O3-Mini/R1/Qwen2.5实测比较
我向这3个模型提供了一系列相同的提示,以测试它们从高级推理和编码能力到解决问题能力等各个方面。

DeepSeek 的 R1 模型以其速度、推理能力和免费访问赢得了用户的青睐。该模型在逻辑推理和推理等几个关键领域表现出色,擅长理解和处理复杂信息。
DeepSeek 在数学推理和编码任务方面表现出色,能够有效解决复杂问题并生成代码片段。凭借卓越的多语言能力和高推理效率,该模型在广泛的应用中表现出色。
OpenAI 的 o3-mini 模型现已在 ChatGPT 的免费套餐中提供,它是一种紧凑但功能强大的 AI 模型,旨在在高级推理、编码能力和数学问题解决方面表现出色,在美国数学邀请赛 (AIME) 中获得了 96.7% 的分数,超过了其前身 o1。
然而,自阿里巴巴的 Qwen 2.5 推出以来,它一直是 DeepSeek 和 ChatGPT 的头号竞争对手。这款聊天机器人对用户免费,并且在编码能力、多语言理解、数学推理和高效快速的扩展内容处理方面也表现出色,在竞争激烈的人工智能领域中独树一帜。
那么这些聊天机器人相比如何?我对它们进行了一系列相同的提示,以测试它们从高级推理和编码能力到解决问题能力等各个方面。以下是这些免费层模型(包括总冠军)对决时发生的情况。
1、编码挑战

Prompt: "Write a Python script that simulates a basic banking system with functionalities to deposit, withdraw, and check balance."提示:“编写一个 Python 脚本,模拟一个具有存款、取款和查询余额功能的基本银行系统。”
o3-mini 使用基于类的方法提供了可靠的实现,并包含有意义的错误消息,同时确保正确处理存款和取款。它还对每种方法及其功能进行了清晰的解释。
Qwen 2.5 提供了脚本工作原理的结构良好的细分,涵盖了类定义、存款/取款方法、错误处理和用户体验。它包括 try-except 块来处理无效输入,使其更加强大。该脚本简洁且注释良好,初学者很容易理解。
DeepSeek 保持脚本的结构和效率,并为帐户引入所有者名称,增加了个人风格。然而,它缺乏输入验证(例如,没有针对非数字输入的 try-except 处理),虽然解释很清楚,但不如 Qwen 2.5 那么详细。
获胜者:Qwen 2.5 因提供简洁、结构良好的脚本、强大的错误处理、详细的解释和直观的用户体验而获胜。o3-mini 实施良好,但在错误处理方面略显不足,紧随其后。
2、数学证明
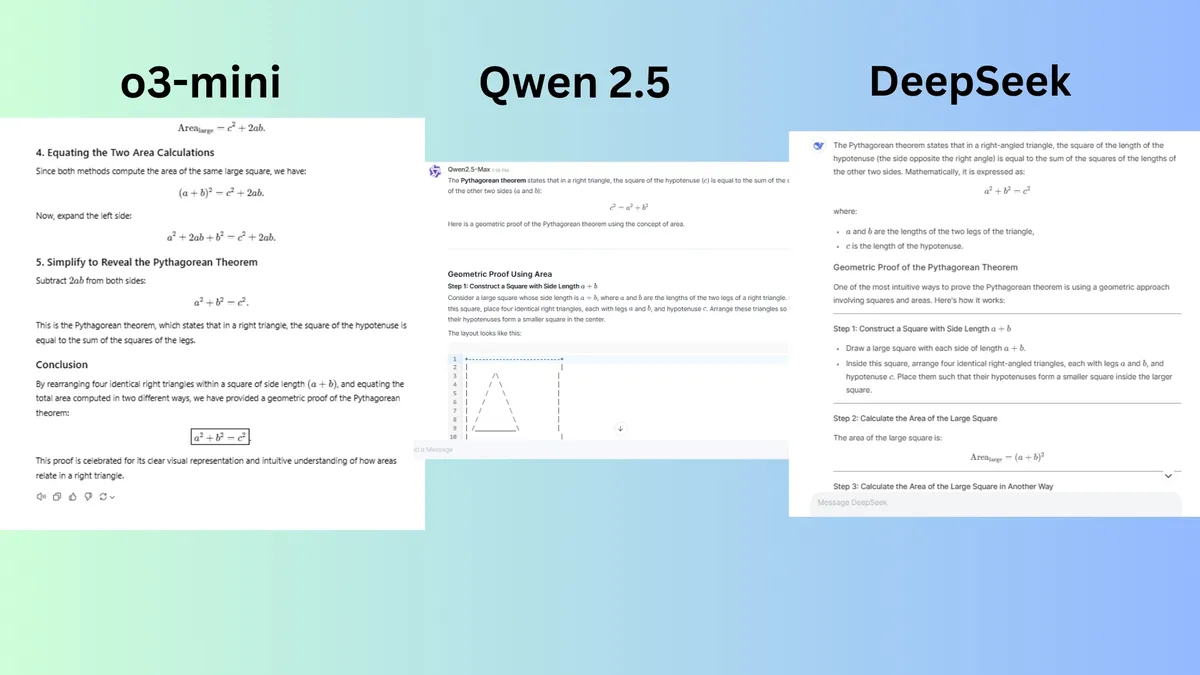
Prompt: "Prove the Pythagorean theorem using a geometric approach."提示:“使用几何方法证明勾股定理。”
o3-mini 提供的解释遵循结构良好、循序渐进的方法,使其易于理解。解释既不过分冗长,也不缺乏必要的细节。
Qwen 2.5 提供了与 o3-mini 类似的方法,使用大正方形并重新排列三角形,同时清晰、有条不紊地分解步骤。解释包含格式问题,并且某些部分(如 ASCII 图)略微不清楚或错位,使其更难可视化。
DeepSeek 制作了一个遵循逻辑结构的正确证明。但它在解释该方法为何有效方面缺乏深度。
获胜者:o3-mini 以清晰度、细节和逻辑流程的最佳组合获胜。Qwen 2.5 位居第二,反应稳健,但格式和可视化问题。
3、科学解释

