在MCP服务器中优化API输出
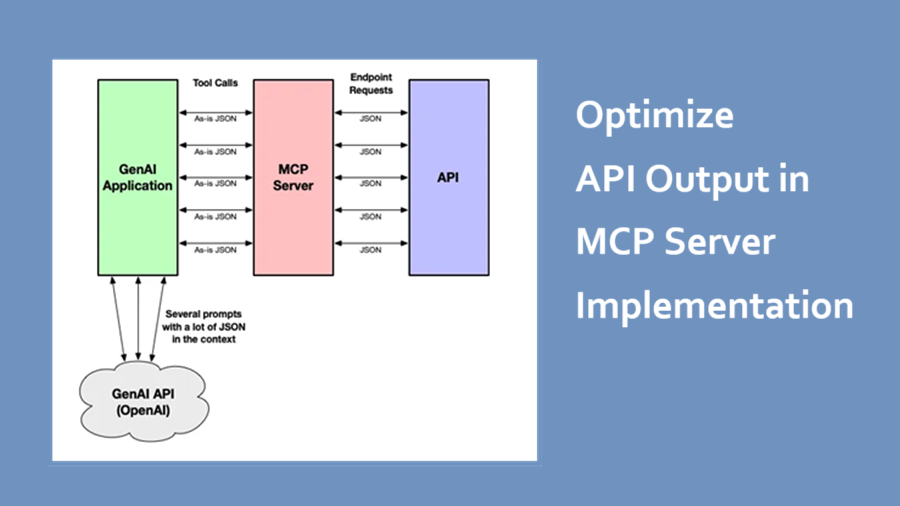
简单地说,很多在线API的设计并不是针对MCP Server的应用场景优化的,不能将在线API端点与MCP工具做一对一的简单映射。
当我第一次涉足生成式AI,我被“应用工具”(更早时通常称为“函数”)的技术所吸引。它使AI交互能够超越仅仅从训练中生成响应的能力。正是工具让我认识到生成式AI不仅仅是用来讲笑话或告诉我天空是蓝色的。它可以与应用程序数据交互并采取行动,真正完成任务。
但随后检索增强生成(RAG)成为生成式AI圈子中的热门话题。就像工具一样,RAG可以让大型语言模型(LLMs)回答超出其训练范围的问题。很长一段时间里,工具的地位让位于RAG,成为酷炫的生成式AI孩子们做的事情。
现在,随着自主AI成为关注的焦点,越来越明显的是,工具对于使代理能够采取行动和为我们获取信息至关重要。此外,模型上下文协议(MCP)提供了一种标准化的方式来创建工具模块,并在启用AI的应用程序之间共享这些模块。当然,也肯定存在将现有API包装为MCP服务器的需求,以弥合生成式AI与现有企业API之间的鸿沟。
MCP最近几个月一直在我的脑海中占据重要位置。而且,由于Spring AI现在支持开发MCP服务器和MCP客户端来消费这些服务器,我已经花了很多时间构建两者。在这个过程中,我犯了一些错误,学到了一些教训,现在想和大家分享其中的一个教训,这样你就可以最好地利用MCP。我已经犯了错误,所以你不必再犯。
1、背景故事
几年来,我一直使用一个有趣的API——ThemeParks.wiki API。这个API提供了世界各地主题公园的洞察信息,包括运营时间、景点等待时间以及表演时间等。我曾用它开发了一个Alexa技能,我自己在访问迪士尼世界和迪士尼乐园时通过Alexa移动应用程序使用过该技能。
ThemeParks.wiki API公开了几个端点:
- /destinations — 返回覆盖API的所有度假区的JSON列表。每个度假区条目都有子项,即该度假区内的主题公园。(例如,沃尔特·迪斯尼世界是一个度假区;魔法王国、未来世界、好莱坞影城和动物王国是该度假区内的主题公园。)
- /entity/{entityId} — 返回关于实体的高级详细信息,实体可以是度假区、主题公园、演出、景点、餐厅等。
- /entity/{entityId}/children — 返回属于某个实体的子项列表。这在实体是度假区或主题公园时最有用。对于主题公园来说,子项就是该公园内的景点、演出和餐厅。
- /entity/{entityId}/live — 返回关于实体的实时(例如,接近实时)信息。对于演出,这可能是当天的演出时间列表。对于景点,这将包括当前的等待时间。对于餐厅,这可能包括根据团队规模估算的步行等候时间。
- /entity/{entityId}/schedule — 返回实体的营业时间。对于主题公园,这包括从当前日期开始的一个月的营业时间,还有一些额外的信息(例如,支持快速通道入场的景点的可用时间)。
- /entity/{entityId}/schedule/{year}/{month} — 和前一个日程端点相同,但专注于特定月份(从该月的第一天开始)。
你可能会注意到,除了目的地端点外,所有其他端点都需要一个实体ID。但是这个ID从哪里来呢?对于主题公园,可以从目的地端点获得,尽管你需要在所有的JSON中找到特定端点所需的ID。对于景点,你可能需要先从主题公园的实体ID(从目的地获得)开始,然后向儿童端点发出请求以获取特定景点的实体ID,然后使用该ID向其他端点之一发出请求以获取你想了解的景点信息。
作为一名开发者,检查API并编写一些代码来提取所需信息并不困难。事实上,我在创建Alexa技能时不得不自己编写一部分这样的工作。虽然不难,但我确实需要显式地编写一系列操作来获取我需要的内容。并且缓存那些不变化的数据(如实体ID)使我避免多次访问API。
正如我说的,这是一个有趣且有用的API。我想象着构建一个MCP服务器,将API的功能作为工具暴露给LLM,使用户能够询问诸如“Epcot明天几点开门?”或“迪士尼乐园Space Mountain的等待时间是多少?”之类的问题。
所以我做了。这就是学到一些有趣经验的时候了。
2、简单/天真的尝试
我第一次尝试从ThemeParks.wiki API的端点创建MCP服务器时,只是简单地将每个端点作为一个工具来暴露。这种从端点到工具的1对1映射非常直接:使用Spring的RestClient在工具定义的上下文中向每个端点发出HTTP GET请求。没有太多复杂的东西。
使用Spring AI的新@Tool注解(目前在快照版本中,但很快将在里程碑6版本中可用),我首先创建了一个服务类,为每个端点定义了一个@Tool方法。看起来有点像这样:
@Service
public class ThemeParkService {
public static final String THEME_PARKS_API_URL = "https://api.themeparks.wiki/v1";
private final RestClient restClient;
public SimpleThemeParkService(
RestClient.Builder restClientBuilder) {
this.restClient = restClientBuilder
.baseUrl(THEME_PARKS_API_URL)
.build();
}
