quick_sentiments 情感分析包
quick_sentiments在“后台”处理了文本清理、向量化和机器学习的所有复杂和耗时的任务,让你专注于结果,而不是样板代码。
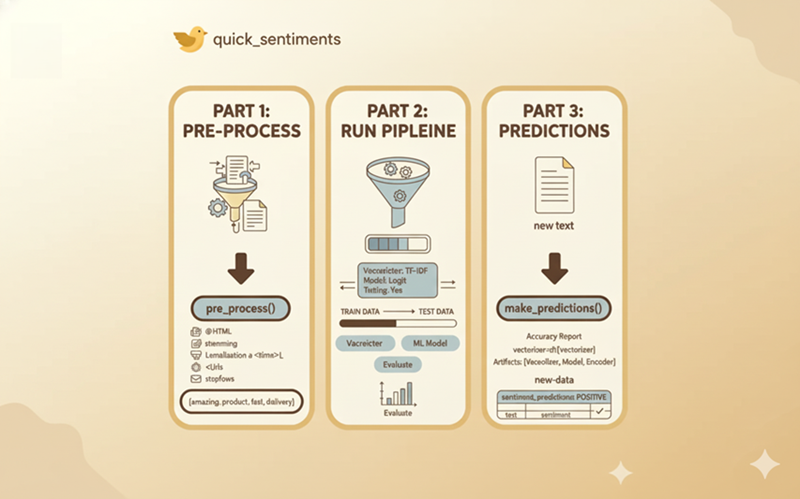
如果你能运行一个完整的端到端情感分析流程——从原始文本到最终预测——只需三个简单的步骤呢?这就是我设计新的Python包quick_sentiments所要解决的问题。它在“后台”处理了文本清理、向量化和机器学习的所有复杂和耗时的任务,让你专注于结果,而不是样板代码。
如果你从头开始构建了一个情感分析项目,你就会知道最初的障碍。你在处理nltk、scikit-learn和其他库的导入,同时希望库的更新不会破坏你的环境。
quick_sentiments就是为了解决这个问题而设计的。它抽象了设置过程,为你管理所有依赖项和复杂的函数调用。
你可以使用以下代码在Python中安装该包
!pip install quick-sentiments
#或者
git clone https://github.com/AlabhyaMe/quick_sentiments.gitp
1、预处理
现在,让我们进入第一步:预处理。在模型能够理解文本之前,必须对其进行清理。这是一个关键但繁琐的阶段,涉及一系列任务:删除HTML标签、去除表情符号和标点符号、处理停用词、词形还原以及标准化大小写。干净的文本是任何高质量向量化和最终准确模型的必要基础。
从示例中可以看出,使用pre_process函数非常简单。
import polars as pl
#从quick_sentiments导入pre_process
from quick_sentiments import pre_process
df_train = pl.read_csv("yourpath.csv",encoding='ISO-8859-1')
response_column = "reviewText"
sentiment_column = "sentiment"
#使用pre_process
df_train = df_train.with_columns(
pl.col(response_column).map_elements(lambda x: pre_process(x, remove_brackets=True)).alias("processed") #添加到map_elements内部
)
想想通常需要多少工作来从头开始清理文本。你需要导入re用于正则表达式处理URL,另一个正则表达式处理HTML标签,导入nltk下载并初始化停用词列表,另一个nltk模块用于词形还原……这是一长串繁琐的设置,你必须为每个项目编写。
quick_sentiments将整个过程浓缩成一个高度可配置的函数。看看你开箱即用的控制力:
def pre_process(doc,
remove_brackets=True,
remove_urls=True,
remove_html=True,
lemmatize=True,
remove_stop_words=True,
remove_nums=False,
... #还有许多其他选项
return_string=True):
#所有这些代码都在包内为您编写。
你也可以在这里查看代码 这里。
这个单一函数是一个完整的清理流程。在我们的polars示例中,我们使用了默认值,但特别设置了remove_brackets=True。如果您的特定任务需要保留数字怎么办?只需传递remove_nums=False。想要跳过词形还原步骤以加快速度吗?lemmatize=False。
从Unicode归一化和表情符号移除到分词和词形还原,pre_process在一个干净、简单的调用中处理整个清单。
现在,这个干净的、分词的字符串是进行下一步向量化的完美基础。
2、数据拆分、运行向量化、ML模型、准确性
现在我们进入了quick_sentiments包的强力部分。预处理之后,你会剩下机器学习的“中间混乱”:数据拆分、向量化、模型训练和评估。这是大多数项目变慢的地方,也是**run_pipeline()**接管的地方。
这个单一函数为你处理所有复杂性。关键的是,它在向量化之前执行训练/测试拆分,这是防止数据泄漏并获得模型性能可靠度的正确方法。
你只需要提供你的数据,命名你的列,并且——最重要的是——选择你的实验。
想测试经典的TF-IDF与逻辑回归吗?或者直接跳到100维GloVe嵌入与神经网络?或者进一步使用300维Word2Vec?你只需提出要求。
以下是预建并准备好通过名称调用的向量化方法和机器学习模型的完整列表:
- 向量化方法 (
vectorizer_name): "bow": 词袋"tf": 词频"tfidf": TF-IDF"wv": Word2Vec(在你的数据上训练)(如果没有的话会下载)"glove_25","glove_50","glove_100","glove_200": 不同维度的预训练GloVe嵌入- 机器学习模型 (
model_name): "logit": 逻辑回归"rf": 随机森林"xgb": XGBoost"nn": 简单的神经网络
所有这些功能都被封装在一个简单的函数调用中:
dt= run_pipeline(
vectorizer_name="glove_25", # BOW, tf, tfidf, wv, glove_25,glove_50, glove_100, gl0ve_200
model_name="logit", # logit, rf, XGB, nn
