PaliGemma 2微调实现JSON提取
本教程将演示如何使用 Google Colab 微调 PaliGemma 2 以从 JSON 格式的图像中提取数据

Google 于 2024 年 12 月 5 日发布的 PaliGemma 2 是今年早些时候推出的 PaliGemma 视觉语言模型 (VLM) 的更新和显著增强版本。
本教程将演示如何使用 Google Colab 微调 PaliGemma 2 以从 JSON 格式的图像中提取数据。我们还将提供一些针对其他视觉语言任务进行微调的技巧。让我们开始吧!
1、什么是 PaliGemma 2?
PaliGemma 2 将 SigLIP-So400m 视觉编码器与 Gemma 2 语言模型相结合,以处理图像和文本。SigLIP-So400m 编码器以各种分辨率(224px、448px 或 896px)处理图像并输出一系列图像标记。然后将这些标记线性投影并与输入文本标记组合。
最后,Gemma 2 语言模型(大小从 2B 到 27B 个参数不等)处理这些组合的标记并自回归生成输出文本标记。
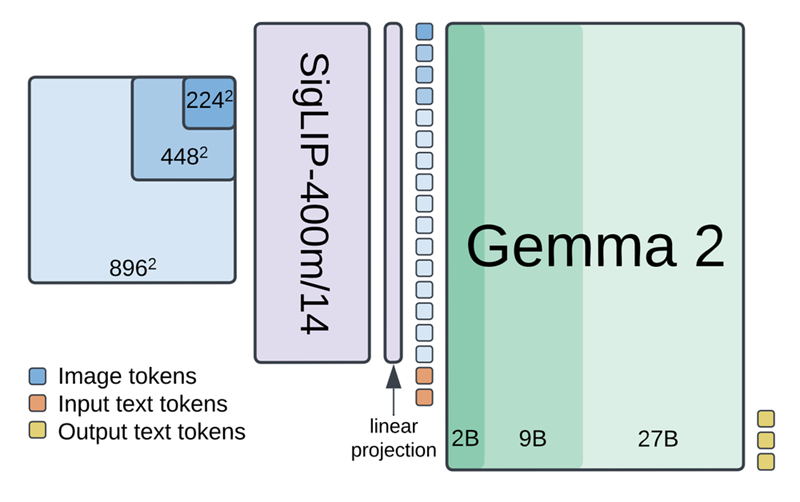
该架构使 PaliGemma 2 能够针对各种任务进行微调,包括字幕、视觉问答 (VQA)、光学字符识别 (OCR)、对象检测和实例分割。
2、多模态数据标注
对于此示例,我们将训练 PaliGemma 2 来分析托盘清单,这些文档提供有关托盘上货物内容的详细信息。我们使用 50 份这样的文档来创建此数据集,将 30 份分配给训练集,10 份分配给验证集,10 份分配给测试集。

训练集中的文档被打印出来,然后以不同的角度、不同的光照条件和不同程度的损坏进行拍照。训练集中的每个文档被使用了 5 次,从而在训练集中产生了 150 张图像。测试集和验证集中的每个文档都被拍摄了一次,但在不同的光照条件下,损坏程度也不同。
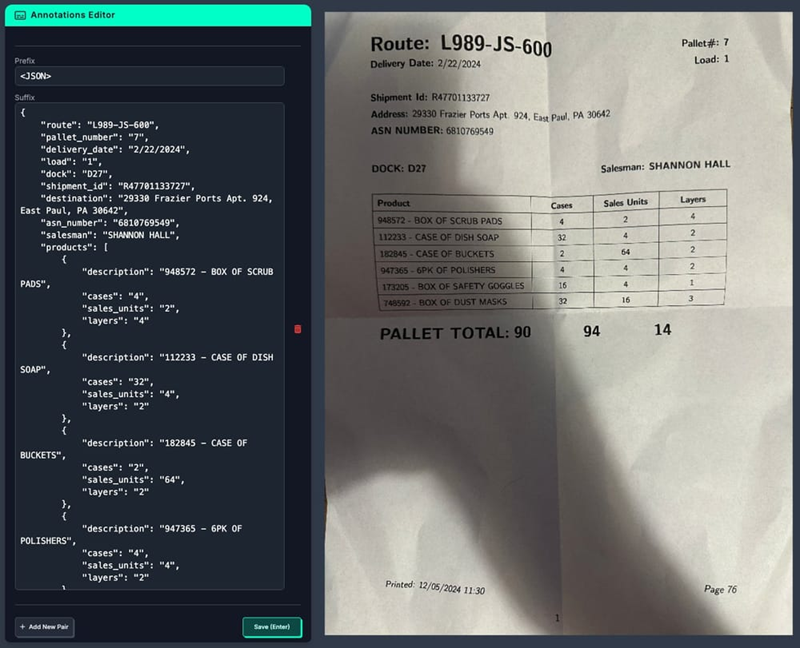
然后将照片上传到 Roboflow,我们在那里创建了一个多模态项目并进行了标注。此时的标签是一个字符串,表示有效的 JSON,其中包含在文档中找到的所有信息,例如路线 ID、装运 ID、送货地址和产品清单。
3、以 PaliGemma 2 格式下载数据集
我们准备的数据集可以使用 roboflow 包从 Roboflow Universe 下载。
pip install roboflowfrom roboflow import Roboflow
rf = Roboflow(api_key=ROBOFLOW_API_KEY)
project = rf.workspace("roboflow-jvuqo").project("pallet-load-manifest-json")
version = project.version(2)
dataset = version.download("jsonl")下载的数据集具有以下结构:
pallet-load-manifest-json/
├── train/
│ ├── train_image_1.png
│ ├── train_image_2.png
│ ├── ...
│ └── annotations.jsonl
├── test/
│ ├── test_image_1.png
│ ├── test_image_2.png
│ ├── ...
│ └── annotations.jsonl
└── valid/
├── valid_image_1.png
├── valid_image_2.png
├── ...
└── annotations.jsonl下载的数据集包括三个子集:训练、测试和有效。每个子集包含图像和一个 annotations.jsonl 文件。无论任务是什么,每个数据集都应以 JSONL 格式准备,其中文件的每一行都是一个有效的 JSON 对象。
