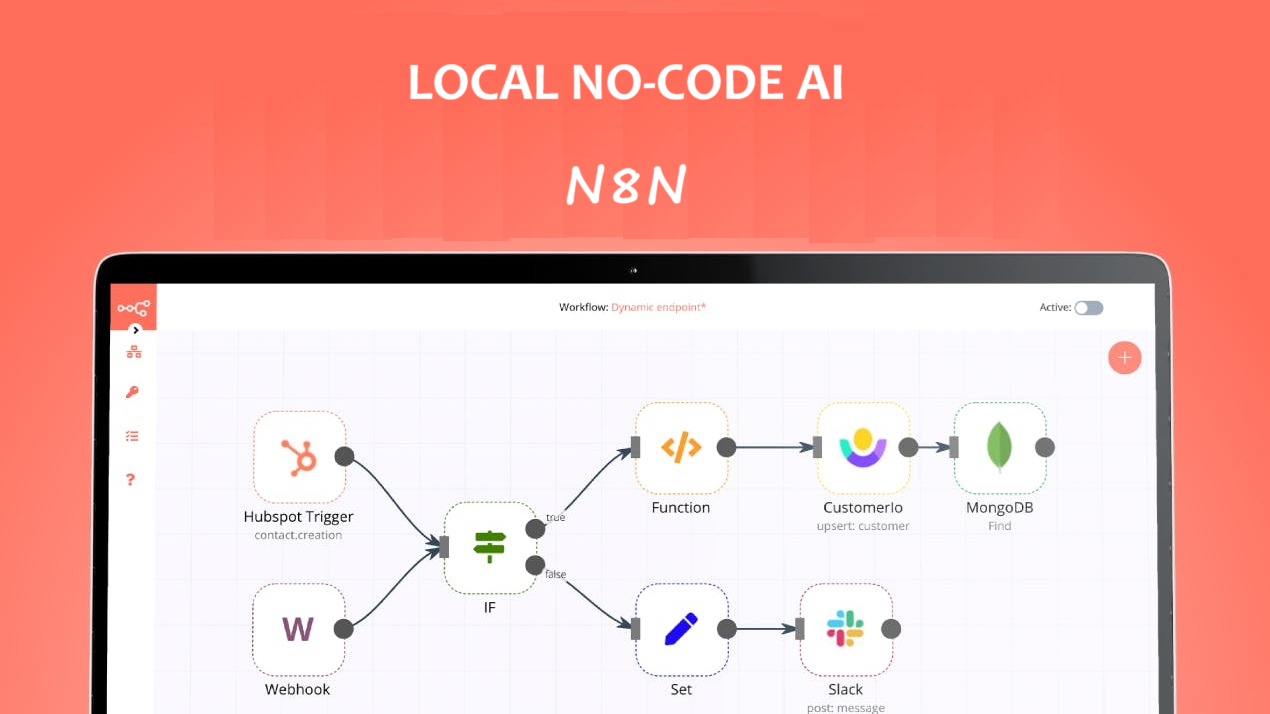
全球各地的公司越来越关注在利用 AI 的同时保护敏感信息。本指南介绍了一种使用强大的开源工具组合构建安全的本地 AI 应用程序的全面解决方案。
我们将使用自托管 AI 入门套件快速设置本地 AI 环境。该套件将自动运行 Ollama、Qdrant、n8n 和 Postgres。此外,我们将学习如何通过 n8n 仪表板使用哈利波特数据集为 RAG(检索增强生成)聊天机器人构建 AI 工作流。
无论你是开发人员、数据科学家还是希望实施安全 AI 解决方案的非技术专业人士,本教程都将为你提供创建强大的自托管 AI 工作流的基础,同时保持对敏感数据的完全控制。
1、什么是本地 AI?
本地 AI 允许你在自己的基础设施而不是云服务上运行人工智能系统和工作流,从而提供增强的隐私和成本效率。
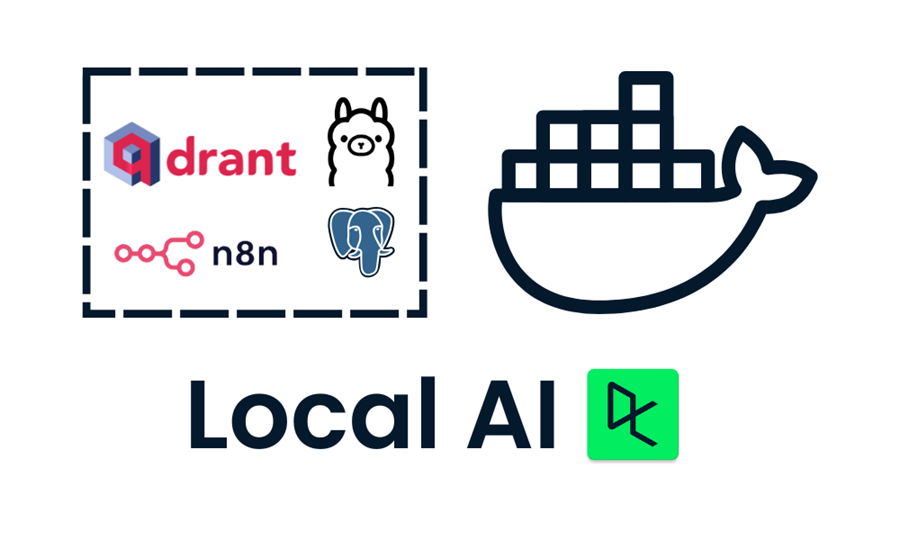
以下是我们将用于构建和运行本地 AI 应用程序的工具列表:
- Docker:这是你的容器化平台,将所有 AI 组件打包到可管理的隔离环境中。它将帮助我们使用单个命令运行所有 AI 工具。
- n8n:一个工作流自动化框架,允许你使用拖放界面构建 AI 工作流。它不需要编码知识,非常适合非技术人员。
- Postgres:此工具存储所有数据和日志,充当 n8n 框架的内存缓冲区。
- Qdrant:一个矢量数据库和搜索引擎,使 AI 生成的内容可搜索和管理。
