Ollama简明教程
在这篇文章中,我们将了解如何使用 Ollama、如何在 Ollama 中创建自己的模型 以及如何使用 Ollama 构建聊天机器人。

这是深入研究 Ollama 的第一部分,以及我所学到的有关本地 LLM 的知识以及如何将它们用于基于推理的应用程序。在这篇文章中,你将了解——
- 如何使用 Ollama
- 如何在 Ollama 中创建自己的模型
- 如何使用 Ollama 构建聊天机器人
1、首先,一些背景
在本地 LLM 领域,我首先遇到了 LMStudio。虽然应用程序本身易于使用,但我喜欢 Ollama 提供的简单性和可操作性。要了解有关 Ollama 的更多信息,您可以访问此处。
Ollama 托管了你可以访问的模型的精选列表。你可以将这些模型下载到本地计算机,然后通过命令行提示符与这些模型交互。或者,当你运行模型时,Ollama 还会运行一个托管在端口 11434(默认情况下)的推理服务器,你可以通过与OpenAI兼容的 API 和其他库(如 Langchain)与其交互。
截至本文发布时,Ollama 有 74 个模型,其中还包括嵌入模型等类别。

2、如何使用 Ollama
为你选择的操作系统下载 Ollama。完成后,运行命令 ollama 以确认它正常运行。它应该会向你显示帮助菜单 —
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.要使用任何模型,你首先需要从 Ollama“拉取”它们,就像从 Dockerhub(如果您以前使用过)或 Elastic Container Registry (ECR) 之类的东西中拉取图像一样。
Ollama 附带一些默认模型(如 llama2,它是 Facebook 的开源 LLM),你可以通过运行如下命令查看:
ollama list 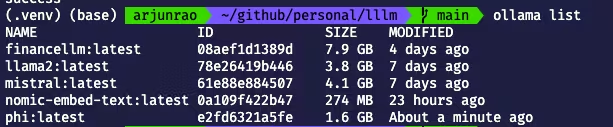
从 Ollama 模型库页面中选择你想要与之交互的模型(假设为 phi)。现在,你可以通过运行如下命令下载模型:
ollama pull phi 
下载完成后,你可以通过运行如下命令来检查模型是否在本地可用 -
ollama list现在模型可用,可以运行了。你可以使用如下命令运行模型:
ollama run phi答案的准确性并不总是一流的,但你可以通过选择不同的模型或自己进行一些微调或实施类似 RAG 的解决方案来解决这个问题,以提高准确性。
我上面演示的是如何使用命令行提示符使用 Ollama 模型。但是,如果你检查 Llama 正在运行的推理服务器,会发现可以通过访问端口 11434 来以编程方式访问它。
如果想使用 Langchain 访问你的 Ollama 模型,可以使用类似以下代码 —
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
prompt = "What is the difference between an adverb and an adjective?"
llm = Ollama(model="mistral")
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
response = qa(prompt)3、如何在 Ollama 中创建自己的模型
你还可以使用 Ollama 中的 Modelfile 概念创建自己的模型变体。有关在 Modelfile 中配置的更多参数,您可以查看这些文档。
示例模型文件 —
# Downloaded from Hugging Face https://huggingface.co/TheBloke/finance-LLM-GGUF/tree/main
FROM "./finance-llm-13b.Q4_K_M.gguf"
PARAMETER temperature 0.001
PARAMETER top_k 20
TEMPLATE """
{{.Prompt}}
"""
# set the system message
SYSTEM """
You are Warren Buffet. Answer as Buffet only, and do so in short sentences.
"""获得模型文件后,你可以使用以下命令创建模型:
ollama create arjunrao87/financellm -f Modelfile其中 financellm 是你的 LLM 模型的名称, arjunrao87 将替换为你的 ollama.com 用户名(它也充当你的在线 ollama 注册表的命名空间)。此时,你可以像使用 Ollama 上的任何其他模型一样使用你创建的模型。
你还可以选择将模型推送到远程 ollama 注册表。为此,你需要
- 在 ollama.com 上创建你的帐户
- 添加新模型
- 设置公钥以允许你从远程机器推送模型。
