Phi-4-Resoning
微软Phi-4推出了三款新的开放权重模型,专为处理严肃的推理任务而设计。

又一周,又一个推理LLM发布——但这次来自微软,而且非常棒。 在本周已经发布了Qwen3和DeepSeek-Prover-V2之后,微软推出了三款新的开放权重模型,专为处理严肃的推理任务而设计。
无论你是解决高中代数问题、应对3SAT挑战,还是构建不会中途产生幻觉的代理,Phi-4推理可能就是你的新最佳伙伴。
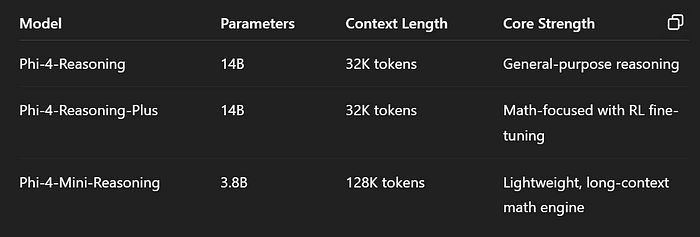
团队发布了三个模型:Phi-4推理、Phi-4推理增强版和Phi-4迷你推理。
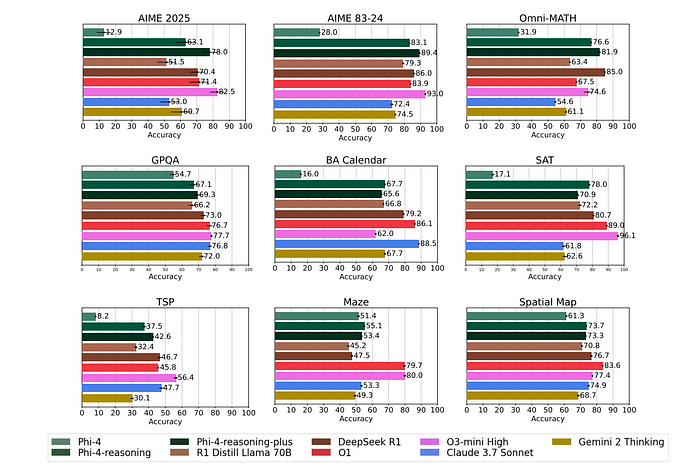

1、模型系列
1.1 Phi-4-Reasoning:基础野兽
这是一个坚实的整体选手。可以把它想象成是基于Phi-4模型的加强版。
- 训练数据:140万高质量STEM提示词,带有详细的推理跟踪(感谢o3-mini)。
酷炫技巧:
- 使用自定义的
<think>标签来组织逻辑块。 - 上下文窗口从16K扩展到32K令牌。
性能:
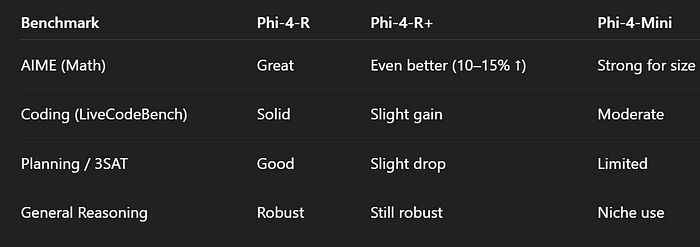
- 超过了DeepSeek-R1-Distill(70B!)等模型。
- 数学、编码和规划任务表现令人惊讶地好。
简而言之:如果你想获得通用推理且性能稳定,从这里开始
1.2 Phi-4-Reasoning-Plus:数学专家
现在我们用强化学习来提升性能。
- 新增内容:使用6K精心挑选的数学问题进行微调。
- 奖励系统:鼓励准确性,避免啰嗦。想想:“要聪明,不要废话。”
性能提升:
- AIME和OmniMath准确率提高10–15%。
- 更长的推理跟踪=更深的洞察力(以推理时间增加为代价)。
简而言之:如果你的生活围绕着数学问题或竞争性基准,这个就是你的MVP。
1.3 Phi-4-Mini-Reasoning:小巨人
小巧、灵活、出人意料的强大——就像蚁人,但用于逻辑。
- 大小:仅3.8B参数,却支持128K令牌上下文长度。
- 训练数据:来自更强大教师模型的合成数学数据。
- 专业化:逐步逻辑,适合移动或边缘场景。
⚠ 注意事项:
- 不是通用模型——在数学/逻辑之外的表现不佳。
- 可能会因为较小的规模而产生事实幻觉(建议使用RAG)。
简而言之:非常适合轻量级数学任务,但不是下一个聊天机器人引擎。
2、如何使用Phi-4推理模型?
这些模型完全开源,并且权重可以在Hugging Face上获取。请查看这个链接。
下面的代码片段可用于本地加载模型
pip install flash_attn==2.7.4.post1 torch==2.5.1 transformers==4.51.3 accelerate==1.3.0
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-4-mini-reasoning"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [{
"role": "user",
"content": "如何解方程3*x^2+4*x+5=1?"
}]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
outputs = model.generate(
**inputs.to(model.device),
max_new_tokens=32768,
temperature=0.8,
top_p=0.95,
do_sample=True,
)
outputs = tokenizer.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])
print(outputs[0])
3、何时使用哪个模型?
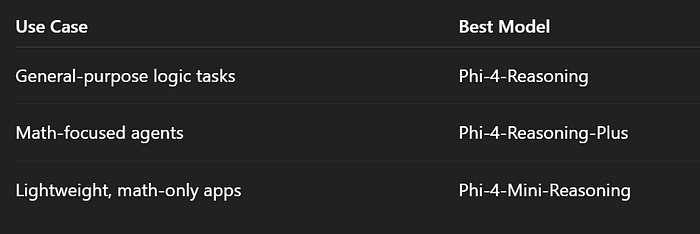
- 需要文档的长上下文吗? 迷你版有128K令牌。
- 需要在数学上达到最大准确性吗? 选择增强版。
- 只是想测试一下? 从基础模型开始。
4、最终想法
微软不仅仅是在追赶——他们在推理领域以精益、智能和令人耳目一新的开放姿态冲刺。
如果你正在构建自主代理、辅导系统,或者只是探索逻辑密集型LLMs,Phi-4推理模型绝对值得一试。记住:在高风险应用场景中,测试后再信任。
希望你能尝试新的推理模型!!!
原文链接:Phi-4-Reasoning: Microsoft’s new LLMs are Smarter, Faster, Free-er
汇智网翻译整理,转载请标明出处