每个 JSON 对象都有三个键:图像、前缀和后缀。图像键保存与数据条目关联的图像文件的名称。前缀键包含将发送到 PaliGemma2 的提示,而后缀键存储预期的输出。
4、JSONL 数据集加载器
要在训练期间使用我们的数据集,我们需要加载它。我们将基于 PyTorch Dataset 类构建一个 JSONLDataset 类,实现所需的方法。
import os
import json
from PIL import Image
from torch.utils.data import Dataset
class JSONLDataset(Dataset):
def __init__(self, jsonl_file_path: str, image_directory_path: str):
self.jsonl_file_path = jsonl_file_path
self.image_directory_path = image_directory_path
self.entries = self._load_entries()
def _load_entries(self):
entries = []
with open(self.jsonl_file_path, 'r') as file:
for line in file:
data = json.loads(line)
entries.append(data)
return entries
def __len__(self):
return len(self.entries)
def __getitem__(self, idx: int):
if idx < 0 or idx >= len(self.entries):
raise IndexError("Index out of range")
entry = self.entries[idx]
image_path = os.path.join(
self.image_directory_path, entry['image'])
image = Image.open(image_path).convert("RGB")
return image, entry最后,我们分别初始化三个子数据集:
train_dataset = JSONLDataset(
jsonl_file_path=f"{dataset.location}/train/annotations.jsonl",
image_directory_path=f"{dataset.location}/train"
)
valid_dataset = JSONLDataset(
jsonl_file_path=f"{dataset.location}/valid/annotations.jsonl",
image_directory_path=f"{dataset.location}/valid"
)
test_dataset = JSONLDataset(
jsonl_file_path=f"{dataset.location}/test/annotations.jsonl",
image_directory_path=f"{dataset.location}/test"
)5、选择 PaliGemma 2 基线检查点
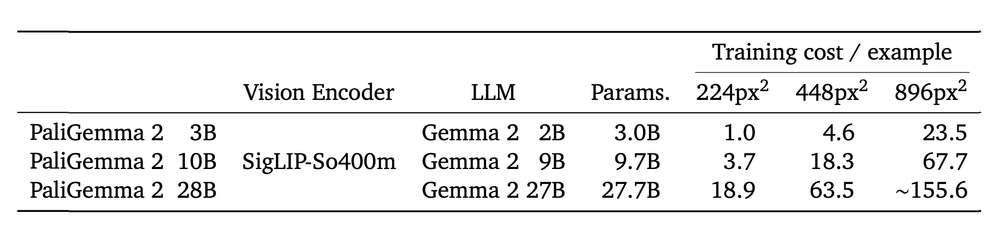
PaliGemma 2 提供 9 个预训练模型,大小分别为 3B、10B 和28B 参数,分辨率为 224px、448px 和 896px 像素。选择合适的基线检查点对于实现最佳性能至关重要,并且取决于几个关键因素:
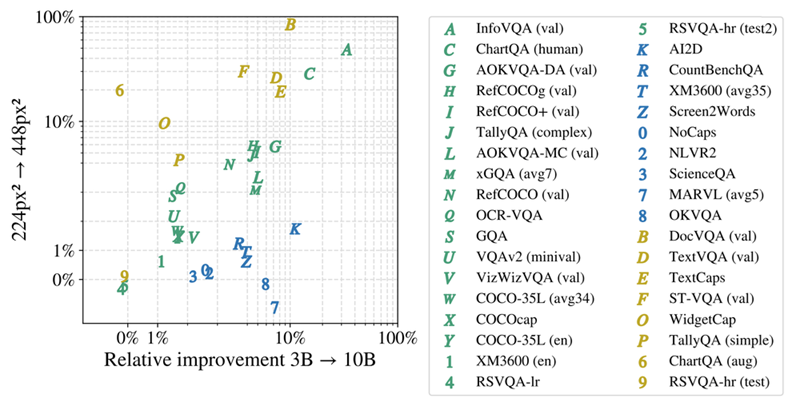