创建本地 llm 后,你可以使用 如下命令将其推送到 ollama 注册表:
ollama push arjunrao87/financellm🦄 现在,让我们进入精彩部分。
4、使用 Ollama 构建聊天机器人
在我使用 Ollama 的过程中,最令人愉快的发现之一是这个基于 Python 的 Web 应用程序构建生态系统。Chainlit 可用于构建像 ChatGPT 这样的成熟聊天机器人。正如他们的页面所述,
Chainlit 是一个开源 Python 包,用于构建可用于生产的对话式 AI
我浏览了一些 Chainlit 教程,以了解你可以用 chainlit 做什么,其中包括创建任务序列(称为“步骤”)、启用按钮和操作、发送图像以及各种事情。你可以在这里关注我旅程的这一部分。
一旦我掌握了 Chainlit,我就想组装一个简单的聊天机器人,它基本上使用 Ollama,这样我就可以使用本地 LLM 进行聊天(而不是说 ChatGPT 或 Claude)。
使用不到 50 行代码,你就可以使用 Chainlit + Ollama 做到这一点。这不是很疯狂吗?
Chainlit 作为一个库使用起来非常简单。我还使用 Langchain 来使用和与 Ollama 交互:
from langchain_community.llms import Ollama
from langchain.prompts import ChatPromptTemplate
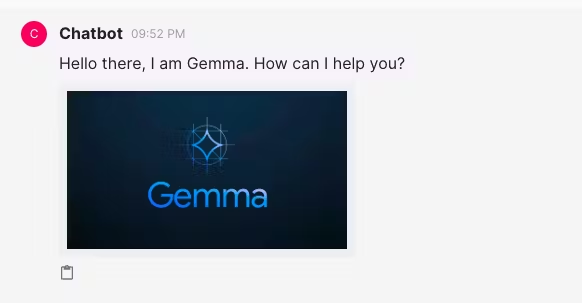
import chainlit as cl下一步是定义聊天机器人的加载屏幕看起来是什么样子,方法是使用 chainlit 的 @cl.on_chat_start 装饰器:
@cl.on_chat_start
async def on_chat_start():
elements = [cl.Image(name="image1", display="inline", path="assets/gemma.jpeg")]
await cl.Message(
content="Hello there, I am Gemma. How can I help you?", elements=elements
).send()
....
....Message 接口是 Chainlit 用于将响应发送回 UI 的接口。你可以使用简单的内容键构建消息,然后可以使用元素之类的东西对其进行修饰,在我的例子中,我添加了一个图像,以便在用户首次登录时显示图像。
下一步是调用 Langchain 来实例化 Ollama(使用你选择的模型),并构建提示模板。 cl.user_session 的用途主要是保持用户上下文和历史记录的分离,这只是为了运行快速演示,并不是严格要求的。
Chain 是一个名为 Runnable 的 Langchain 接口,用于创建自定义链。你可以在此处阅读更多相关信息:
@cl.on_chat_start
async def on_chat_start():
....
....
model = Ollama(model="mistral")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a knowledgeable historian who answers super concisely",
),
("human", "{question}"),
]
)
chain = prompt | model
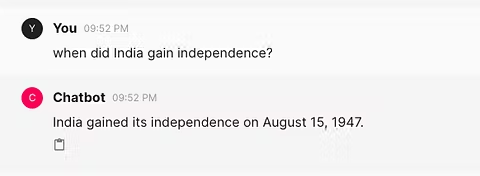
cl.user_session.set("chain", chain)现在,你已经拥有了聊天机器人 UI 和接受用户输入的所有要素。如何处理用户提供的提示?你将使用 Chainlit 中的 @cl.on_message 处理程序对用户提供的消息执行某些操作:
@cl.on_message
async def on_message(message: cl.Message):
chain = cl.user_session.get("chain")
msg = cl.Message(content="")
async for chunk in chain.astream(
{"question": message.content},
):
await msg.stream_token(chunk)
await msg.send()chain.astream 就像文档建议的那样“异步流回响应块”,这正是我们想要的机器人。
就是这样。一些导入、几个函数、一点点修饰,你就有了一个功能齐全的聊天机器人。

完整代码,你可以查看我的 GitHub。
原文链接:How to Use Ollama: Hands-On With Local LLMs and Building a Chatbot
汇智网翻译整理,转载请标明出处
