MODEL-ZOO 3个DeepSeek-R1平替推理模型 人工智能在逻辑推理、问题解决和可解释性方面正在迅速发展。虽然 DeepSeek 的 R1 引起了关注,但它并不是唯一在推理任务中表现出色的免费 AI 模型。
APPLICATION 在.Net应用中集成DeepSeek-R1 本文将引导你了解如何在 GitHub Models 上将 Microsoft.Extensions.AI (MEAI) 库与 DeepSeek R1 结合使用,以便你今天就可以开始尝试使用 R1 模型。
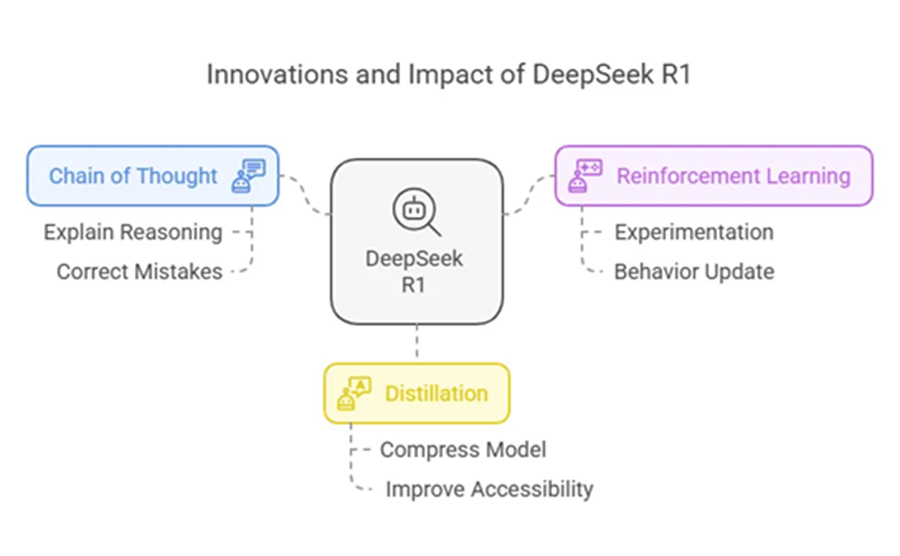
TOOL 用Unsloth训练自己的R1推理模型 DeepSeek 的 R1 研究揭示了一个“顿悟时刻”,其中 R1-Zero 通过使用群组相对策略优化 (GRPO) 自主学习分配更多思考时间而无需人工反馈。你就可以使用 Unsloth和Qwen2.5 (1.5B) 在仅 7GB 的 VRAM 上重现 R1-Zero 的“顿悟时刻”。
MODEL-ZOO VPTQ低位LLM量化算法 在 MMLU 等任务上,使用 VPTQ 的 2 位量化几乎实现了与原始 16 位模型相当的性能。此外,它能够在单个 GPU 上运行 Llama 3.1 405B,同时使用的内存比 70B 模型少!
APPLICATOIN CodeGPT集成DeepSeek-R1 本指南将向你展示如何在本地安装和运行 DeepSeek、使用 CodeGPT 对其进行配置以及开始利用 AI 来增强你的软件开发工作流程,所有这些都无需依赖基于云的服务。
MODEL-ZOO DeepSeek R1 vs. V3:如何选择? 在手机或桌面上使用 DeepSeek 应用程序时,我们可能会不确定何时选择 R1(也称为 DeepThink),而不是日常任务的默认 V3 模型。
MODEL-ZOO Gemini 2.0 Flash vs. DeepSeek R1 当我第一次看到 Google Gemini 的价格时,我打算将它与精简版、性能较弱的 R1 型号进行对比。我完全不相信即如此便宜的模型会如此强大。
MODEL-ZOO DeepSeek-R1的推理能力分析 DeepSeek 提出了一个模型,该模型的推理能力可与 OpenAI-o1 相媲美,尽管其参数只是 OpenAI-o1 的一小部分,训练成本也低得多。
MODEL-ZOO DeepSeek GRPO vs. OpenAI RLHF DeepSeek使用简单的强化学习(GRPO)来训练像 DeepSeek-R1 这样的 LLM,本文将尝试了解GRPO与OpenAI使用的RLHF强化学习有何不同。
LIBRARY DeepSeek GRPO Trainer简明教程 GRPO 是一种在线学习算法,这意味着它通过在训练期间使用训练模型本身生成的数据来迭代改进。GRPO 目标背后的直觉是最大化生成的完成的优势,同时确保模型接近参考策略。
MODEL-ZOO 蒸馏DeepSeek-R1到自己的模型 在本博客中,我们将介绍如何使用LoRA等技术将 DeepSeek-R1 的推理能力蒸馏到较小的模型(如 Microsoft 的 Phi-3-Mini)中。
MODEL-ZOO DeepSeek-R1本地运行成本 DeepSeek 将这场生成竞赛提升到了另一个水平,人们甚至准备在本地运行 671B 参数。但在本地运行如此庞大的模型可不是开玩笑;你需要在硬件方面取得一些重大进步,才能尝试推理。