Prompt: "Explain the process of photosynthesis in detail."
提示:“详细解释光合作用的过程。”
o3-mini 提供了光依赖和光独立反应的详细描述,并清晰地分解了每个步骤。从捕获光到将能量转化为葡萄糖的逐步进展很容易理解。它将复杂的过程分解为可消化的部分。
Qwen 2.5 提供了光合作用的所有关键概念,并提供了良好的分步说明
光依赖反应和卡尔文循环的详细解释。然而,聊天机器人不太强调气候变化、粮食安全等现实意义,与 o3-mini 的详尽解释相比,其回答显得过于简练。
DeepSeek 很好地涵盖了光合作用的两个阶段,并包括影响光合作用的因素(例如,光强度、二氧化碳水平、水资源可用性),但与 o3-mini 的回答相比,缺乏技术深度。
获胜者:o3-mini 在深度、清晰度、组织性和准确性方面取得最佳平衡。DeepSeek 以扎实的解释紧随其后,但缺少一些更精细的细节。
4、历史分析

Prompt: "Analyze the causes and effects of the French Revolution."提示:“分析法国大革命的原因和影响。”
o3-mini 进行了全面且结构良好的分析,将原因和影响清楚地分为不同的部分,并为每个因素提供深入的解释,而不仅仅是列出它们。
Qwen 2.5 在其强有力的解释和井然有序的回应中讨论了全球影响,包括拿破仑和后来的革命。然而,经济后果本可以更详细地探讨。
DeepSeek 很好地涵盖了关键原因,包括社会不平等、经济斗争和启蒙思想,但缺乏分析深度和对资料来源的引用。
获胜者:o3-mini 因在深度、清晰度、组织和历史分析方面取得最佳平衡而获胜。DeepSeek 以可靠的回应位居第二,但细节略少。
5、文学评论

