Phi-4:微软的小模型旗舰
在Phi家族成功的基础上,微软推出了Phi-4-Mini和Phi-4-Multimodal,扩展了它们处理视觉和音频模态的能力。

Phi-4系列代表了小型语言模型(SLMs)的重要进步,表明精心策划和合成的数据可以使参数较少的模型表现出高度竞争力。在Phi家族成功的基础上,微软推出了Phi-4-Mini和Phi-4-Multimodal,扩展了它们处理视觉和音频模态的能力。Phi-4-Mini是一款38亿参数的语言模型,擅长多语言支持、推理和数学,并具有功能调用的功能。Phi-4-Multimodal是一种多模态模型,集成了文本、视觉和语音/音频输入。这些模型可以在边缘设备上部署,使资源受限环境中的生成式AI成为可能。
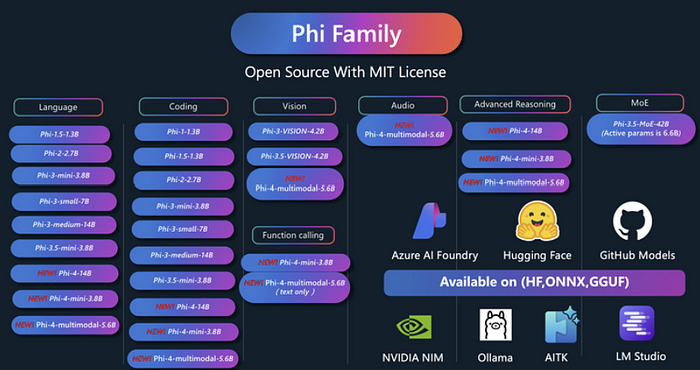
1、关键能力
Phi-4-Mini:
- 增强的多语言支持:Phi-4-Mini具有200K令牌的扩展词汇量,以更好地支持多语言应用。
- 推理和数学:该模型展示了强大的推理和数学能力,超越了相似规模的开源模型,并与规模为其两倍的模型性能相当。
- 功能调用:Phi-4-Mini支持功能调用,通过集成搜索引擎和连接各种工具来扩展其文本处理能力。
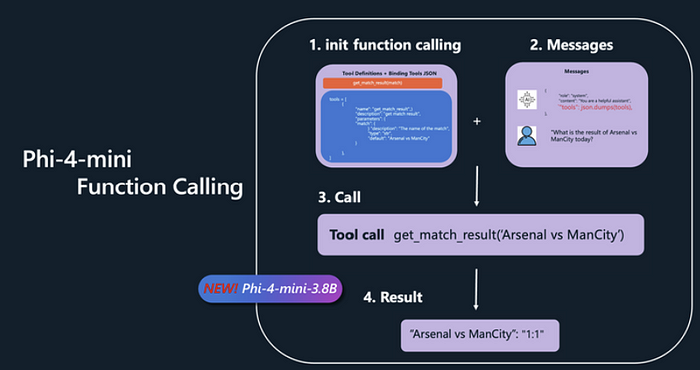
Phi-4-Multimodal:
- 统一的多模态支持:Phi-4-Multimodal在一个单一模型检查点中高效地处理多种模态(文本、图像、语音/音频)。
- 视觉和语言理解:该模型在视觉-语言理解方面有显著改进,超过了之前的模型,并且在相似规模的基线模型中表现出色。它在图表理解和科学推理任务中表现优异。
- 语音和音频性能:Phi-4-Multimodal在多语言语音识别和翻译任务中表现出色,并且是第一个具有语音摘要功能的开源模型。它在专家ASR模型上超越了专家,并在语音摘要任务中与更大的模型相比表现出竞争力。
- 高级推理:即使参数减少,仍保持较强的推理能力。可以根据图像内容和提示生成结构化的项目代码。
2、模型架构
2.1 语言模型架构
Phi-4-Mini和Phi-4-Multimodal共享相同的语言模型骨干,包括32个Transformer层和3,072的隐藏状态大小。模型使用tiktoken分词器,词汇量为200,064,支持多语言和多模态输入输出。架构基于解码器-only的Transformer,并支持基于LongRoPE的128K上下文长度。主要架构特点包括:
- 分组查询注意力(GQA):优化了长上下文生成的键和值内存(KV缓存)使用。模型采用24个查询头和8个键/值头,将KV缓存消耗减少到标准大小的三分之一。
- 分数RoPE维度:确保25%的注意力头维度保持位置无关性,支持更平滑地处理较长上下文。
2.2 多模态架构
Phi-4-Multimodal采用了新颖的“LoRA混合”技术,在保持基础语言模型完全冻结的同时整合了特定模态的LoRA。这种方法允许在不干扰的情况下组合多种模态的不同推断模式。架构包括:
- 视觉模态:
- 预训练的视觉编码器处理图像输入。
- 视觉投影器(2层MLP)将视觉特征映射到文本嵌入维度。
- 在语言解码器的所有线性层中添加LoRA适配器,并在监督微调(SFT)阶段进行部署。
- 语音和音频模态:
- 预训练的音频编码器由卷积层和Conformer块组成。
- 音频投影器(2层MLP)将语音特征映射到文本嵌入空间。
- 在Phi-4-Mini的所有注意力和MLP层中应用LoRA,以提高语音/音频基准性能,同时保留文本能力。
3、创新
3.1 LoRA混合
“LoRA混合”技术是Phi-4-Multimodal的一个关键创新。不同的LoRA被训练以处理不同模态之间的交互。这种方法使多模态能力成为可能,同时最小化模态之间的干扰。设计高度可扩展,允许无缝集成新的LoRA以支持额外的模态而不影响现有的模态。
