Ollama-OCR 简明教程

Llama 3.2-Vision 是一个多模态大型语言模型,有 11B 和 90B 两种大小,能够处理文本和图像输入以生成文本输出。该模型在视觉识别、图像推理、图像描述和回答与图像相关的问题方面表现出色,在多个行业基准测试中优于现有的开源和闭源多模态模型。
在本文中,我将介绍如何调用由 Ollama 运行的 Llama 3.2-Vision 11B 建模服务并使用 Ollama-OCR 实现图像文本识别 (OCR) 功能。
Ollama-OCR 的功能:
- 使用 Llama 3.2-Vision 模型进行高精度文本识别
- 保留原始文本格式和结构
- 支持多种图像格式:JPG、JPEG、PNG
- 可自定义的识别提示和模型
- Markdown 输出格式选项
- 强大的错误处理
1、环境安装
在开始使用 Llama 3.2-Vision 之前,需要安装 Ollama,这是一个支持在本地运行多模态模型的平台。按照以下步骤进行安装:
- 下载 Ollama:访问 Ollama 官方网站下载适用于你的操作系统的安装包。下载 Ollama
- 安装 Ollama:按照下载的安装包按照提示完成安装。
安装 Ollama 后,可以使用以下命令安装 Llama 3.2-Vision 11B 模型:
ollama run llama3.2-vision最后安装Ollama-OCR:
npm install ollama-ocr
# or using pnpm
pnpm add ollama-ocr2、Ollama-OCR快速上手
使用如下代码调用Ollama-OCR对指定的图像文件进行OCR处理,提取其中的文本:
import { ollamaOCR, DEFAULT_OCR_SYSTEM_PROMPT } from "ollama-ocr";
async function runOCR() {
const text = await ollamaOCR({
filePath: "./handwriting.jpg",
systemPrompt: DEFAULT_OCR_SYSTEM_PROMPT,
});
console.log(text);
}输入图像:

输出结果:
The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of instruction-tuned image reasoning generative models in 118 and 908 sizes (text + images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image. The models outperform many of the available open source and closed multimodal models on common industry benchmarks.翻译:Llama 3.2-Vision 多模态大型语言模型 (LLM) 集合是一组经过指令调整的图像推理生成模型,大小分别为 118 和 908(文本 + 图像输入/文本输出)。Llama 3.2-Vision 经过指令调整的模型针对视觉识别、图像推理、字幕和回答有关图像的一般问题进行了优化。这些模型在常见的行业基准上优于许多可用的开源和封闭多模态模型。
3、要求Ollama-OCR输出Markdown
在调用OllamaOCR时,通过指定 systemPrompt 可以要求输出Markdown文本:
import { ollamaOCR, DEFAULT_MARKDOWN_SYSTEM_PROMPT } from "ollama-ocr";
async function runOCR() {
const text = await ollamaOCR({
filePath: "./trader-joes-receipt.jpg",
systemPrompt: DEFAULT_MARKDOWN_SYSTEM_PROMPT,
});
console.log(text);
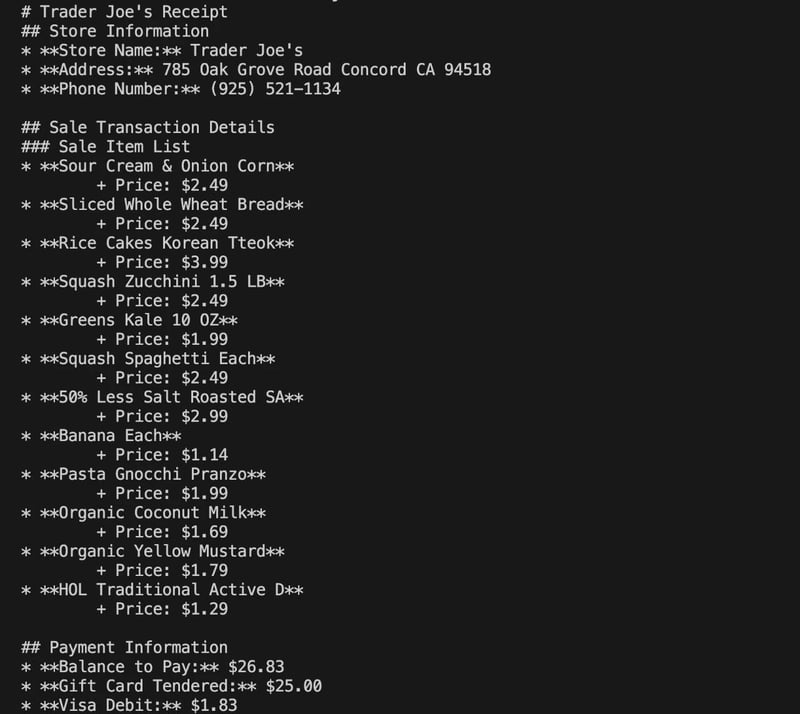
}输入图片:

输出结果:
4、使用 MiniCPM-V 2.6 Vision 模型
OllamaOCR也支持MiniCPM模型,如果需要提取图像中的中文文本,这很有用。
async function runOCR() {
const text = await ollamaOCR({
model: "minicpm-v",
filePath: "./handwriting.jpg.jpg",
systemPrompt: DEFAULT_OCR_SYSTEM_PROMPT,
});
console.log(text);
}ollama-ocr 使用本地视觉模型,如果您想使用在线 Llama 3.2-Vision 模型,请尝试 llama-ocr 库。
原文链接:Ollama-OCR for High-Precision OCR with Ollama
汇智网翻译整理,转载请标明出处