- Ollama:一种 AI 模型管理器,可让你以最低的硬件要求在本地运行任何开源大型语言模型。
n8n 是我们为 RAG Chatbot 构建 AI 工作流的主要框架。我们将使用 Qdrant 作为向量存储,使用 Ollama 作为 AI 模型提供程序。这些组件将共同帮助我们创建 RAG 系统。
2、安装 Docker
我们将通过访问 Docker 官方网站下载并安装 Docker 桌面应用程序。安装和开始使用都非常简单。
Windows 用户需要一个额外的工具来成功运行 Docker 容器:Windows Subsystem for Linux (WSL)。这允许开发人员安装 Linux 发行版并直接在 Windows 上使用 Linux 应用程序。
要在 Windows 上安装 WSL,请在终端或 PowerShell 中输入以下命令。确保以管理员身份启动 PowerShell。
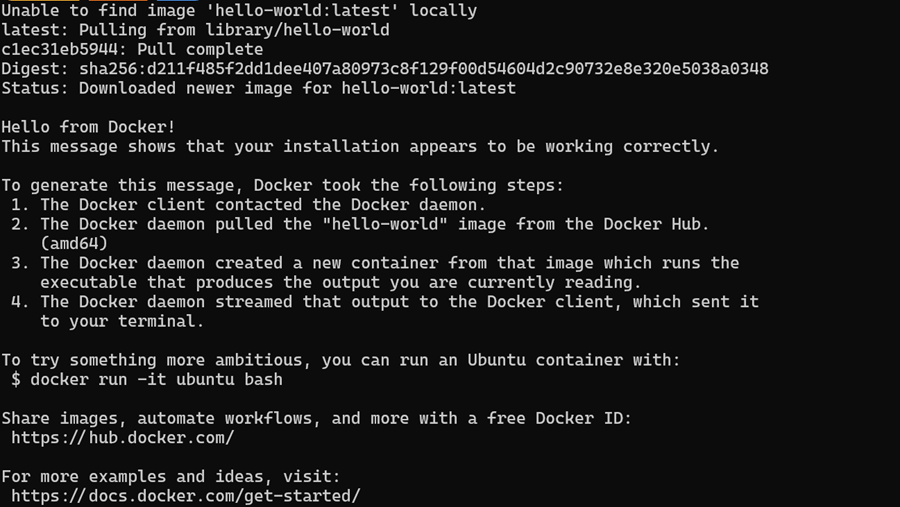
$ wsl --install成功安装 WSL 后,重新启动系统。然后,在 PowerShell 中键入以下命令以检查 Docker 是否正常工作。
$ docker run hello-worldDocker 成功拉取 hello-world 镜像并启动容器。
3、使用 Docker安装和运行本地 AI 应用程序