Prompt: "Provide a critical analysis of Shakespeare's 'Hamlet' focusing on its themes of madness and revenge."提示:“对莎士比亚的《哈姆雷特》进行批判性分析,重点关注其疯狂和复仇的主题。”
o3-mini 探讨了疯狂和复仇这两个主题,以及它们如何交织在一起,而不是将它们视为单独的主题。它探讨了哈姆雷特的心理斗争,考察了他的疯狂是假装的还是真实的,这是莎士比亚学术界争论的焦点。
Qwen 2.5 对假装疯狂与真实疯狂进行了非常详细的讨论。然而,在解释复仇方面有些冗余,感觉更像是描述性的而不是分析性的。
DeepSeek 对哈姆雷特、雷欧提斯和福丁布拉斯的复仇方式进行了扎实的比较,但回应感觉像是结构良好的总结,而不是深入的分析。列表式的结构让它感觉不像是流畅的批判性论点。
获胜者:o3-mini 再次赢得深度、结构和主题联系的最佳融合。DeepSeek 以强有力的回应位居第二,但它更像是总结,交织性较差。
6、哲学讨论

Prompt: "Discuss the concept of utilitarianism and its implications in modern ethics."提示:“讨论功利主义的概念及其在现代伦理学中的含义。”
o3-mini 明确概述了功利主义的核心原则(结果主义、享乐主义计算、公正性),并比其他回应更详细地讨论了它们的现代应用(政策制定、医疗保健、环境伦理)。
Qwen 2.5 对行为与规则功利主义进行了详尽的分析,并很好地涵盖了商业伦理、技术、人工智能和医学伦理。但在定义功利主义概念时存在一些冗余和过度解释。
DeepSeek 很好地涵盖了核心原则并包括历史背景,但它未能像其他两个代理那样深入探索批评。此外,该回应缺乏理论与现实问题之间的强烈主题联系。
获胜者:o3-mini 提供了最深入的回应,清晰明了,并与现代伦理问题相关。 Qwen 2.5 位居第二,解释得当,但结构和结论略弱。
7、城市规划

Prompt: "Design an integrated strategy to optimize urban transportation in a rapidly growing megacity. Your plan should address the following aspects.”提示:“设计一个综合战略来优化快速发展的特大城市的城市交通。你的计划应该解决以下方面。”
o3-mini 涵盖了优化城市交通所需的所有主要方面,具有智能参考、强大的逻辑流程和清晰的实施步骤。
Qwen 2.5 提供了结构良好的响应,并涵盖了大多数基本组件,并很好地利用了数据驱动的决策。然而,它缺乏强有力的全球案例研究,也没有强调实施阶段。
DeepSeek 包括深入的交通电气化计划,并重点关注交通中的公平性和性别安全。然而,聊天机器人在某些领域过于宽泛,缺乏对治理和长期未来保障的强烈关注。它的响应中也缺少一个明确的政策执行框架。
获胜者:o3-mini 凭借其执行路线图、创新、深度和现实性而获胜。Qwen 2.5 以强大但结构性略差的响应获得第二名。
8、总冠军:o3-mini
ChatGPT 的 o3-mini 成为这次聊天机器人对决中最全面、表现最稳定的聊天机器人。涉及各种挑战——包括编码、数学、历史分析、文学评论、哲学讨论和概率
问题解决 — o3-mini 反复展示了卓越的深度、清晰度、组织性和现实世界适用性。
03 mini 在细节与可读性之间取得平衡方面表现出色,提供了结构良好且富有洞察力的回答,将理论理解与实际意义融为一体。
虽然 DeepSeek R1 和 Qwen 2.5 各有优势 — DeepSeek 通常提供结构化但有些肤浅的回答,而 Qwen 2.5 展示了强大的编码技能和强大的道德分析 — 但它们都无法在所有测试领域中与 o3-mini 的多功能性相媲美。
值得注意的是,Qwen 2.5 凭借其注释良好的脚本和错误处理功能在编码挑战中胜过 o3-mini,而 DeepSeek 偶尔会在提供更全面但不太细致的回答时排名第二。
在七项挑战中的五项中,o3-mini 始终名列第一,事实证明,对于寻求深思熟虑、表达清晰且逻辑合理的答案的用户来说,o3-mini 是最平衡的 AI 模型。虽然这三种模型都能在各种任务中提供有价值的帮助,但 o3-mini 目前在这些免费聊天机器人选项中提供了最精致、最可靠的体验。
原文链接:I tested ChatGPT o3-mini vs DeepSeek R1 vs Qwen 2.5 with 7 prompts — here’s the winner
汇智网翻译整理,转载请标明出处