@Tool(name = "getDestinations",
description = "Get list of resort destinations, including their entity ID, name, and a child list of theme parks")
public String getDestinations() {
return sendRequestTo("/destinations");
}
@Tool(name = "getEntity",
description = "Get data for a park, attraction, or show given the entity ID")
public String getEntity(String entityId) {
return sendRequestTo("/entity/{entityId}", entityId);
}
@Tool(name = "getEntityChildren",
description = "Get a list of attractions and shows in a park given the park's entity ID")
public String getEntityChildren(String entityId) {
return sendRequestTo("/entity/{entityId}/children", entityId);
}
@Tool(name = "getEntitySchedule",
description = "Get a park's operating hours given the park's entity ID.")
public String getEntitySchedule(String entityId) {
return sendRequestTo("/entity/{entityId}/schedule", entityId);
}
@Tool(name = "getEntityScheduleForDate",
description = "Get a park's operating hours given the park's entity ID and a specific year and month.")
public String getEntitySchedule(
String entityId, String year, String month) {
return sendRequestTo("/entity/{entityId}/schedule/{year}/{month}",
entityId, year, month);
}
@Tool(name = "getEntityLive",
description = "Get an attraction's wait times or a show's show times given the attraction or show entity ID")
public String getEntityLive(String entityId) {
return sendRequestTo("/entity/{entityId}/live", entityId);
}
private String sendRequestTo(String path, Object... pathVariables) {
return restClient
.get()
.uri(path, pathVariables)
.retrieve()
.body(String.class);
}
}
然后,我用以下配置将这些方法作为工具暴露在一个MCP服务器中:
@Configuration
public class McpServerConfig {
public final SimpleThemeParkService themeParkService;
public McpServerConfig(SimpleThemeParkService themeParkService) {
this.themeParkService = themeParkService;
}
@Bean
public StdioServerTransport stdioTransport() {
return new StdioServerTransport();
}
@Bean
public McpSyncServer mcpServer(ServerMcpTransport transport) {
var capabilities = McpSchema.ServerCapabilities.builder()
.tools(true)
.build();
ToolCallback[] toolCallbacks = MethodToolCallbackProvider
.builder()
``` .toolObjects(themeParkService) // <-- 设置来自服务的工具
.build()
.getToolCallbacks();
return McpServer.sync(transport)
.serverInfo("主题公园MCP服务器", "1.0.0")
.capabilities(capabilities)
.tools(ToolHelper.toSyncToolRegistration(toolCallbacks))