在本指南中,我们将学习如何使用 Docker Compose 在本地设置 AI 服务。这种方法允许你在几分钟内加载 Docker 映像并部署容器,从而提供一种在基础架构上运行和管理多个 AI 服务的简单方法。
首先,我们将通过在终端中键入以下命令来克隆 n8n-io/self-hosted-ai-starter-kit。
$ git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
$ cd self-hosted-ai-starter-kit入门套件是设置构建 AI 工作流所需的服务器和应用程序的最简单方法。然后,我们将加载 Docker 映像并运行容器。
$ docker compose --profile cpu up如果你有 NVIDIA GPU,请尝试键入以下命令以访问响应生成中的加速。此外,按照 Ollama Docker 指南为 Docker 设置 NVIDIA GPU。
$ docker compose --profile gpu-nvidia up它将需要几分钟,因为它会下载所有 Docker 映像,然后逐个运行 Docker 容器。
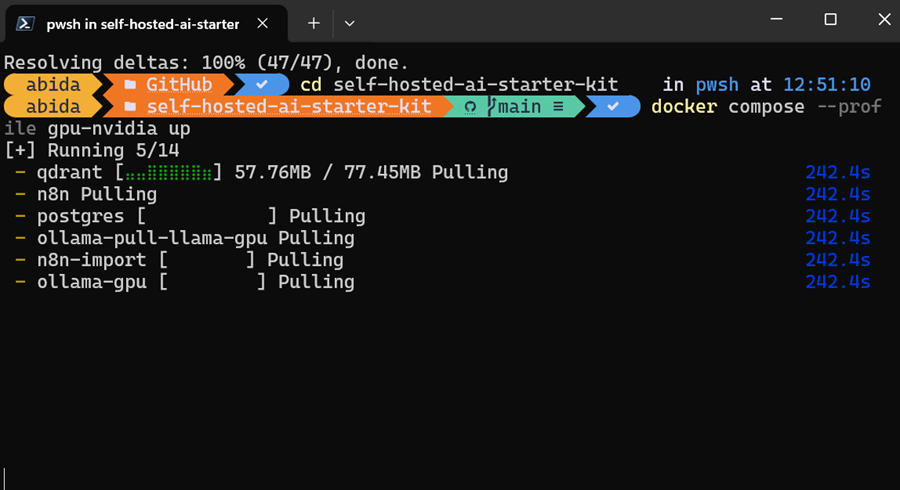
所有 Docker 服务都在运行。退出的 Docker 容器用于下载 Llama 3.2 模型并导入 n8n 备份工作流。
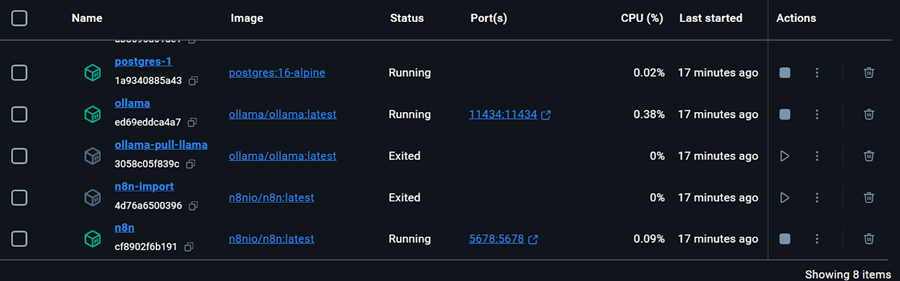
