使用AI友好的文档优化LLM响应
你是否曾经在大型语言模型完全误解你的编码问题时感到沮丧?我们都有过这样的经历。事实是,LLMs就像我们的开发同事一样——它们的帮助质量很大程度上取决于我们提供的上下文。

你是否曾经在大型语言模型完全误解你的编码问题时感到沮丧?我们都有过这样的经历。事实是,LLMs就像我们的开发同事一样——它们的帮助质量很大程度上取决于我们提供的上下文。
可以这样想:你不会在没有分享相关代码的情况下向同事寻求复杂错误的帮助,LLMs也需要适当的上下文才能给你最好的建议。这就是AI友好的文档发挥作用的地方,我想分享我在为Angular创建这些文档时学到的东西。
1、获取更好上下文的探索
这启发了我开始收集AI友好的文档。以下是一些值得注意的例子:
- 模型上下文协议:https://modelcontextprotocol.io/llms-full.txt 提供完整的文档在一个文件中
- Daisy UI v5:https://daisyui.com/llms.txt 提供全面的文档和组件特定版本
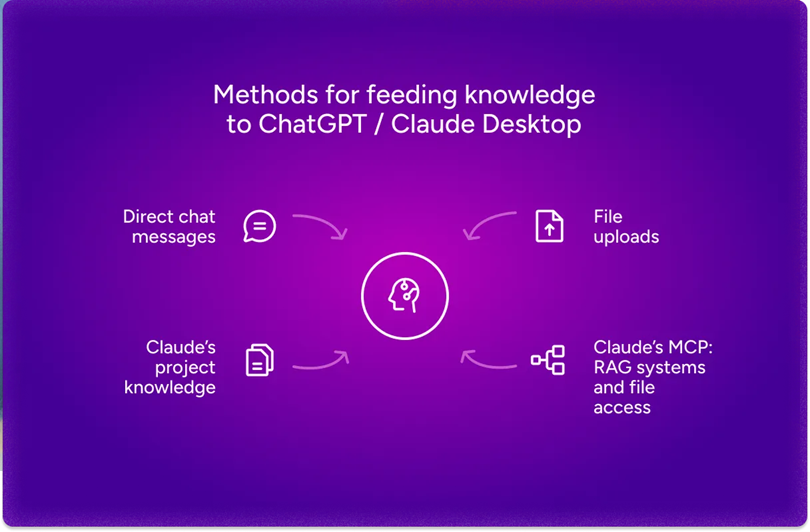
有几种方法可以将这些知识传递给你的AI助手:
- 将文档直接作为聊天消息发送给LLM
- 将相关文件上传到对话中
- 使用检索增强生成(RAG)系统智能地获取信息
作为这个探索的一部分,我已经为Angular创建了AI友好的文档,你可以在这里找到:https://github.com/gergelyszerovay/ai-friendly-docs/
2、超越基本文件上传
虽然大多数聊天界面允许你上传文件,但Claude Desktop更进一步,具有其项目知识功能。它允许你提供文档、代码和其他材料,Claude可以在对话中引用这些内容。凭借200,000个令牌的巨大上下文窗口(大约500页文本),Claude可以对复杂项目保持更深的理解,使其响应显著更准确。
顺便说一下,上下文窗口本质上是一个LLM在一次对话中“记住”的信息量——可以把它想象成AI的工作记忆。它是以令牌的形式衡量的,LLMs处理的基本单位(大致对应于单词片段)。例如,“我喜欢用TypeScript编程”这句话可能会被分解成“我”、“喜欢”、“程序”、“ming”、“在”、“Type”、“Script”等令牌。上下文窗口越大,LLM在生成响应时可以考虑的信息就越多。
3、RAG系统的魔力
RAG(检索增强生成)是这些上下文感知AI交互背后的力量。与其简单地将所有信息倒入模型,RAG系统会智能地检索与你的具体问题最相关的部分。
这就像有一个有用的图书管理员而不是被递给一堆书——图书管理员知道在哪里找到你需要的信息。当你的文档有清晰的标题和组织良好的章节时,检索系统可以更精确地定位相关信息。
在幕后,RAG系统通过将你的文档转换为向量嵌入——捕捉语义意义的数值表示来工作。当你提问时,系统会将其转换为相同的格式,并找到文档中最相似的部分。很酷,对吧?