.build();
}
}
并且,它确实有效。嗯……某种程度上有效。但并不总是。
当它有效时,速度很慢。而当它无效时,通常是因为我超出了OpenAI的每分钟令牌(TPM)速率限制。在增加日志记录并进行一些侦探工作后,我意识到虽然所有工具都已提供给LLM,并且有相当好的描述,但LLM在寻找某些项目的实体ID时遇到了困难。因此,它以一种反复试验的方式频繁调用这些工具来找到它想要的东西。
更重要的是,由于从目的地和时间表端点返回的JSON如此庞大,提示上下文被大量无关数据填满。例如,目的地端点返回API支持的所有度假区和主题公园。而时间表端点每个都会返回一整个月的时间表数据,即使你只需要一天的数据。因此,每次询问某个公园的开放或关闭时间时,我都会消耗大量的令牌。这不仅浪费,而且完全解释了为什么我经常受到TPM速率限制的打击。
我决定深入研究一下我在每次提问中实际使用了多少令牌,通过检查响应中返回的使用指标来实现这一点。我问了三次“Epcot明天几点开门?”。下表显示了每次提问所花费的令牌数量。
哇!难怪我经常超出速率限制。我使用的是GPT-4o模型,它的TPM限制是30,000。
不管速率限制如何,令牌是计算GenAI API账单的方式。使用GPT-4o时,这个实验让我花费了近42美分。这可能不多,但这只是3次互动。
当然,我可以(也确实)选择切换到GPT-4o-mini。这个模型显著便宜得多,TPM限制也高得多(每分钟200,000个令牌)。但这感觉像是把问题推到一边。我想看看核心问题是什么以及是否可以解决。
经过一番思考,核心问题变得非常清楚:
- 来自目的地端点的数据是以度假区为中心的,但大多数问题更关注主题公园。这让LLM更难为给定的主题公园找到实体ID。
- 目的地端点和时间表端点返回了大量的JSON,其中大部分与所提的问题无关。如果问题是关于Epcot,你不需要知道Six Flags Over Texas的实体ID。如果问题是关于明天的公园营业时间,你不需要知道任何日期之外的营业时间。
这两个问题结合起来解释了为什么每次提问要使用这么多令牌。23K-93K个令牌并不是一次性发送的——JSON虽然很大,但还没那么大。但在LLM努力寻找实体ID的过程中,将大量JSON作为上下文发送在多次提示中迅速累积起来。

一个API端点与MCP服务器工具的一对一映射可能会导致LLM在寻求所需信息时有更多的交互次数,并可能增加每次交互的令牌计数。
简单地说,ThemeParks.wiki API的设计并不是最优的,不能直接作为MCP服务器的基础。
曾有人建议我不必自己编写MCP服务器,而是利用ThemeParks.wiki API具有OpenAPI(注意这里的“P”)规范这一事实,使用预先构建的MCP服务器,该服务器可以神奇地将OpenAPI端点作为工具暴露在MCP服务器中。我尝试过这种方法,但由于OpenAPI MCP服务器以一对一的方式暴露每个端点的工具,并且没有过滤返回的数据,所以核心问题仍然存在。
一切都完了吗?ThemeParks.wiki API就不能用于创建高效的MCP服务器吗?可以。但需要对结果进行一些调整。
3、优化API
理想情况下,ThemeParks.wiki API应该被优化,提供更专注于特定主题公园、景点等的端点。但我们不应该急于责怪设计者造成我遇到的问题。该API是在MCP(甚至当前围绕GenAI的热潮)存在之前设计的。毫无疑问,通过一些调整,网络带宽可以得到节省,但典型使用情况(在GenAI领域之外)不受API当前设计的影响。只有在GenAI/MCP情况下才会感受到痛苦。
不幸的是,我对API的设计几乎没有控制权。虽然我可以向API的GitHub项目提交一些拉取请求,但这取决于项目所有者是否认为这些优化值得。我能做的优化API本身的事情很少。
但如果我无法优化API以供MCP使用,那么我当然可以优化MCP服务器如何使用它。这就是我所做的。
一个看似明显的优化是对目的地端点的结果进行缓存。这将避免不必要的重复访问API以获取相同的数据,这些数据不常变化。但这对减少令牌使用毫无帮助。
接下来,我将来自目的地端点的JSON反转,使其不再是以度假区为主题公园的子节点结构,而是以主题公园为顶级项目,包含度假区的实体ID和名称属性。这使得LLM更容易筛选数据以找到给定主题公园的实体ID。
然后,我编写了一些代码来过滤反转后的数据,通过主题公园的名称来搜索条目。当然,这并不完美。尽管过滤器将名称标准化为小写并搜索子字符串(因此“动物王国”会匹配“迪士尼动物王国”),但如果请求的主题公园名称有拼写错误(例如,“Disbeyland”不会匹配“Disneyland”),效果就不那么好了。但总体来说,它工作得很好。我已经开始思考如何克服这些不足之处,但现在我对它的表现感到满意。
所有这些工作最终体现在一个新的getParksByName()方法中,取代了原来的getDestinations()方法。新方法如下所示:
@Tool(name = "getParksByName",
description = "根据主题公园名称或度假区名称获取主题公园列表(包括名称和实体ID)")
public List<Park> getParksByName(String parkName) throws JsonProcessingException {
return getParkStream(
park -> park.name().toLowerCase().contains(parkName.toLowerCase())