- 特定的视觉语言任务:对于涉及文本、文档、图表或屏幕理解的任务,如 ST-VQA、TallyQA、TextCaps 和 TextVQA,优先考虑更高分辨率的检查点(448px 或 896px)。这些任务受益于增强的视觉细节。如果您的任务需要复杂的推理或多语言能力,请选择具有更大语言模型(10B 或 28B)的检查点,即使它涉及使用较低的分辨率。
- 可用硬件:下表提供了对各种模型大小和分辨率的相对训练成本的见解。增加任何一个因素都会显著增加计算需求。选择与你的硬件功能相符的检查点。
- 你拥有的数据量:较大的语言模型通常需要更多数据才能进行有效微调。如果你的数据集有限,从较小的模型开始可能更合适。
6、PaliGemma 2 内存优化
微调像 PaliGemma 2 这样的大型视觉语言模型可能会耗费大量资源。从这个角度来看,最近的 YOLOv11 对象检测模型 (YOLOv11x) 的最大变体有 5690 万个参数。相比之下,PaliGemma 2 模型的参数范围从 3B 到 28B,这使得它们明显更大,训练起来也更困难。采用内存优化技术对于降低与高端硬件相关的成本至关重要。以下是一些需要考虑的策略:
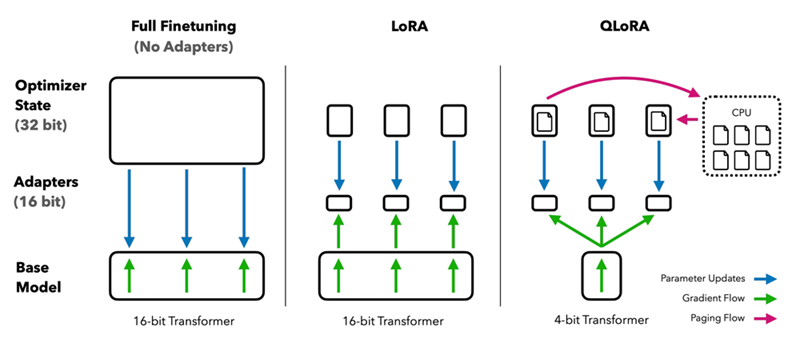
6.1 LoRA(低秩自适应)
LoRA 是一种使大型语言模型的微调更高效的技术。LoRA 不会调整模型中的所有参数,而是专注于优化一组较小的参数。
LoRA 向表示模型权重的大矩阵添加了一个较小的矩阵。这个较小的矩阵更容易训练,并且需要的内存更少。通过仅调整这个较小的矩阵,LoRA 可以有效地微调模型,同时显着减少训练期间的内存占用。
这种方法通常可以实现接近完全微调的性能,其中所有参数都经过调整,但内存使用量要少得多。
6.2 QLoRA(量化 LoRA)
QLoRA 将 LoRA 与 4 位量化相结合,进一步减少了内存使用量。它将预训练的模型权重量化为 4 位精度,仅保持 LoRA 参数的全精度。这允许在有限的硬件上训练更大的模型。
6.3 冻结视觉编码器
对于主要关注使用视觉输入进行语言处理的任务,请考虑冻结视觉编码器 (SigLIP) 的权重。这可以防止视觉编码器的权重在训练期间更新,从而减少可训练参数的数量和内存需求。
7、加载预训练 PaliGemma 2 模型
在继续之前,请确保你已通过运行以下命令安装了必要的库:
pip install -q peft bitsandbytes transformers>=4.47.0现在,让我们使用以下代码加载模型:
import torch
from peft import get_peft_model, LoraConfig
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration, BitsAndBytesConfig
MODEL_ID ="google/paligemma2-3b-pt-224"
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
processor = PaliGemmaProcessor.from_pretrained(MODEL_ID)
if USE_LORA or USE_QLORA:
lora_config = LoraConfig(
r=8,
target_modules=[
"q_proj",
"o_proj",
"k_proj",
"v_proj",
"gate_proj",
"up_proj",
"down_proj"
],
task_type="CAUSAL_LM",
)
if USE_QLORA:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_type=torch.bfloat16
)
model = PaliGemmaForConditionalGeneration.from_pretrained(
MODEL_ID,
device_map="auto",
quantization_config=bnb_config if USE_QLORA else None,