我们甚至可以通过在终端中输入以下命令来检查运行 docker 容器的状态。
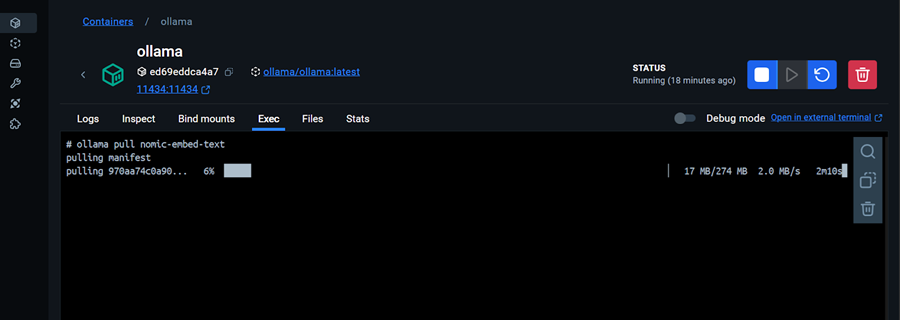
$ docker compose ps入门套件包含用于下载 Llama 3.2 模型的脚本。但是,对于正确的 RAG Chatbot 应用程序,我们还需要嵌入模型。我们将转到 Ollama Docker 容器,单击“Exec”选项卡,然后键入以下命令以下载“nomic-embed-text”模型。
$ ollama pull nomic-embed-text如我们所见,我们可以与 Docker 容器交互,就像它是一台单独的虚拟机一样。
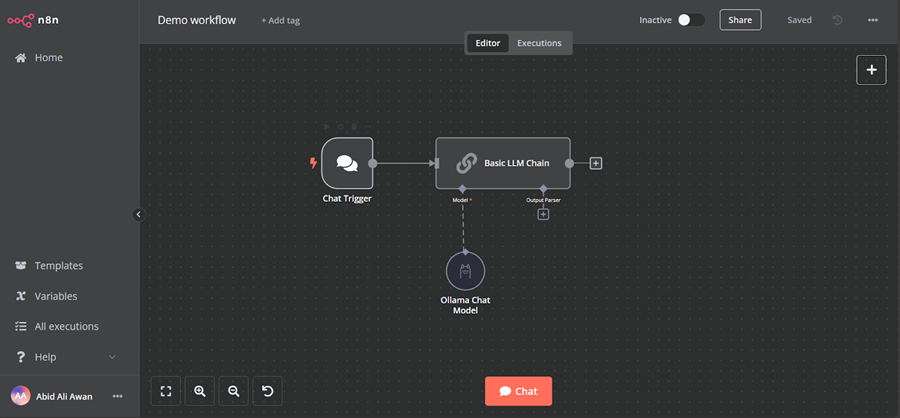
在浏览器中打开 n8n 仪表板 URL http://localhost:5678/,以使用电子邮件和密码设置 n8n 用户帐户。然后,单击主仪表板页面上的主页按钮并访问演示工作流。
该演示是一个简单的 LLM 工作流,它接受用户输入并生成响应。
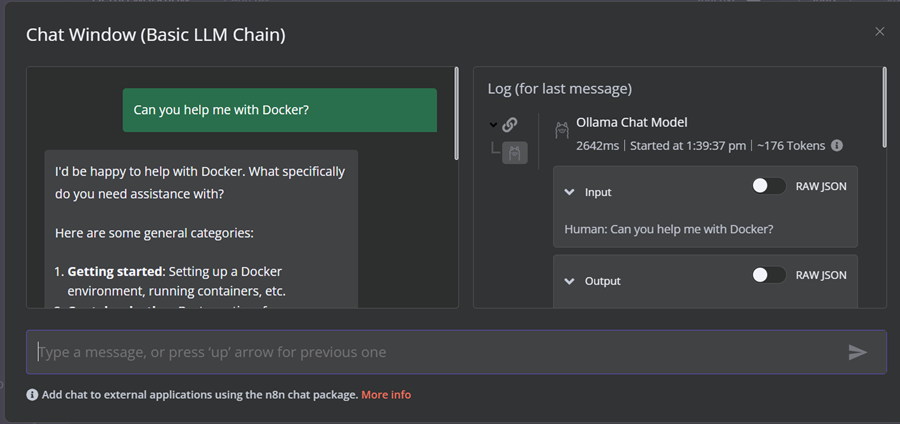
要运行工作流,请单击聊天按钮并开始输入你的问题。几秒钟内,将生成响应。
请注意,我们使用的是具有 GPU 加速的小型语言模型,因此响应通常只需大约 2 秒。
4、使用 n8n 仪表板创建 AI 工作流