如果你们对设置自己的系统感兴趣,我会在即将发表的文章中深入探讨RAG系统,敬请期待。
4、构建更好的Angular文档
我发现以下原则在创建AI友好的文档时最有帮助:
- 创建一个包含整个框架或库文档的综合单文件,以便在需要广泛知识时使用
- 开发单独的、专注于特定功能的文件,可以在需要针对性信息时单独包括
- 维护清晰的标题结构,以帮助AI系统理解不同文档部分之间的关系
我已经将这些想法应用于我的Angular文档项目。从官方Angular文档开始,我创建了一个综合的angular-full.md文件和位于sections目录中的各个功能特定文件。这种方法为你提供了灵活性,可以根据需要向AI助手提供上下文。
5、清晰标题结构的重要性
第三个原则(维护清晰的标题结构)特别值得关注,因为它极大地影响了AI系统浏览文档的能力。
让我用Angular文档中的一个例子来说明这一点。原始文件guide/components/inputs.md开头如下:
# 接受数据的输入属性
提示:本指南假定你已经阅读了[基础知识指南](essentials)。如果你是Angular的新手,请先阅读该指南。
提示:如果你熟悉其他Web框架,输入属性类似于_props_。
当你使用组件时,通常希望传递一些数据。组件通过声明**输入**来指定接受的数据:
// ...
仅从文件名和内容来看,很难立即明白此文档解释了Angular组件架构中的输入属性。
在我的AI友好的版本guide-components.md中,我添加了一个额外的标题,提供了这个关键上下文:
# 组件指南
// ...
## 接受数据的输入属性
提示:本指南假定你已经阅读了[基础知识指南](essentials)。如果你是Angular的新手,请先阅读该指南。
提示:如果你熟悉其他Web框架,输入属性类似于_props_。
当你使用组件时,通常希望传递一些数据。组件通过声明**输入**来指定接受的数据:
// ...
这种分层结构帮助AI系统理解输入属性是Angular组件的一个子主题。这对于检索系统来说尤为重要,因为它们可能会提取文档的部分内容,帮助AI正确地将信息框定在Angular的组件架构内。
6、关于上下文大小的战略思考
我学到的一个宝贵经验是,在向AI提供上下文时要深思熟虑。
发送整个angular-full.md文件并不总是最佳选择。例如,如果你正在处理Angular组件,最好只包括sections/guide-components.md以及一些相关的文件,如guide-templates.md或guide-di.md。
这种方法有助于AI专注于最重要的内容,而不会被无关的文档分散注意力。有时候,对于上下文而言,少即是多。
7、实例演示:一个真实案例
让我们看一个简单的问题:“Angular中的独立组件默认值是什么?”
这是一个有趣的情况,因为在Angular 19.0.0之前,默认情况下独立选项为false,但在版本19中改为true。我用不同的LLMs测试了这个问题,提供了不同程度的文档上下文。
ChatGPT(GPT-4o)
测试1:未提供文档
🧑: Angular中的独立组件默认值是什么?
🤖: 不,独立组件不是Angular中的默认设置。默认情况下,
Angular组件属于NgModules,这意味着它们必须在@NgModule中声明。
然而,Angular在Angular 14中引入了独立组件,允许组件没有在 `@NgModule` 内被声明的情况下工作。相反,它们在装饰器中使用了 `standalone: true` 标志。
这个响应已经过时且缺乏对 Angular 19 更改的认识:这正是上下文很重要的一个完美例子。
测试 2:完整的 Angular 文档已添加
🧑: 独立组件在 Angular 中是默认的吗?
🤖: 不,在 Angular 中独立组件不是默认的,但它们被鼓励作为一种简化应用程序构建的方式。在 Angular 版本 19.0.0 之前,standalone 选项默认为 false,这意味着组件默认是 NgModule 的一部分。然而,较新的 Angular 版本允许开发人员以增量方式迁移现有应用程序到独立模式,而不会产生破坏性更改。
好多了!模型正确地识别了版本截止点,尽管它仍然有点犹豫是否明确表示从 v19+ 开始它们已成为默认值。
测试 3:仅添加了 guide-components.md
🧑: 独立组件在 Angular 中是默认的吗?