|| park.resortName().toLowerCase().contains(parkName.toLowerCase()))
.collect(Collectors.toList());
}
private Stream<Park> getParkStream(Predicate<Park> filter) {
DestinationList destinationList = restClient.get()
.uri("/destinations")
.retrieve()
.body(DestinationList.class);
return Objects.requireNonNull(destinationList).destinations.stream()
.flatMap(destination -> destination.parks().stream()
.map(park ->
new Park(park.id(), park.name(), destination.id(), destination.name())
)
.filter(filter));
}
下一个最明显的优化是单独提取某个实体在特定日期的日程安排。我首先从工具中移除了基本的日程安排端点,只使用接受年份和月份作为URL参数的端点。我更改了工具定义以接受“yyyy-MM-dd”格式的日期,从中提取年份和月份来向API发出请求。但我还使用日期来过滤返回的JSON,将其缩小到特定日期,而不是一整个月的日程信息。
新的getEntitySchedule()方法现在看起来像这样:
@Tool(name = "getEntityScheduleForDate",
description = "根据主题公园的实体ID和特定日期(格式为yyyy-MM-dd)获取主题公园的营业时间。")
public List<ScheduleEntry> getEntitySchedule(String entityId, String date) { // <5>
String[] dateSplit = date.split("-");
String year = dateSplit[0];
String month = dateSplit[1];
Schedule schedule = restClient.get()
.uri("/entity/{entityId}/schedule/{year}/{month}",
entityId, year, month)
.retrieve()
.body(Schedule.class);
return schedule.schedule().stream()
.filter(scheduleEntry -> scheduleEntry.date().equals(date))
.toList();
}
我还删除了只接受实体ID作为参数的getEntitySchedule()方法。不仅看起来多余,我还注意到,如果保留它,LLM仍然偶尔会请求调用它,这意味着大量未过滤的JSON被添加到提示上下文中。
请注意,在这两种情况下,方法现在返回Park或ScheduleEntry的List,而不是充满JSON的String。虽然最初的String响应已经足够,但领域类型使过滤和操作变得更容易。无论如何,结果最终作为JSON出现在提示上下文中,因此选择String还是领域特定类型对整体性能影响微乎其微。

通过过滤来自API的响应,并不总是暴露所有端点作为工具,LLM能够在较少的提示中找到所需的数据,并且携带在提示上下文中的JSON要小得多。
在我的MCP服务器实现中进行了这些更改后,我再次尝试了一切。结果非常出色!我得到了所有问题的好答案,通常比以前更快,并且从未达到速率限制!
但底线是什么?经过这些优化后,每个问题使用了多少令牌?下表显示了令牌使用量的显著减少。
哇!通过调整API的结果以更专注于典型用例并减少在提示上下文中传递的JSON数量,提示令牌的数量减少了约93%-98%。即使在GPT-4o的价格下,三次尝试总共也只花费了一分多钱。而使用GPT-4o-mini,它甚至只有几分钱。
4、收获
我的MCP服务器肯定还有进一步优化的机会。我甚至没有碰getEntity()、getEntityLive()或getEntityChildren()方法。优化这些方法无疑可以帮助减少其他用例的令牌消耗,例如询问某个景点的当前等待时间。但不可否认的是,我所做的初始改进对询问公园营业时间时的令牌使用量产生了重大而积极的影响。
虽然使用预构建的OpenAPI MCP服务器会是一种轻松集成API的方式,但如果不回到API本身并在那里应用优化,就无法获得相同的结果。
关键收获是,随着GenAI、Agentic AI和MCP的采用和应用不断增加,人们将希望与现有的API集成以解决问题。很有可能这些现有的API在设计时并没有考虑到它们可能被用作提供给LLM的工具。
为您的API提供OpenAPI规范是一件好事。并且使用OpenAPI MCP服务器将API的端点作为工具暴露出来也很有吸引力,因为它简单易行。但在这样做之前,最好考虑API返回的数据对令牌使用的影响,并寻求优化API本身或优化API在自定义MCP服务器实现中的使用方式。如果您不这样做,您可能会发现您的结果——以及您的GenAI API账单——可能不如预期理想。
原文链接:Optimizing API Output for Use as Tools in Model Context Protocol (MCP)
汇智网翻译整理,转载请标明出处