在这个项目中,我们将构建一个 RAG(检索增强生成)聊天机器人,它使用来自《哈利波特》电影的数据来提供情境感知和准确的响应。这个项目是一个无代码解决方案,这意味着你需要做的就是搜索必要的工作流组件并将它们连接起来以创建 AI 工作流。
n8n 是一个类似于 Langchain 的无代码平台。、
4.1 添加聊天触发器
单击仪表板中间的“添加第一步”按钮,搜索“聊天触发器”,然后添加它。
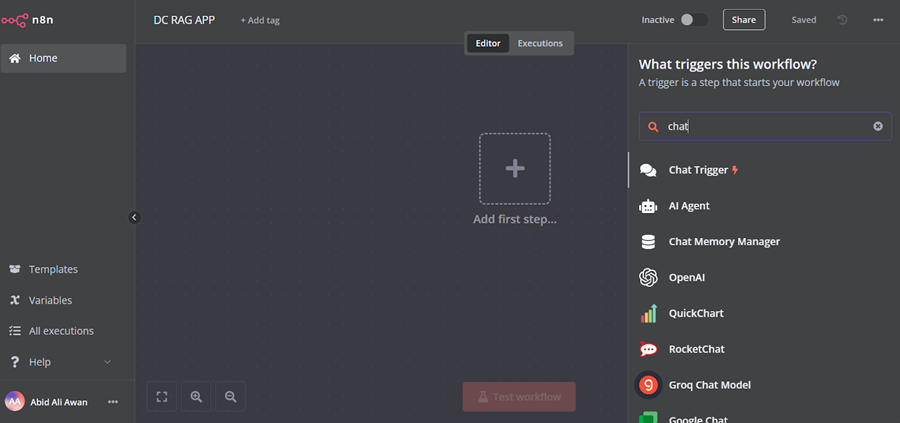
确保你已启用“允许文件上传”。
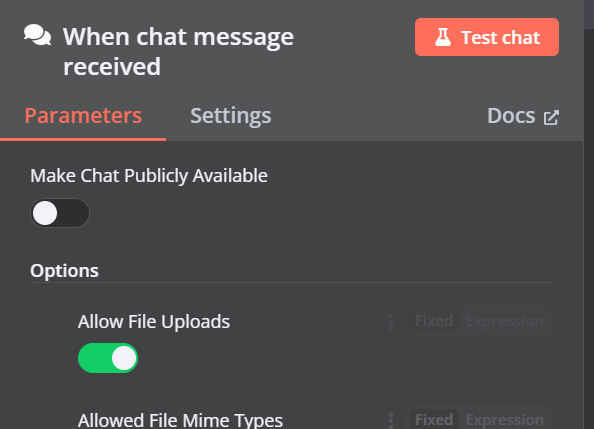
4.2 添加 Qdrant 向量存储
你可以通过单击“聊天触发器”组件上的加号 (+) 按钮并搜索它来添加另一个名为“Qdrant 向量存储”的组件。
将操作模式更改为“插入文档”,将 Qdrant 集合更改为“按 ID”,然后输入 ID 作为“Harry_Potter”。
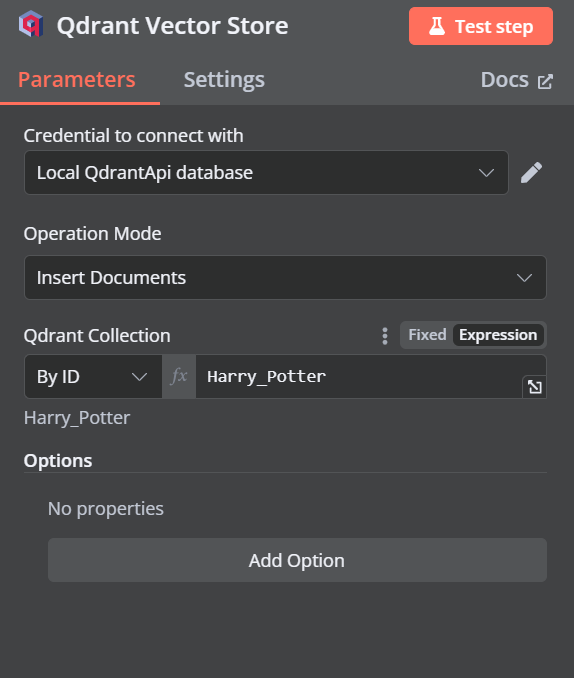
退出该选项时,我们将看到聊天触发器与我们的向量存储相连。
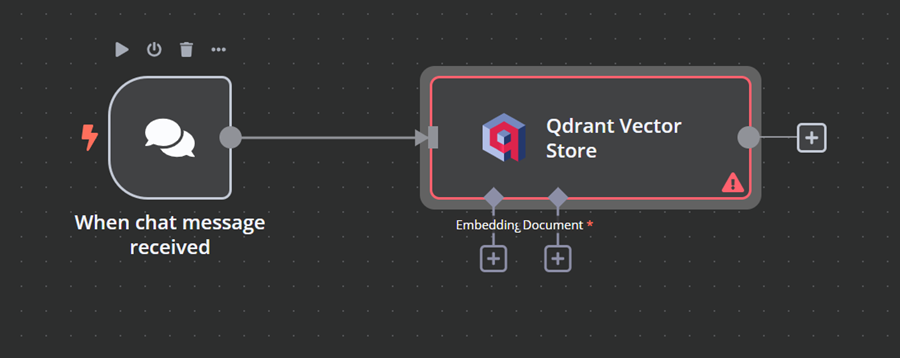
4.3 连接嵌入模型与向量存储
单击 Qdrant 向量存储下标有“嵌入”的加号按钮。我们将进入模型管理菜单,在那里我们将选择嵌入 Ollama 并将模型更改为“nomic-embed-text:latest”。
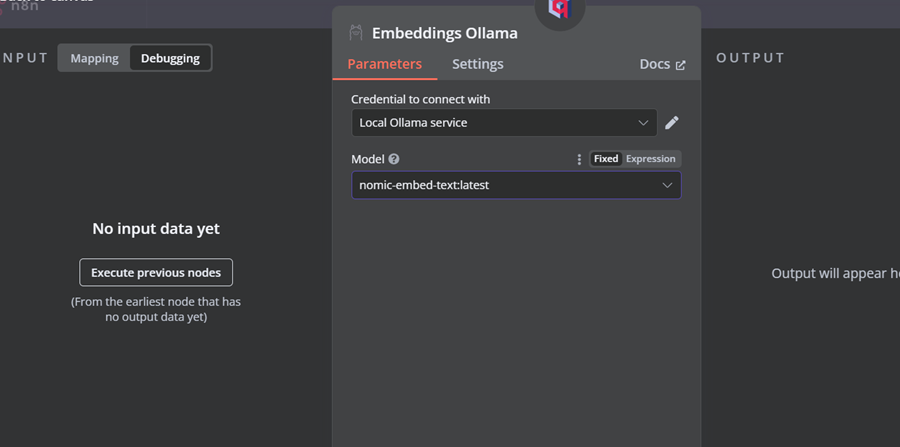