🤖: 是的,在 Angular 中,组件默认是独立的。这意味着您可以直接将它们添加到其他组件的 imports 数组中,而无需 NgModule。但是,使用旧版本 Angular 创建的组件可能在其 `@Component` 装饰器中具有 `standalone: false`,需要它们成为 NgModule 的一部分。
重要提示:在 Angular 版本 19.0.0 之前,standalone 选项默认为 false。
非常完美!通过提供针对性的文档,我们得到了最准确和自信的答案。
这些示例突显了适当文档上下文对于准确 AI 响应的重要性。当询问不同的 LLM 这个问题而没有提供文档上下文时,你经常会得到听起来合理但可能不反映最新更新的回答。LLM 使用的是其训练数据,而这可能是过时或不完整的。
然而,当你提供相关部分的 Angular 文档时,响应会发生显著变化。这就像问一个去年最后一次使用 Angular 的开发者与一个每天都在使用最新版本的开发者之间的区别。
8、在代码上下文中添加更多内容
文档只是拼图的一部分。对于真正有效的 AI 辅助开发任务,通常需要同时提供代码和文档。
如果你希望优化源代码以供 AI 消费,请查看 Repomix ( https://repomix.com/ )。这是一个很棒的工具,可以帮助将整个代码库整合成一个单一的、AI 友好的文件。
Repomix 处理令牌计数管理(这对于保持在上下文限制内至关重要)、排除敏感信息,并生成各种格式的输出。它是 AI 友好文档的理想伴侣,当你需要同时提供文档和代码上下文时。
9、AI 友好文档与网络检索
既然许多 LLM 现在可以访问网络,为什么还要创建 AI 友好文档呢?
虽然网络访问无疑是有价值的,但它存在几个局限性,与精心策划的文档相比:
- 版本特定性:网络搜索可能会返回不同版本框架或库的信息,而不是你正在使用的版本。AI 友好文档可以专门为你的确切版本创建,消除混淆和不一致性。
- 准确性控制:网络内容的质量和准确性差异很大。经过策划的文档确保 LLM 使用经过验证的可靠信息,而不是潜在的过时或错误的来源。
- 上下文连贯性:当 LLM 从多个网络来源检索信息时,它必须协调可能冲突的信息。精心策划的文档提供了统一、连贯的上下文,从而导致更一致的响应。
- 减少幻觉:有了清晰全面的文档,LLM 就不太可能“填补空白”并做出错误假设,从而减少幻觉并提高准确性。
例如,在我们前面关于 Angular 独立组件的测试案例中,网络搜索可能会返回来自各种来源的不同版本信息。然而,我们的精心策划的文档清楚地指出了 Angular 19 的版本特定更改,从而产生了更准确的响应。
10、展望未来
我们探讨了如何通过 AI 友好文档显著提高 LLM 的响应质量。我在 Angular 文档和工具(如 Repomix)方面的经验得出的关键结论是,专门针对 AI 消费结构化信息会产生显著更好的结果。
基于我的经验,有两种主要方法可以增强 AI 能力:
上下文增强:这是我们在这篇文章中讨论的内容——通过精心结构化的文档和代码提供额外上下文。这种方法适用于现有的模型,为其提供更好的信息。
工具集成:AI 协助的下一步发展通过标准化集成方法实现,特别是由 Anthropic 开发的 Model Context Protocol (MCP)。MCP 是一种规范,定义了 AI 模型如何以标准化方式与外部工具通信。与早期每个 AI 服务都有自己的定制集成方法不同,MCP 提供了一种工具定义、调用和响应的通用语言。
这两种方法相辅相成:更好的文档帮助 LLM 理解应该使用哪些工具,而集成工具扩展了它们的能力。我目前正在开发利用 MCP 的 RAG 工具,并将在即将发布的文章中分享这些进展。
原文链接:Getting Better LLM Responses Using AI-Friendly Documentation
汇智网翻译整理,转载请标明出处