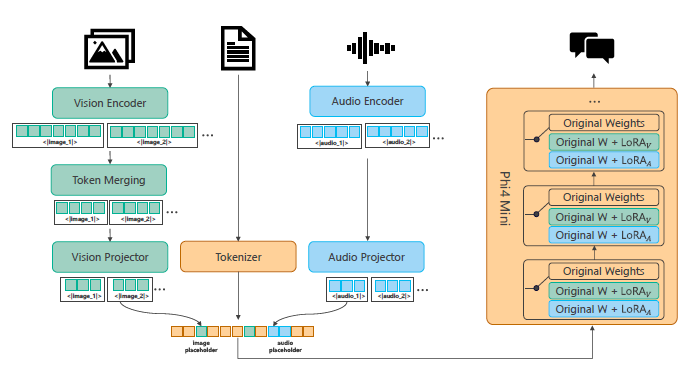
3.2 训练数据和方法
- 高质量数据:Phi-4-Mini和Phi-4-Multimodal都在高质量网络和合成数据上进行了训练。合成数据配方特别强调高质量的数学和编码数据集,用于Phi-4-Mini。
- 数据过滤:使用改进的数据过滤技术来增强预训练数据的质量。使用更大精心策划的数据集训练的增强质量分类器在多种语言中提高了过滤质量。
推理训练:推理优化版的Phi-4-Mini经过三阶段的训练过程:
- 在广泛的推理数据上进行预训练。
- 在一个较小的、精心策划的数据集上进行微调。
- 使用偏好样本进行DPO训练。
3.3 训练流水线
多模态训练流水线包括视觉训练、语音/音频训练和视觉-语音联合训练。
- 视觉训练:涉及交错的图文文档预训练和SFT,使用文本SFT数据集和多模态指令调优数据集的组合。
- 语音和音频训练:分为两个阶段,首先使用ASR数据对齐音频编码器和Phi-4-Mini进行预训练,然后使用精心策划的语音和音频SFT样本进行后训练。
- 视觉-语音联合训练:涉及视觉适配器LoRA、视觉编码器和视觉投影器的微调,同时冻结语言基础模型、音频编码器和音频投影器。
4、性能
4.1 语言基准
Phi-4-Mini在不同的语言理解基准测试中表现出色,超越了相似规模的模型,并且在数学和推理相关基准测试中表现出色。
4.2 编码基准
Phi-4-Mini在各种编码基准测试中表现出色,超越了大多数3B和8B模型。
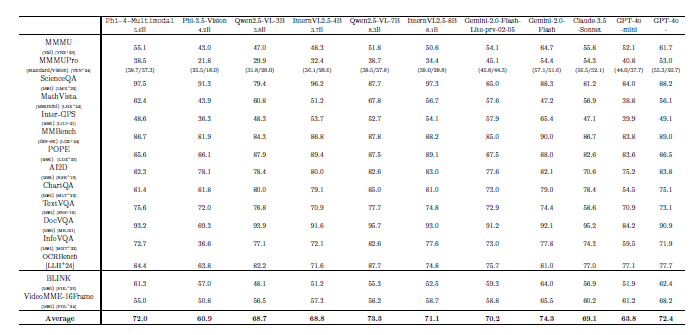
4.3 多模态基准
- 视觉-语言:Phi-4-Multimodal在视觉-语言基准测试中比之前的模型有了显著改进,并且在相似规模的基线模型中表现出色。在图表理解和科学推理任务中,它甚至超过了某些闭源模型。
- 视觉-语音:Phi-4-Multimodal在视觉-语音基准测试中显著优于InternOmni和Gemini-2.0-Flash。
- 语音和音频:Phi-4-Multimodal在ASR和AST性能上表现出色,超越了专家模型。它是第一个具有语音摘要功能的开源模型。
5、安全性
Phi-4-Mini和Phi-4-Multimodal的开发遵循了微软负责任的人工智能原则。方法包括在训练后的安全对齐、红队测试和自动化测试。使用微软Azure AI评估SDK进行了系统性的安全性评估。模型对越狱具有鲁棒性,并且能够有效地拒绝有害提示。
6、弱点和局限性
- 模型大小:模型的大小限制了其记住具体事实的能力。
- 多语言能力: 多语言能力受限于模型参数的数量。
- 潜在的不当内容: 与其他模型一样,Phi-4-Mini 和 Phi-4-Multimodal 有时可能会输出不当内容。
- 不适合用于生物特征分类: Phi-4-Multimodal 不适合用作生物特征分类系统。
7、结束语
Phi-4-Mini 和 Phi-4-Multimodal 在小型语言模型中代表了显著的进步,展示了精心策划的数据和创新架构设计的潜力。凭借强大的语言理解、推理、编码和多模态处理能力,这些模型为各种应用提供了有吸引力的解决方案,特别是在资源受限的环境中。
"LoRA 混合"技术以及对高质量训练数据的重视是提高 Phi-4 系列性能和多功能性的关键创新。这些模型与负责任的人工智能原则高度一致,纳入了安全措施以减轻潜在风险。随着 SLM 的不断发展,Phi-4 系列体现了在有限资源下实现高性能时数据质量、架构创新和安全考虑的重要性。
原文链接:Small and Cool: Inside Microsoft’s New Phi-4-Mini and Phi-4-Multimodal
汇智网翻译整理,转载请标明出处