torch_dtype=torch.bfloat16)
model = get_peft_model(model, lora_config)
model = model.to(DEVICE)
model.print_trainable_parameters()
else:
model = PaliGemmaForConditionalGeneration.from_pretrained(
MODEL_ID, device_map="auto").to(DEVICE)
model = model.to(DEVICE)
if FREEZE_VISION:
for param in model.vision_tower.parameters():
param.requires_grad = False
for param in model.multi_modal_projector.parameters():
param.requires_grad = False
TORCH_DTYPE = model.dtype8、训练 PaliGemma 2 模型
现在我们已经准备好数据集并加载了预先训练的 PaliGemma 2 模型,是时候针对我们的任务对其进行微调了。首先,我们定义一个 collate_fn 函数来处理数据,然后再将其输入到模型中:
from transformers import Trainer, TrainingArguments
def collate_fn(batch):
images, labels = zip(*batch)
paths = [label["image"] for label in labels]
prefixes = ["<image>" + label["prefix"] for label in labels]
suffixes = [label["suffix"] for label in labels]
inputs = processor(
text=prefixes,
images=images,
return_tensors="pt",
suffix=suffixes,
padding="longest"
).to(TORCH_DTYPE).to(DEVICE)
return inputs此函数获取一批 (image, label) 对,并以 PaliGemma 2 所需的格式准备输入。这包括将 前缀添加到文本提示和填充序列,以确保批次内的长度一致。
接下来,我们定义训练参数:
args = TrainingArguments(
num_train_epochs=3,
remove_unused_columns=False,
per_device_train_batch_size=3,
gradient_accumulation_steps=16,
warmup_steps=2,
learning_rate=5e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=200,
optim="paged_adamw_8bit" if USE_QLORA else "adamw_hf",
save_strategy="steps",
save_steps=1000,
save_total_limit=1,
output_dir="paligemma2_json_extraction",
bf16=True,
report_to=["tensorboard"],
dataloader_pin_memory=False
)以下是一些关键参数超参数:
num_train_epochs:模型将在整个训练数据集上迭代的次数。增加此值可能会提高性能,但也会增加训练时间并可能导致过度拟合。per_device_train_batch_size:每个设备上每次迭代中使用的训练示例数量。增加此值可以提高训练速度和稳定性,但需要更多内存。gradient_accumulation_steps:在执行权重更新之前累积梯度的步骤数。这有效地增加了批次大小而不需要更多内存。增加此值可以提高批次大小较小的稳定性,但可能会减慢训练速度。learning_rate:控制优化期间采取的步长。增加此值可能会加快学习速度,但可能导致不稳定或超出最佳解决方案。weight_decay:一种正则化技术,通过向模型的权重添加惩罚来防止过度拟合。增加此值有助于防止过度拟合,但也可能限制模型学习复杂模式的能力。
最后,我们创建一个 Trainer 实例并开始训练过程:
trainer = Trainer(
model=model,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
data_collator=collate_fn,
args=args
)
trainer.train()这将在提供的数据集上微调我们的 PaliGemma 2 模型。请记住监控训练过程并根据需要调整超参数以实现最佳性能。
9、使用微调的 PaliGemma 2 模型运行推理
完成训练过程后,我们可以使用微调的 PaliGemma 2 模型对新图像进行预测。
image, label = test_dataset[0]
prefix = "<image>" + label["prefix"]
suffix = label["suffix"]
inputs = processor(
text=prefix,
images=image,
return_tensors="pt"
).to(TORCH_DTYPE).to(DEVICE)
# Calculate the length of the input sequence
prefix_length = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(
**inputs, max_new_tokens=256, do_sample=False, num_beams=3)
# Extract only the generated tokens by slicing the sequence
generation = generation[0][prefix_length:]
generated_text = processor.decode(
generation, skip_special_tokens=True)此代码片段从测试中获取图像及其对应的标签数据集。然后,它通过添加 前缀并使用处理器对其进行编码来为模型准备输入。
然后, model.generate() 函数生成一个 token ID 序列。此序列包含输入 token 和生成 token 的 ID。要仅获取生成的输出,我们需要删除
输入标记 ID。我们通过从 prefix_length 开始对生成张量进行切片来实现这一点 — 这样,我们删除输入 ID 并仅保留生成的 ID。
最后,我们使用处理器将这些生成的标记 ID 解码为文本,从而给出模型的预测。

你可以将生成的文本与后缀(基本事实)进行比较,以评估预测的质量。对于此比较,你可以使用 BLEU 分数、ROUGE 分数或 METEOR 分数等指标来衡量生成的文本与基本事实之间的相似性。可视化图像和预测输出也有助于更好地了解模型的性能。
10、结束语
本教程提供了有关微调 PaliGemma 2 以从图像中提取 JSON 数据的全面指南。我们解决了关键步骤,包括 JSONL 格式的数据集准备、使用 LoRA 和 QLoRA 等技术进行高效模型加载以及训练过程。
PaliGemma 2 的架构将视觉编码器与语言模型相结合,可通过微调适应各种任务。各种模型大小和分辨率的可用性允许选择平衡性能和计算约束的检查点。
原文链接:How to Fine-tune PaliGemma 2
汇智网翻译整理,转载请标明出处