4.4 连接文档加载器与向量存储
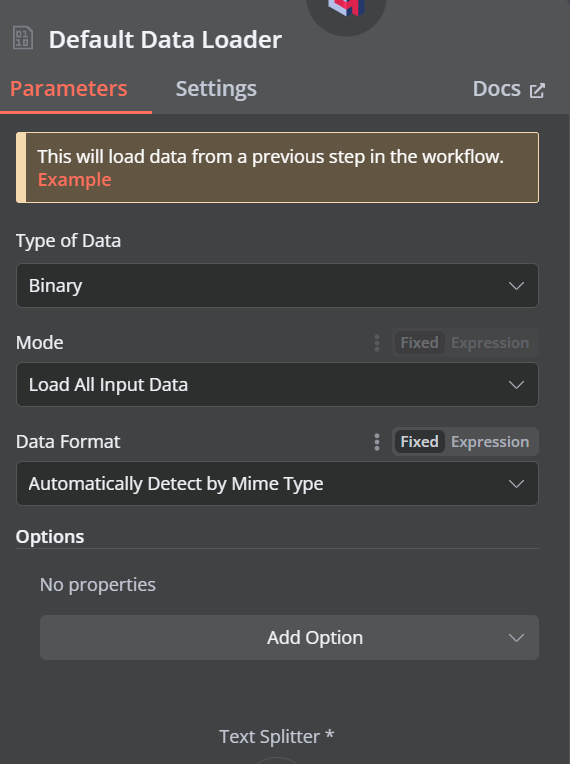
单击 Qdrant 向量存储下显示“文档”的加号按钮,然后从菜单中选择“默认数据加载器”。将数据类型更改为“二进制”。
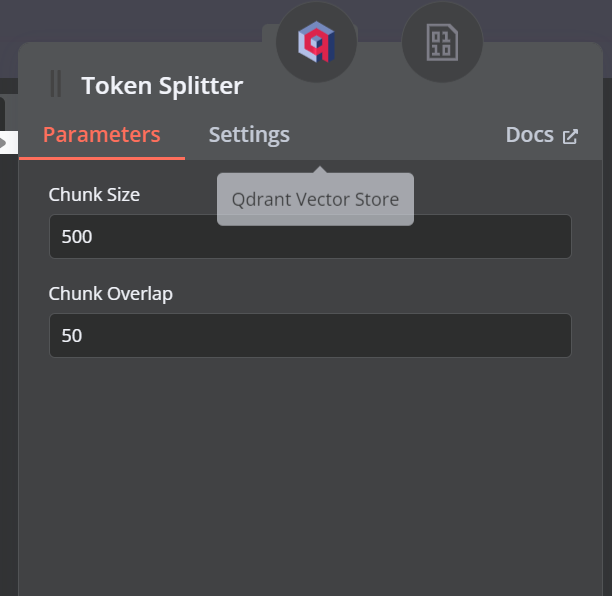
然后,添加一个块大小为 500 的令牌拆分器,并将 50 的块重叠添加到文档加载器。
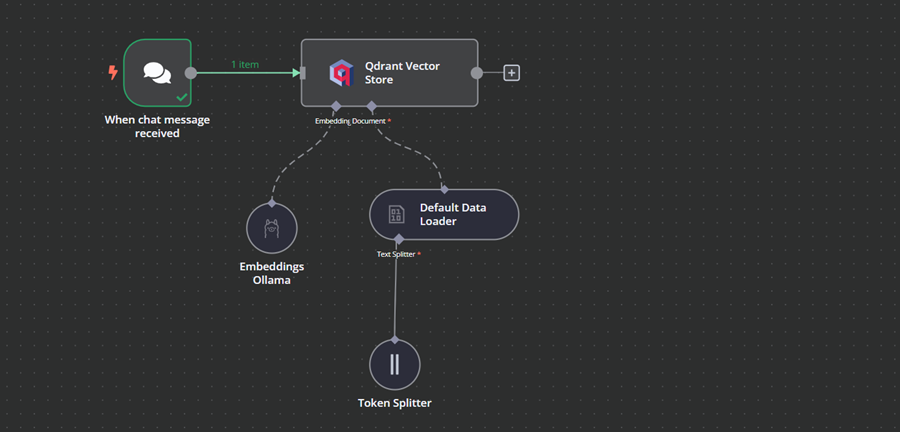
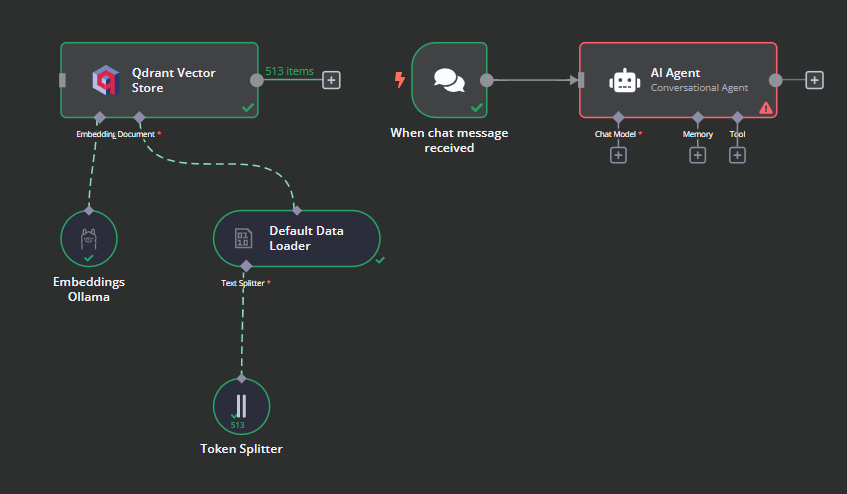
这就是我们的工作流程最终应该是什么样子。此工作流程将从用户那里获取 CSV 文件,将它们转换为文本,然后将文本转换为嵌入并将它们存储在向量存储中。
4.5 测试 Qdrant 向量存储
单击仪表板底部的聊天按钮。聊天窗口打开后,单击文件按钮,如下所示。

在此工作流中,我们将加载来自《哈利波特电影》数据集的所有 CSV 文件。但是,为了测试我们的工作流,我们将仅根据用户查询加载一个名为“spell”的 CSV 文件。
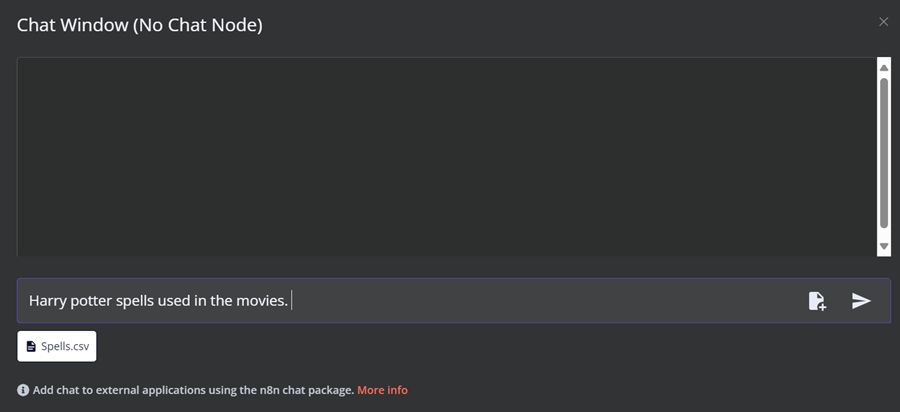
你可以使用 URL http://localhost:6333/dashboard 转到 Qdrant 服务器,并检查文件是否已加载到向量存储或注释中。

现在,将其余文件添加到向量存储中。