df=df_train,
text_column_name="processed", # 这是文本数据的列名,
sentiment_column_name = "sentiment",
perform_tuning = False # 如果你想进行超参数调整,请将其设为True,这会花费更长时间,并且如果数据集很大可能会超出内存限制,
)
在这里找到代码 这里。
#这是run_pipeline返回的内容。对于预测非常重要
return {
"model_object": trained_model_object,
"vectorizer_name": vectorizer_name,
"vectorizer_object": fitted_vectorizer_object,
"label_encoder": label_encoder,
"y_test": y_test,
"y_pred": y_pred,
"accuracy": accuracy_score(y_test, y_pred),
"report": classification_report(y_test, y_pred, output_dict=True, target_names=label_encoder.classes_)
}
run_pipeline的另一个关键特性不仅仅是它做了什么,而是它返回给你的内容。当函数完成时,它返回一个强大的Python字典,包含你所有的训练“工件”。
这意味着拟合的向量化器、训练好的模型、标签编码器,甚至列名都被打包并返回。这非常重要,因为这是你刚刚训练的“大脑”,被保存在一个盒子里,准备好用于新的、未见过的数据。
此时,我们的核心情感分析工作流程仅用两个函数就完成了。通过pre_process和run_pipeline,我们成功地对初始数据集进行了清理、向量化、训练和评估。
但是,如何对完全新的数据进行预测呢?这就是quick_sentiments让下一步变得容易的地方。当然,你需要将你的新原始文本通过相同的pre_process函数,但不需要重新训练任何东西。“artifact”对象由run_pipeline返回,包含了你需要的所有拟合组件,可以立即应用正确的向量化和模型到你的新数据,确保整个过程从开始到结束的一致性。
3、回报——对新的、未见过的数据进行预测
#对新数据进行预处理
new_data = new_data.with_columns(
pl.col(response_column).map_elements(lambda x: pre_process(x, remove_brackets=True)).alias("processed") #添加到map_elements内部
)
我们成功地在数据集上训练并评估了一个模型,我们的run_pipeline()函数返回了一个Python字典(我们将其保存为dt),其中包含了我们所有的训练“工件”。
现在,是时候将训练好的“大脑”应用于全新的现实世界数据了。
这是最后一步,quick_sentiments让它和前两步一样简单。在你将新的原始文本通过相同的pre_process()函数后(确保清理相同),你就可以使用最后一行命令:
# 'dt'对象是从我们的run_pipeline()调用返回的字典
predictions_df = make_predictions(
new_data=new_data,
text_column_name="processed",
vectorizer=dt["vectorizer_object"],
best_model=dt["model_object"],
label_encoder=dt["label_encoder"],
prediction_column_name="sentiment_predictions" #你可以为输出列命名
)
“后台”发生了什么
这个make_predictions()调用是管道真正力量的体现。让我们看一下参数,了解为什么如此可靠:
vectorizer=dt["vectorizer_object"]: 你正在传入实际拟合的向量化器,它是在你的数据上训练的。best_model=dt["model_object"]: 你正在传入实际训练好的模型。label_encoder=dt["label_encoder"]: 你正在传入拟合的标签编码器,以正确地将输出映射回你的原始标签(例如,“正面”,“负面”)。
这种设计避免了编写所有重复的向量化和预测代码。但更重要的是,它消除了机器学习中最常见和最危险的错误。
如何做到这一点?通过传入“拟合的工件”,你不可能犯错。你不用担心:
- “我是否不小心在新数据上重新拟合了我的向量化器?”
- “我是否使用了与训练数据相同的
ngram_range和max_features?” - “我是否使用了具有最佳超参数的模型,还是只是默认的那些?”
make_predictions()函数保证你的新数据通过与原始训练数据相同的、一致的流程进行处理。在这里出错的风险被消除,因为所有复杂的工作都为你在“后台”完成了。
就这样,你得到了一个新的数据框,有一个新的预测列。仅通过三个主要步骤——pre_process()、run_pipeline()和make_predictions()——我们就完成了从原始文本到真实世界、可靠的预测的整个情感分析旅程。
原文链接:Sentiment Analysis In 3 steps: Using quick_sentiments in Python
汇智网翻译整理,转载请标明出处
