OmniVision-968M 世界最小VLM
Omnivision 是一个紧凑的、不到1B (968M)参数 的多模态模型,用于处理视觉和文本输入,针对边缘设备进行了优化。

Omnivision 是一个紧凑的、不到1B (968M)参数 的多模态模型,用于处理视觉和文本输入,针对边缘设备进行了优化。它在 LLaVA 架构的基础上进行了改进,具有以下特点:
- 9 倍token减少:将图像token从 729 个减少到 81 个,从而缩短了延迟时间并降低了计算成本。
- 增强准确度:使用来自可靠数据的 DPO 训练减少幻觉。
Omnivision演示如下:
可以在HuggingFace Space在线尝试OmniVision:NexaAIDev/omnivlm-dpo-demo
1、本地运行 OmniVision
首先安装 Nexa SDK,然后在你的终端上运行此命令:
nexa run omnivision 或者使用 Streamlit 本地 UI 运行它:
nexa run omnivision -st注意:OmniVision FP16 版本需要 988 MB RAM 和 948 MB 存储空间。
2、模型架构
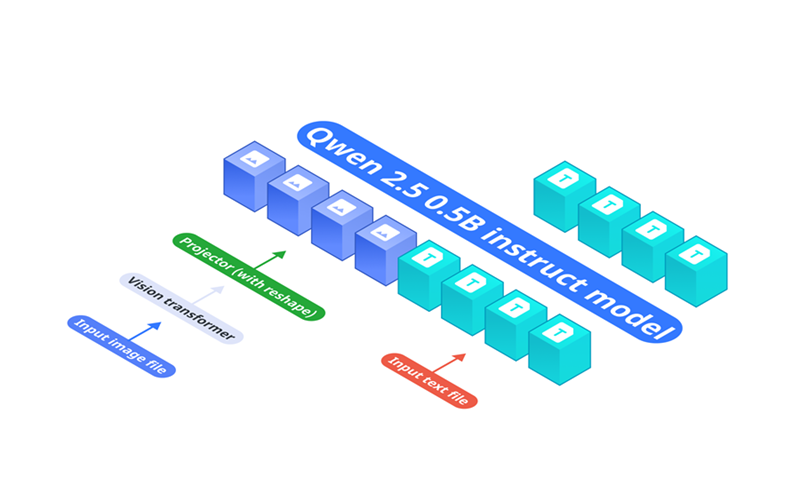
OmniVision 的架构由三个关键组件组成:
- 基础语言模型:Qwen2.5-0.5B-Instruct 用作处理文本输入的基础模型。
- 视觉编码器:SigLIP-400M 以 384 分辨率运行,使用 14×14 块大小来生成图像嵌入。
- 投影层:多层感知器 (MLP) 将视觉编码器的嵌入与语言模型的标记空间对齐。与 vanilla Llava 架构相比,我们设计了一个投影仪,可将图像标记减少 9 倍。
视觉编码器首先将输入图像转换为嵌入,然后由投影层处理以匹配 Qwen2.5-0.5B-Instruct 的标记空间,从而实现端到端的视觉语言理解。
3、训练方法
我们通过三阶段训练流程开发了 OmniVision:
- 预训练
初始阶段专注于使用图像-字幕对建立基本的视觉语言对齐,在此期间仅解冻投影层参数以学习这些基本关系。
- 监督微调 (SFT)
我们使用基于图像的问答数据集增强模型的上下文理解。此阶段涉及对包含图像的结构化聊天历史记录进行训练,以便模型生成更符合上下文的响应。
- 直接偏好优化 (DPO)
最后阶段通过首先使用基础模型生成对图像的响应来实现 DPO。然后,教师模型生成最少编辑的更正,同时保持与原始响应的高度语义相似性,特别关注准确性关键元素。这些原始和更正的输出形成选择-拒绝对。微调旨在在不改变模型核心响应特征的情况下实现必要的模型输出改进。
4、基准测试
下面我们展示了一个图表来展示 OmniVision 与 nanoLLAVA 的表现:
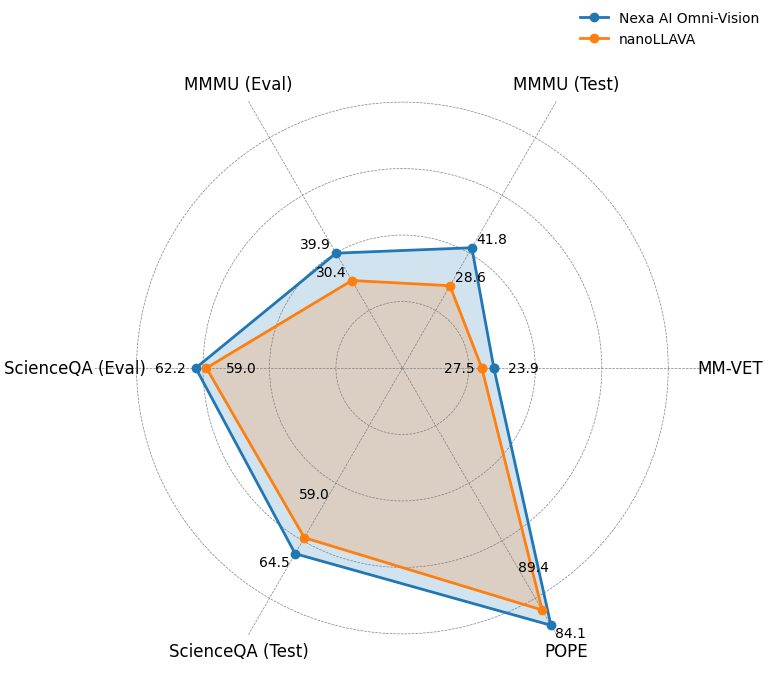
我们还对基准数据集进行了一系列实验,包括 MM-VET、ChartQA、MMMU、ScienceQA、POPE,以评估 Omnivision 的性能。
| Nexa AI Omni-Vision | nanoLLAVA | Qwen2-VL-2B | |
|---|---|---|---|
| MM-VET | 27.5 | 23.9 | 49.5 |
| ChartQA(测试) | 59.2 | N/A | 73.5 |
| MMMU(测试) | 41.8 | 28.6 | 41.1 |
| MMMU(评估) | 39.9 | 30.4 | 41.1 |
| ScienceQA(评估) | 62.2 | 59.0 | N/A |
| ScienceQA (测试) | 64.5 | 59.0 | N/A |
| POPE | 89.4 | 84.1 | N/A |
在所有任务中,OmniVision 的表现都优于 nanoLLAVA(之前世界上最小的视觉语言模型)。
5、下一步计划
Omnivision 处于早期开发阶段,我们正在努力解决当前的限制:
- 扩展 DPO 训练:在迭代过程中增加 DPO(直接偏好优化)训练的范围,以不断提高模型性能和响应质量。
- 提高文档和文本理解能力。
从长远来看,我们的目标是将 OmniVision 开发为针对边缘 AI 多模式应用的完全优化、可投入生产的解决方案。
原文链接:OmniVision-968M: World's Smallest Vision Language Model
汇智网翻译整理,转载请标明出处