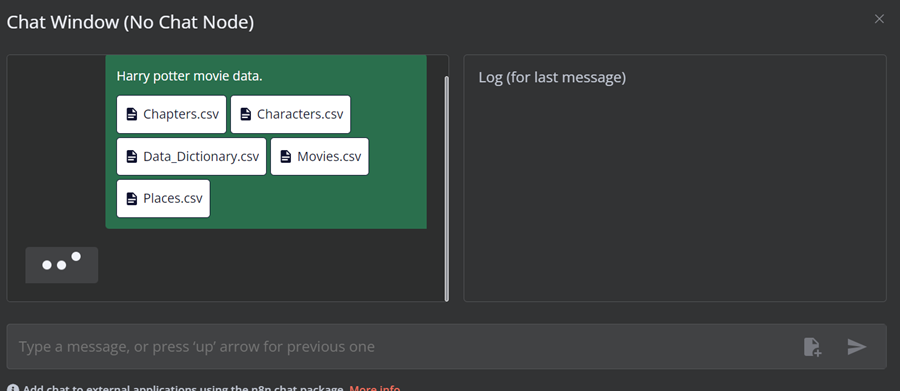
4.6 添加 AI 代理
我们将聊天触发器连接到向量存储,将其链接到 AI 代理,并将代理类型更改为“对话代理”。
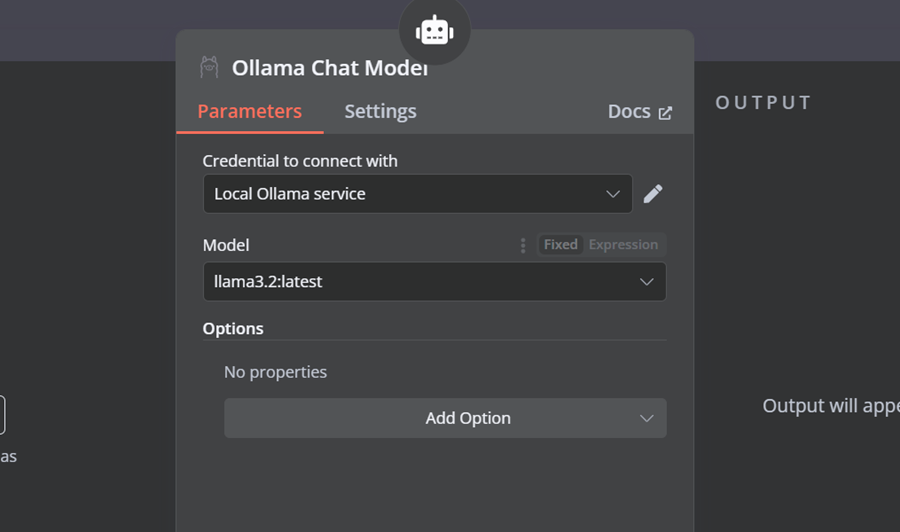
4.7 连接聊天模型与 AI 代理
单击 AI 代理下的“聊天模型”按钮,然后从菜单中选择 Ollama 聊天模型。之后,将模型名称更改为“Llama3.2:latest”。
4.8 连接向量存储工具与 AI 代理
单击 AI 代理下的“工具”按钮,然后从菜单中选择向量存储工具。提供工具名称和说明。
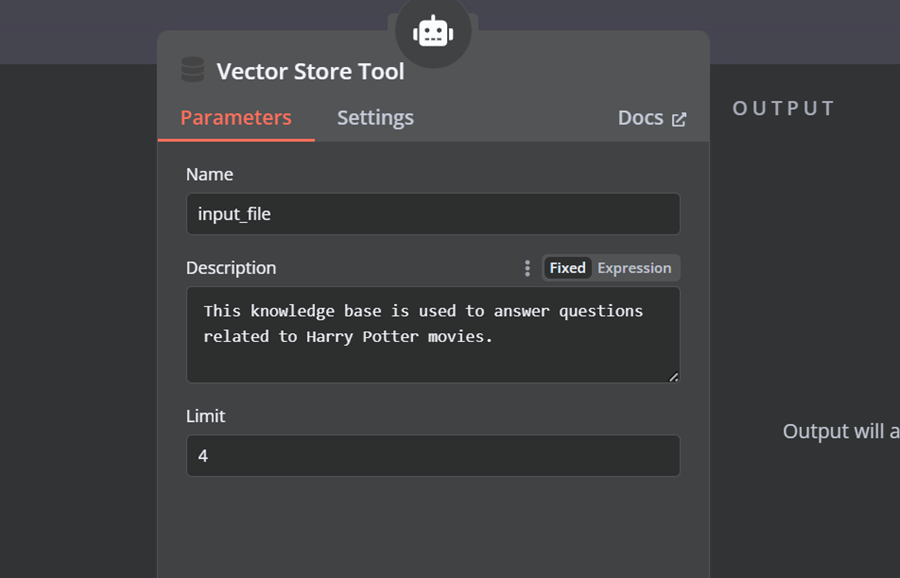
4.9 连接Qdrant 检索器与向量存储工具
我们需要向向量存储工具添加组件。首先,我们将 Qdrant 作为向量存储,并将集合 ID 设置为“Harry_Potter”。此向量存储将在相似性搜索期间访问 Harry Potter 集合。此外,将操作模式更改为“已检索文档”。
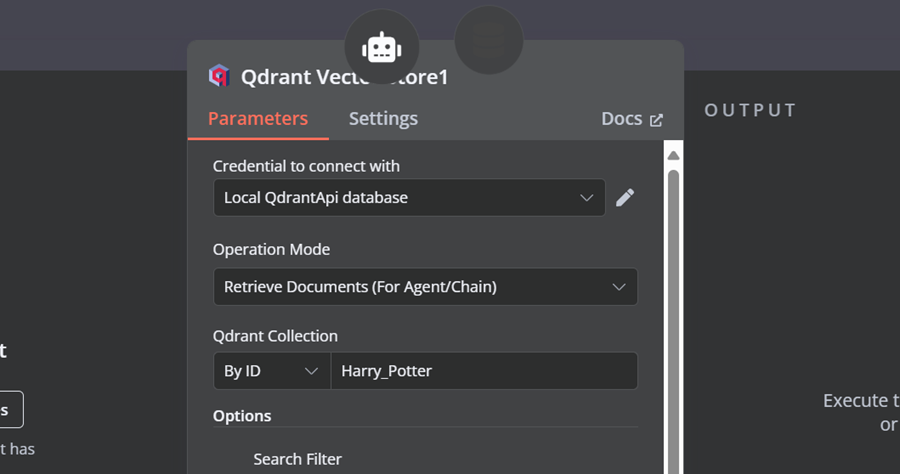
4.10 连接聊天模型与向量存储工具
向量存储工具还需要 LLM 模型。我们将连接 Ollama 聊天模型,并将模型更改为“llama3.2:latest”。
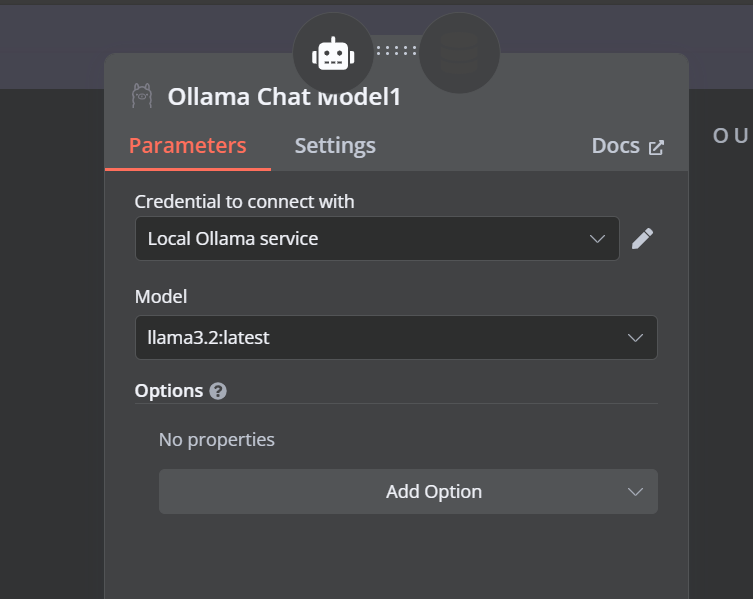
4.11 连接嵌入模型与 Qdrant 检索器
在最后一步,我们将为检索向量存储提供嵌入模型。这允许它将用户查询转换为嵌入,然后将嵌入转换回文本以供 LLM 处理。
确保为向量存储提供正确的嵌入模型。
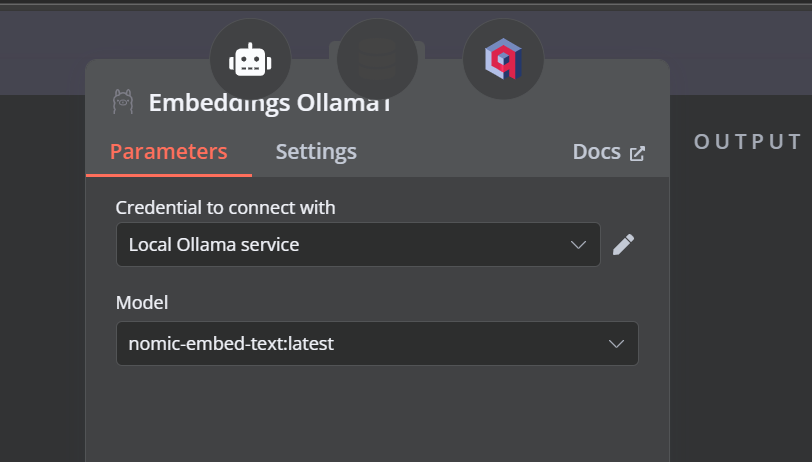
AI 工作流程应该是这样的。
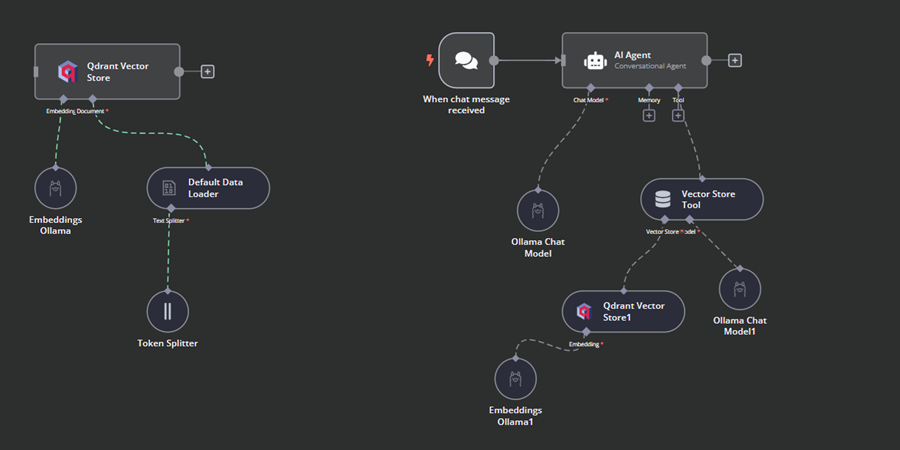
4.12 测试 AI 工作流程
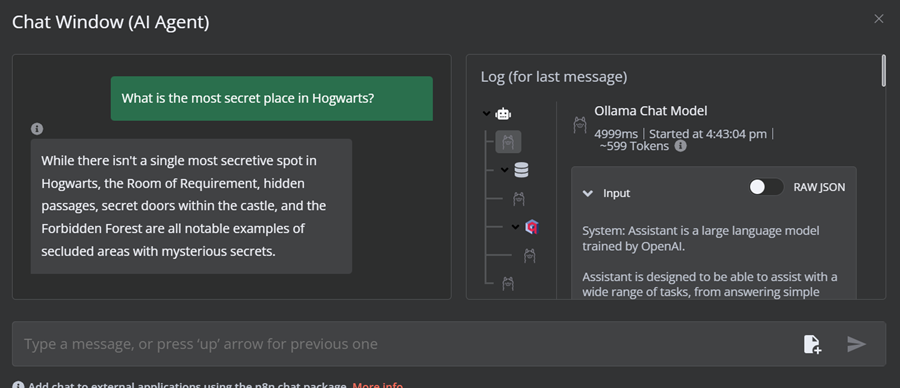
单击聊天按钮开始询问有关哈利波特宇宙的问题。
提示:“霍格沃茨最秘密的地方是什么?”
提示:“最强大的咒语是什么?”
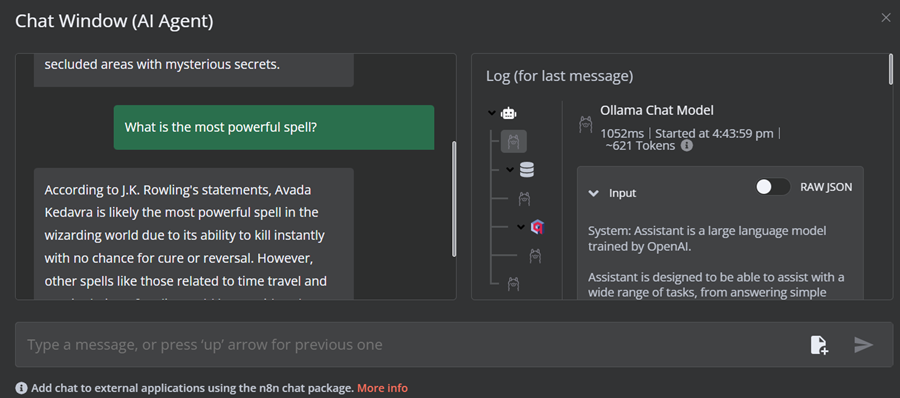
我们的 AI 工作流程快速且运行顺畅。这种无代码方法非常容易执行。 n8n 还允许用户共享他们的应用程序,以便任何人都可以使用链接访问它们,就像 ChatGPT 一样。
5、结束语
在本教程中,我们了解了本地 AI 以及如何使用自托管 AI 入门套件来构建和部署各种 AI 服务。然后,我们启动了 n8n 仪表板并使用 Qdrant、嵌入模型、向量存储工具、LLM 和文档加载器等创建了自己的 AI 工作流程。使用 n8n 创建和执行工作流非常容易。
原文链接:Local AI with Docker, n8n, Qdrant, and Ollama
汇智网翻译整理,转载请标明出处